






Doris聚合多维分析:让你的数据会"说话",让数据更懂业务的艺术
在数智时代,企业正在面临一场数据处理的"魔方挑战"。就像解魔方需要同时考虑多个面的变化,数据分析也需要同时洞察多个维度的信息。
假如你是一位电商运营,既要关注销量走势,又要洞察用户行为,还要考虑地域差异…这就像是在玩一个复杂的数据魔方。传统的单维度分析就像只会转魔方的一个面,虽然那一面很完美,但整体却远未完成。
有趣的是,一位资深数据分析师曾经说过:"数据分析就像做菜,单一维度的数据是原料,多维分析技术是烹饪方法,而数据洞察则是最终的美味。"如何将这道"数据大餐"做得色香味俱全?让我们一起基于Doris揭开多维数据分析的艺术秘诀。

Doris多维分析:让你的数据会"说话"
互联网行业里流传着这样一句话:“数据分析就像是给企业装上了一双透视眼,而其维度层级决定视力好坏”。2024年,随着数字化转型的深入,企业对数据分析的需求越发迫切。传统的单维度分析已经无法满足复杂的业务场景,多维分析正成为数据分析的主流选择。
在电商领域,一个典型的数据分析需求是:统计2023年各季度、各产品类目、各地区的销售额。这看似简单的需求,背后涉及时间、类目、地区三个维度的交叉分析。如果用传统方法编写SQL,不仅代码冗长,性能也难以保证。
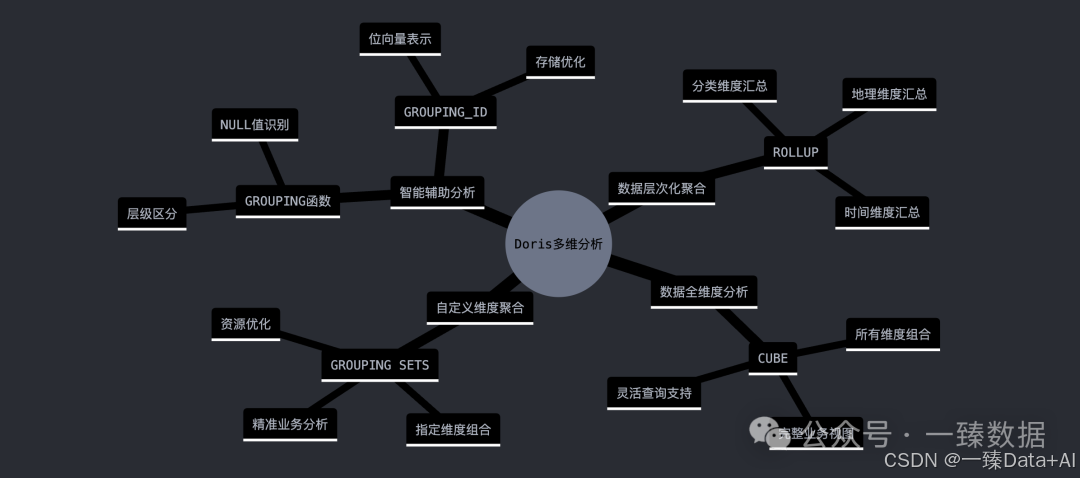
Doris作为新一代高性能MPP数据库,提供了强大的多维分析功能。通过ROLLUP、CUBE、GROUPING SETS等语法,轻松实现复杂的多维分析需求:
-
ROLLUP:ROLLUP 是一种用于生成层次化汇总的操作。它按照指定的列顺序进行汇总,从最细粒度的数据逐步汇总到最高层次。例如,在销售数据中,可以使用 ROLLUP 按地区、时间进行汇总,得到每个地区每个月的销售额、每个地区的总销售额以及整体总销售额。ROLLUP 适用于需要逐级汇总的场景。
-
CUBE:CUBE 是一种更为强大的聚合操作,它生成所有可能的汇总组合。与 ROLLUP 不同,CUBE 会计算所有维度的子集。例如,对于按产品和地区进行统计的销售数据,CUBE 会计算每个产品在每个地区的销售额、每个产品的总销售额、每个地区的总销售额以及整体总销售额。CUBE 适用于需要全面多维分析的场景,如业务分析和市场调查。
-
GROUPING SETS:GROUPING SETS 提供了对特定分组集进行聚合的灵活性。它允许用户指定一组列的组合进行独立聚合,而不是像 ROLLUP 和 CUBE 那样生成所有可能的组合。例如,可以定义按地区和时间的特定组合进行汇总,而不需要每个维度的所有组合。GROUPING SETS 适用于需要定制化汇总的场景,提供了灵活的聚合控制。
在双11大促中,某电商平台使用Doris的多维分析功能,快速洞察到"广东地区3C数码类目在10点档销售额激增"这一重要信息。运营团队及时调整投放策略,带来了显著的销售提升。这正是Doris多维分析的典型应用场景。
那么,Doris是如何支持高效的多维分析?
