







本文主要叙述的是如何获取搜狗微信的链接并转换成永久链
最近一直研究微信文章的爬取,这里是我总结的一些方法。
目前获得微信公众号文章最佳的路径就是搜狗微信,这大大减少了爬虫的工作量,但是搜狗微信上面的链接是临时的,需要我们去对链接进行转化,让然,如果只是获取一次文章,可以直接爬取,如果需要永久保存,就少不了对链接的转换。这边我提供两种方法。
对搜狗微信的分析
我们进入搜狗微信的主页查看源码发现有两个链接,
这里的链接是临时的,有效访问时间也就是几个小时的时间,

这里还有个分享链接,但是搜狗已取消了分享按钮,但是字段依然存在,

分享的链接的时效会久一点,但是也不是永久的,这个链接每次访问都会返回一个新的临时链接。
获取uin和key来转换永久链接
目前网上给的方案是通过这两个字段进行访问处理临时链接:
但uin和key又是什么?
uin:微信用户唯一标识。(这就意味着如果访问过于频繁可能被封号)
key:转换临时链接到永久链接的凭据,分为公众号key(仅对当前公众号下的文章有效),万能key(可用于任何公众号的转换),有效期约为40分钟~2小时。
通过fiddler我们可以抓取uin和key,但是这样的方法具有一定的局限性,不适合大规模的试用,如果只是学习可以尝试进行抓包处理。
这大大地加大了成本,所以并不推荐使用这种方法。
通过模拟浏览器然后安装插件获取永久链接
项目源码:https://github.com/yeyuzhao/weixin_article_spider,如果可以请帮我点个小星星。
- 我们先访问搜狗首页,分析各个类目的url规则,提取分享搜狗微信链接url。(目前各个类目只可以查看十四五页这样,比较具有局限性,如果进行搜索也只可以拿到前十页的数据)
- 然后根据获取到的url,进行浏览器模拟访问,加载西瓜插件,每次请求网页,西瓜插件都会返回永久链接。
在浏览器启动就加载插件:
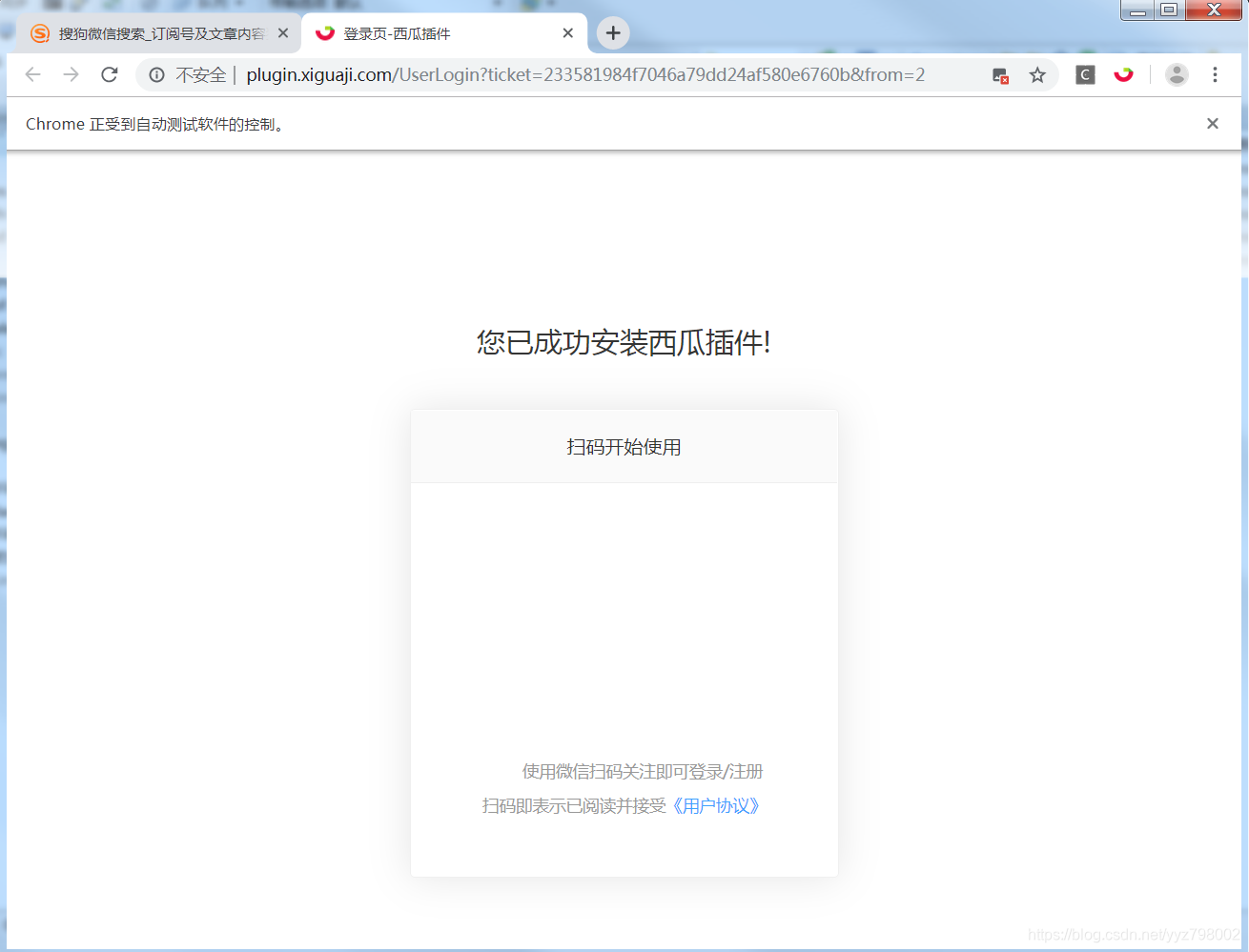
用抓取到的分享url进行访问: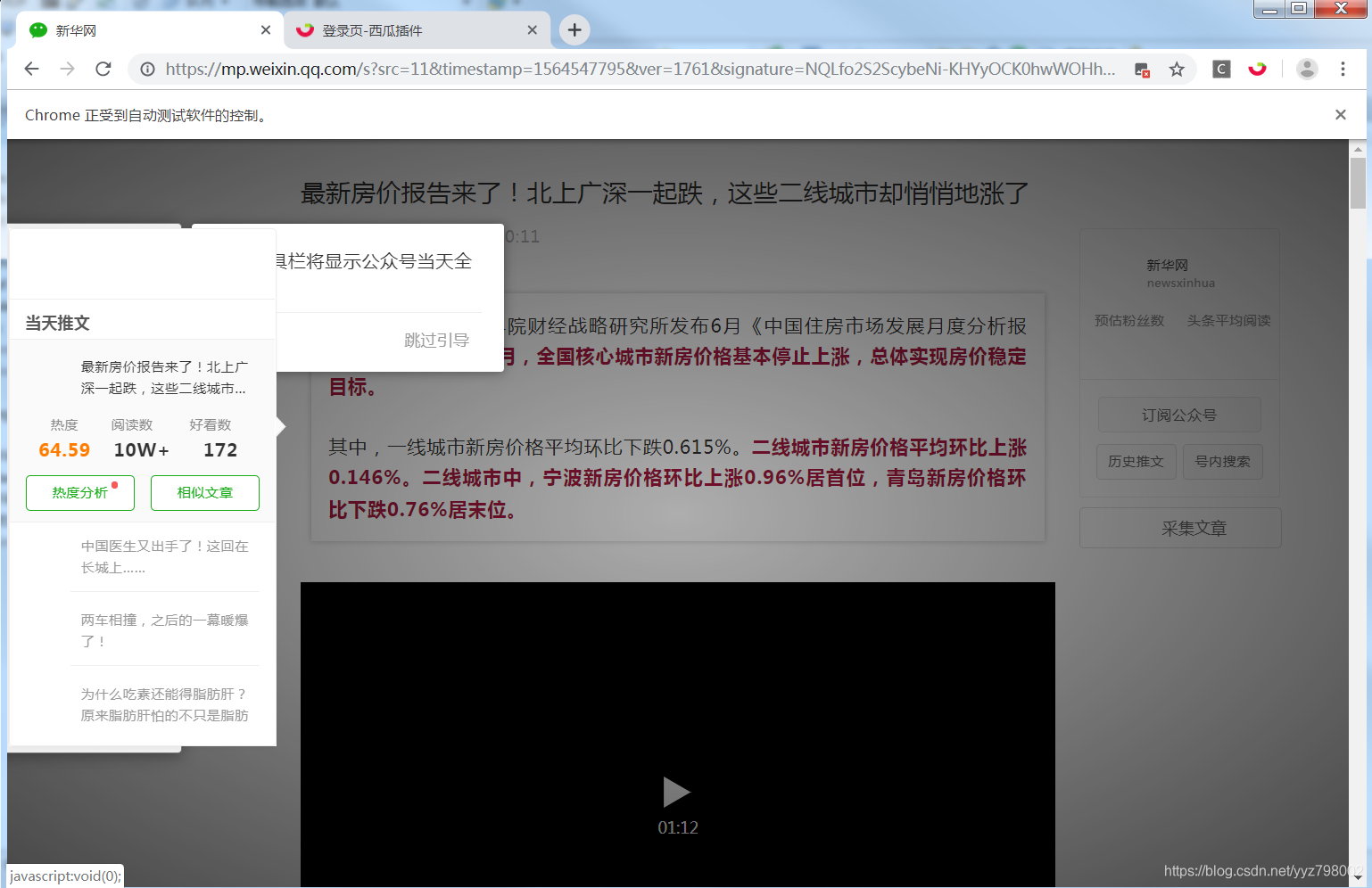
js的加载可能会有一定的延时,所以需要控制速度。通过左侧的插件我们可以发现除了阅读量还有热度分析和推荐文章查看源码我们可以发现

