






传统的图像分类任务只是期望模型可以预测未见过图像的类别,而零样本学习则旨在预测从未见过的类别。对于原始图像分类任务来说,为每个类别收集大量训练数据对于最终拥有一个稳健的模型非常重要。然而,要获得大量的标注数据并不总是那么容易。例如,你可能想训练一个分类器来识别一种非常罕见的野生动物。在这种情况下,为这类生物收集大量视觉数据可能并不容易。但是,通过零样本学习,模型可以使用新物种的描述或属性(如栖息地、物理特征和行为)对其进行正确分类,即使它以前从未见过这种物种。
另一方面,有时标注过程的成本很高。在某些情况下,区分类别的关键特征可能非常复杂,只有一些领域专家才知道。同样,在这种情况下,拥有大量标注数据并不容易。零样本学习可以使模型将现有类别中的知识归纳到新的、未标记的类别中,从而减少对此类大量数据集的依赖。
应用零样本学习
在零样本学习中,数据被分为三大类:
-
Seen Classes: 用于训练模型的类别。
-
Unseen Classes: 未知类别,模型需要能够在没有任何特定训练的情况下进行分类的类别。在训练过程中没有使用这些类别的数据。
-
Auxiliary Information:辅助信息;由 Word2Vec 等技术提供的关于所有未见类别的描述、语义信息或嵌入向量。这对于解决 "零样本学习"问题十分必要,因为我们没有未知类别的标注示例。
零样本学习包括训练和推理两个步骤。在训练过程中,模型学习已标注好的数据样本集。在推理过程中,模型利用这些知识和辅助信息对一组新的类别进行分类。
训练阶段非常简单:我们使用ImageNet等通用数据集来训练分类模型,其中包括我们已知类别的样本。如前所述,我们没有任何未知类别的图像样本。此时,我们利用辅助信息来表示未见类别。
使用 Word2Vec 向量来表示类别嵌入是一种合适的方法。在 Word2Vec向量空间中,用两个向量表示的两个词在同一文档中经常出现或具有语义关系,那么这两个向量的位置就很可能很接近。
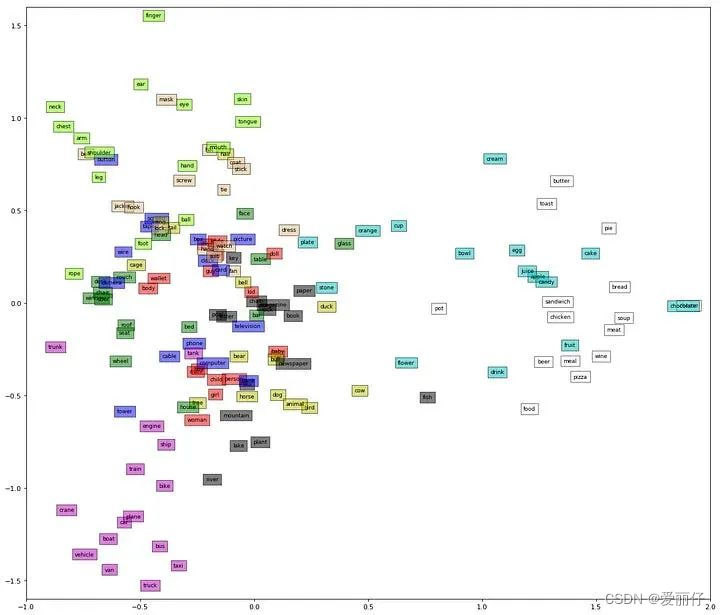
最后,我们要做的就是:我们将使用图像嵌入(图像特征向量)及其相关类别单词嵌入(单词 Word2Vec)来训练。这样,网络基本上就能学会如何将给定的输入图像映射到 Word2Vec 空间中的向量上。训练完成后,当网络获得属于零样本类别的物体图像时,网络就能提取一个向量作为输出。然后,通过使用该输出向量(测量其与我们拥有的所有类别向量(包括训练样本和零样本数据)的距离),我们就能对其进行分类。
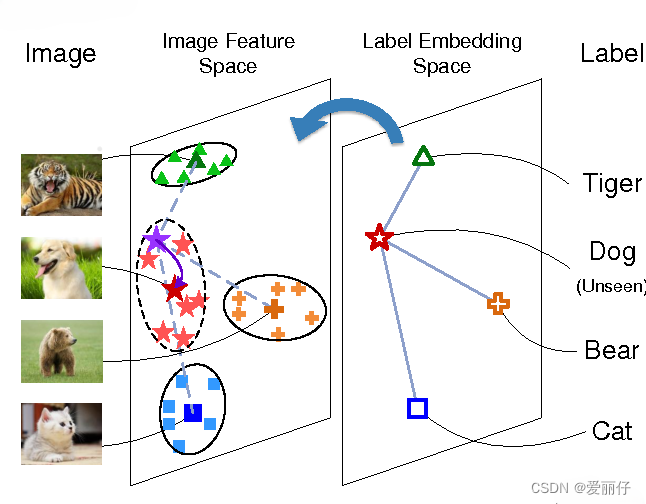
简而言之,创建零样本学习分类器就是简单地学习从未知空间(用于图像识别的视觉特征)到已知空间(文本特征或其他类型的辅助信息)的映射函数。整个过程如上图所示。即使没有 "Dog"类别的标注训练样本,在推理过程中向网络提供 "Dog"类别的测试图像时,它也会在类别嵌入空间中被映射到相对接近于 "Dog"类的向量。最终,通过计算预测向量与所有标签向量的距离,网络将能够正确地对模型在训练过程中从未展示过的 "Dog"类测试图像进行分类。


















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