Doris的多维分析建立在三大核心技术之上:层次化聚合(ROLLUP)、全维度分析(CUBE)和自定义维度聚合(GROUPING SETS)。ROLLUP适合层级明确的数据,如时间、地区等;CUBE则提供全方位的数据视角;GROUPING SETS则让用户能够按需定制分析维度。
数据分析师小王遇到一个挑战:对销售额按照年月进行汇总分析。除了按照时间进行汇总,还需要分别计算了每年的销售额小计、每年中每月的销售额小计,以及总体的销售额总计。使用ROLLUP,他只需一行SQL就能得到结果:
SELECT
YEAR(d_date),
MONTH(d_date),
SUM(ss_net_paid) AS total_sum
FROM
store_sales,
date_dim d1
WHERE
d1.d_date_sk = ss_sold_date_sk
AND YEAR(d_date) IN (2001, 2002)
AND MONTH(d_date) IN (1, 2, 3)
GROUP BY
ROLLUP(YEAR(d_date), MONTH(d_date))
ORDER BY
YEAR(d_date), MONTH(d_date);
业务专家小李需要分析计算:
- 总计的销售额;
- 各年度的销售额小计、各类别下商品的销售额小计、各州的销售额小计;
- 每年每类产品的销售额小计、每个州每个产品的销售额小计、每年每个州的销售额小计和每年每个州各类别的产品的销售额小计。
使用CUBE,她直接单SQL获得了所有维度组合的汇总结果,发现了一些意想不到的业务洞察:
SELECT
YEAR(d_date),
i_category,
ca_state,
SUM(ss_net_paid) AS total_sum
FROM
store_sales,
date_dim d1,
item,
customer_address ca
WHERE
d1.d_date_sk = ss_sold_date_sk
AND i_item_sk = ss_item_sk
AND ss_addr_sk = ca_address_sk
AND i_category IN ("Books", "Electronics")
AND YEAR(d_date) IN (1998, 1999)
AND ca_state IN ("LA", "AK")
GROUP BY CUBE(YEAR(d_date), i_category, ca_state)
ORDER BY YEAR(d_date), i_category, ca_state;
运营总监张总关注重点业务指标:
- 每年度每类产品的销售额小计
- 每年度在每个州的销售额小计
- 每年度每个州每个产品的销售额小计
通过GROUPING SETS,她精确指定了需要关注的维度组合,既获得了所需信息,又避免了无用的计算开销:
SELECT
YEAR(d_date),
i_category,
ca_state,
SUM(ss_net_paid) AS total_sum
FROM
store_sales,
date_dim d1,
item,
customer_address ca
WHERE
d1.d_date_sk = ss_sold_date_sk
AND i_item_sk = ss_item_sk
AND ss_addr_sk = ca_address_sk
AND i_category IN ('Books', 'Electronics')
AND YEAR(d_date) IN (1998, 1999)
AND ca_state IN ('LA', 'AK')
GROUP BY GROUPING SETS(