原链接是:http://weixin.sogou.com/api/share?timestamp=1564983001&signature=qIbwYnI6KU9tBso4VCd8lYSesxOYgLcHX5tlbqlMR8N6flDHs4LLcFgRw7FjTAOR9o10ANaKDMEchDmiGRDczmJWZPZyHi9AfJQ1KPvSpW04ymo38yYFtIonENAOsPjlGv9PJ4b90lCqeq5IFG803gviL5slc9F90OikALrf65S5C-yXnwBItTIOUuRm9E4Fjbox5zrNQLg0QpF1LE1GmsrSZ3SL5-0muXkNk=
微信永久链接(长链接):http://mp.weixin.qq.com/s?__biz=MzAxMDU0MDYwMQ==&mid=2653021489&idx=1&sn=09d858882e821b63368cd9b92ae83b7e&chksm=809b8667b7ec0f71242aeacbfadd8f7fb86acac058f3416b34d95b21549c5b1baaab4da3635e&scene=27#wechat_redirect
- 如果在搜狗微信里进行搜索,访问会出现ip报错,其实并不是真正的检测出ip问题,而是正常请求时他会触发一个js时间,然后组成一个新的url,我们请求的url是一个问题url,所以最佳的解决方案就是拿分享链接,进行访问,按上面的步骤提取出永久链接就ok了。
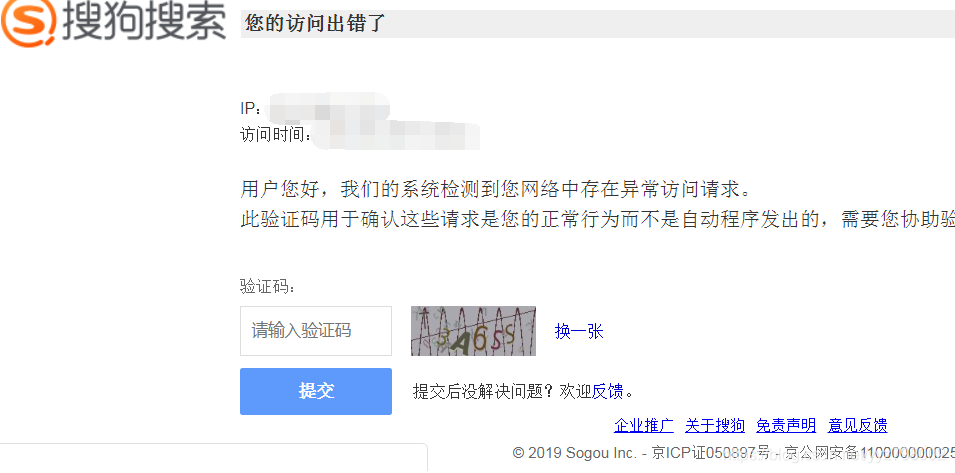
综上,就是处理搜狗微信文章链接的办法,感谢大家的阅读。
祝大家好运!

















 2774
2774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