(YEAR(d_date), i_category),
(YEAR(d_date), ca_state),
(YEAR(d_date), ca_state, i_category)
)
ORDER BY YEAR(d_date), i_category, ca_state;
Doris的多维分析不仅提供了强大的计算能力,还通过GROUPING等辅助函数,解决了NULL值识别、层级区分等实际问题。这些细节的优化,让数据分析变得更加智能和高效,让你的数据会"说话"。
多维分析实战:让数据更懂业务的艺术
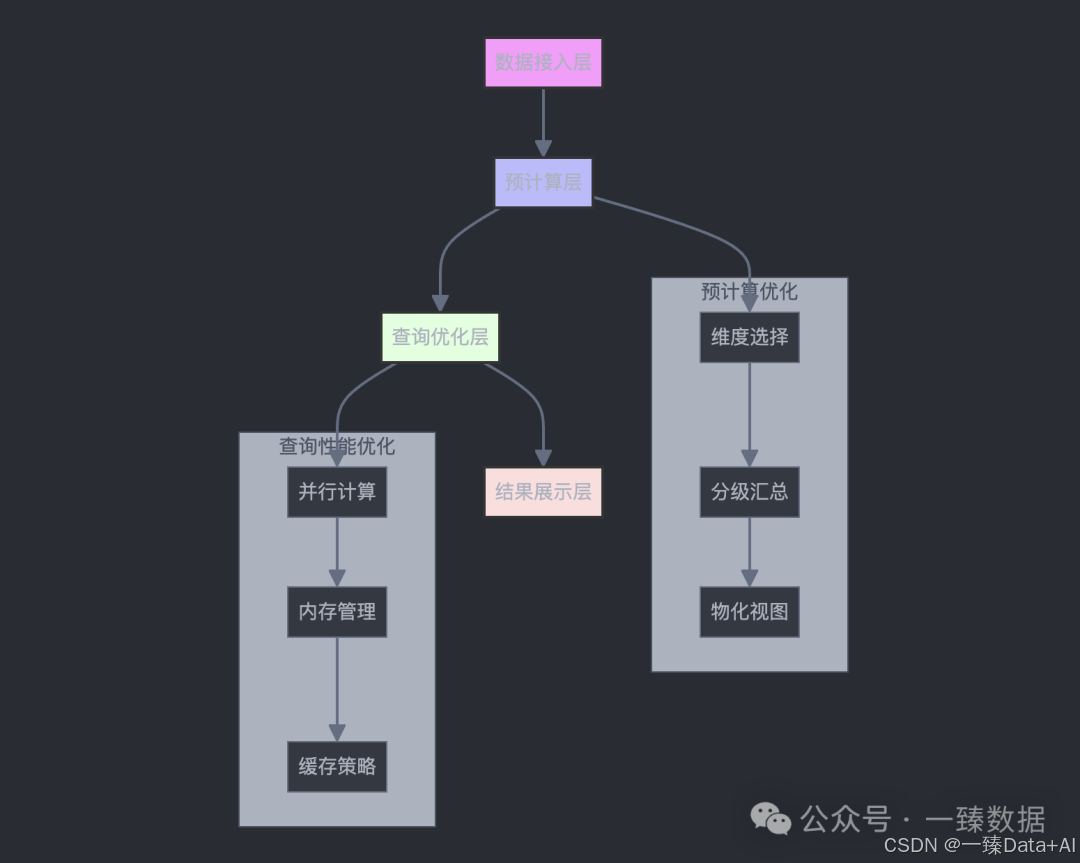
小张是某金融公司的数据分析师。每天早上,他都要生成一份用户交易分析报告。这份报告需要从用户、时间、产品、地区四个维度分析交易数据。起初,他写了四个单独的SQL查询,每次生成报告都要等待近20分钟。
"这样的效率太低了!"小张决定优化查询性能。通过研究Doris的多维分析特性,他发现了一个关键点:合理使用GROUPING_ID能显著提升查询效率。
SELECT
CASE
WHEN GROUPING_ID(user_level, time_month, region) = 0
THEN '详细数据'
WHEN GROUPING_ID(user_level, time_month, region) = 1
THEN '用户等级月度汇总'
ELSE '其他维度汇总'
END AS data_level,
user_level,
time_month,
region,
SUM(transaction_amount) as total_amount
FROM financial_transactions
GROUP BY CUBE(user_level, time_month, region)
HAVING GROUPING_ID(user_level, time_month, region) IN (0,1,3);
优化后的查询时间缩短到5分钟,效率提升了300%。更重要的是,输出结果更加清晰,便于业务人员理解。
除了查询优化,预计算也是提升多维分析性能的关键。产品经理老王发现一个问题:每次查看销售数据时,都要分别统计日、周、月三个维度的数据。这不仅耗时,还占用大量计算资源。
解决方案是使用ROLLUP预计算。创建包含多个层级的ROLLUP表:
ALTER TABLE sales_detail
ADD ROLLUP rollup_time_dimension(
time_date, product_id, region_code
);
这样,查询时就能直接使用预计算结果:
SELECT
time_date,
SUM(sales_amount) as daily_sales,
COUNT(DISTINCT user_id) as daily_users
FROM sales_detail
GROUP BY time_date
ORDER BY time_date DESC
LIMIT 7;
实践表明,合理使用这些技巧,能将复杂多维分析的响应时间控制在秒级。一位资深数据工程师说:“Doris的多维分析就像是给数据装上了加速器,让我们能更快地获取业务洞察。”
数据分析的价值在于转化为业务行动。营销团队利用优化后的多维分析系统,发现了一个有趣的现象:北京地区的年轻用户在周五晚上的购买力最强。这个发现直接指导了营销策略的调整,带来了显著的转化提升。
未来,Doris数据分析师将从繁琐的性能调优中解放出来,专注于业务价值的发现和应用!


















 1182
1182


 到【灌水乐园】发言
到【灌水乐园】发言








