







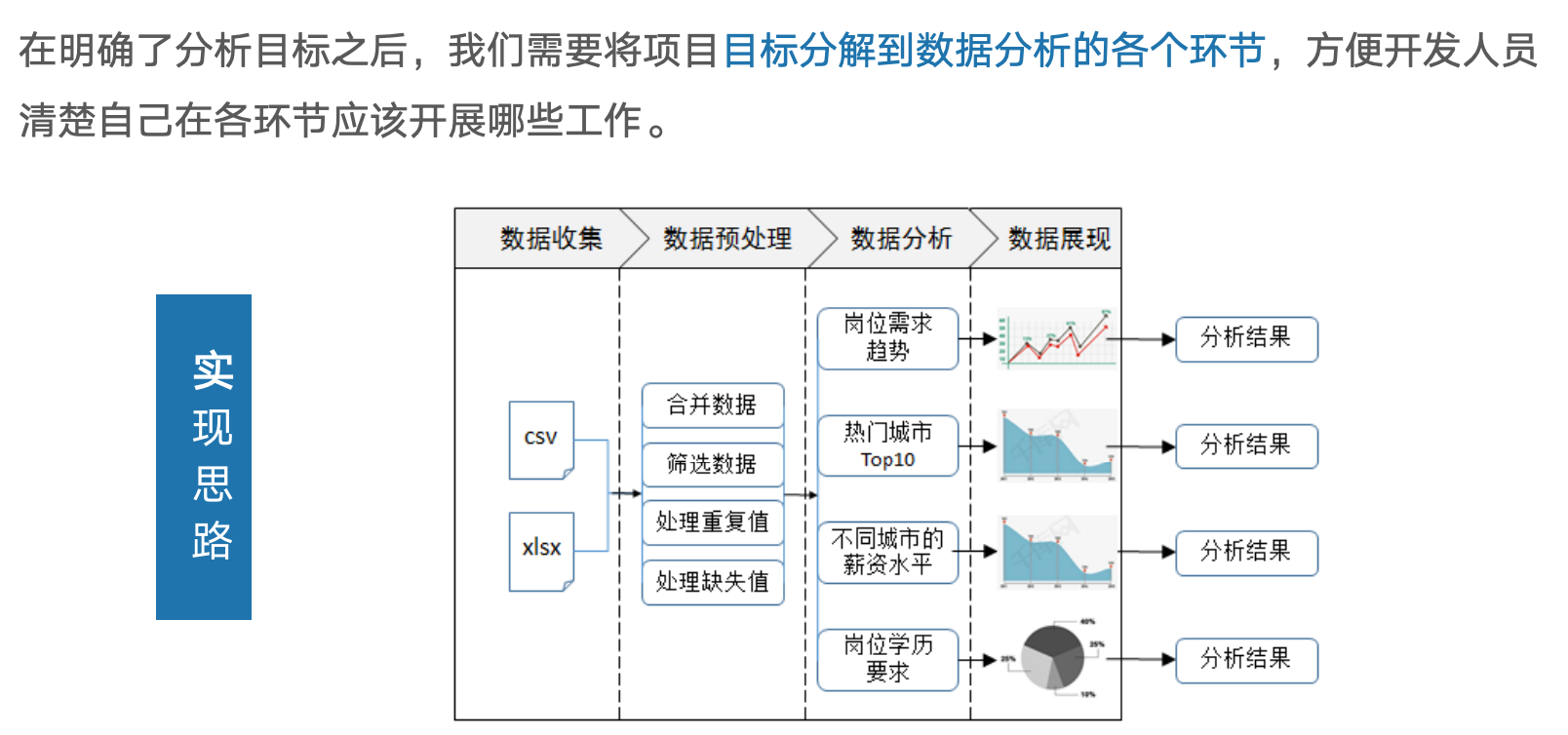
1.数据收集
import time
import pandas as pd
from pyecharts.charts import Bar, Line, Pie
from pyecharts import options as opts
from pyecharts.globals import SymbolType, ThemeType
# 读取lagou01.csv文件的数据
recruit_obj = pd.read_csv('lagou01.csv', encoding='gbk')
# 过滤与分析目标无关的数据,保留有关的数据
new_df_01 = pd.DataFrame([recruit_obj['city'],
recruit_obj['companyFullName'], recruit_obj['salary'],
recruit_obj['companySize'], recruit_obj['district'],
recruit_obj['education'], recruit_obj['firstType'],
recruit_obj['positionAdvantage'], recruit_obj['workYear'],
recruit_obj['createTime']]).T
new_df_01.head(5)

# 读取lagou02.xlsx文件的数据
recruit_obj2 = pd. read_excel('lagou02.xlsx')
new_df_02 = pd.DataFrame( [recruit_obj2['city'], recruit_obj2['companyFullName'], recruit_obj2['salary'],
recruit_obj2['companySize'], recruit_obj2['district'],
recruit_obj2['education'], recruit_obj2['firstType'],
recruit_obj2['positionAdvantage'], recruit_obj2['workYear'],
recruit_obj2['createTime']]).T
new_df_02.head(5)
new_df_01['createTime'] = pd.to_datetime(new_df_01['createTime'])
new_df_02['createTime'] = pd.to_datetime(new_df_02['createTime'])
new_df_02.head(5)

# 采用上下堆叠的方式合并数据
final_df = pd.concat([new_df_01, new_df_02], ignore_index=True)
# 给final_df重新设置列索引的名称
final_df = final_df.rename(columns={'city':'城市',
'companyFullName':'公司全称', 'salary':'薪资',
'companySize':'公司规模', 'district':'区', 'education':'学历',
'firstType':'第一类型', 'positionAdvantage':'职位优势',
'workYear':'工作经验', 'createTime':'发布时间'})
final_df.head(5)

2.数据预处理
# 查看整租数据的信息
final_df.info()

# 检测重复值
final_df[final_df.isna().values==True]
final_df = final_df.drop_duplicates()
final_df
# 检测缺失值
final_df[final_df.isna().values==True]
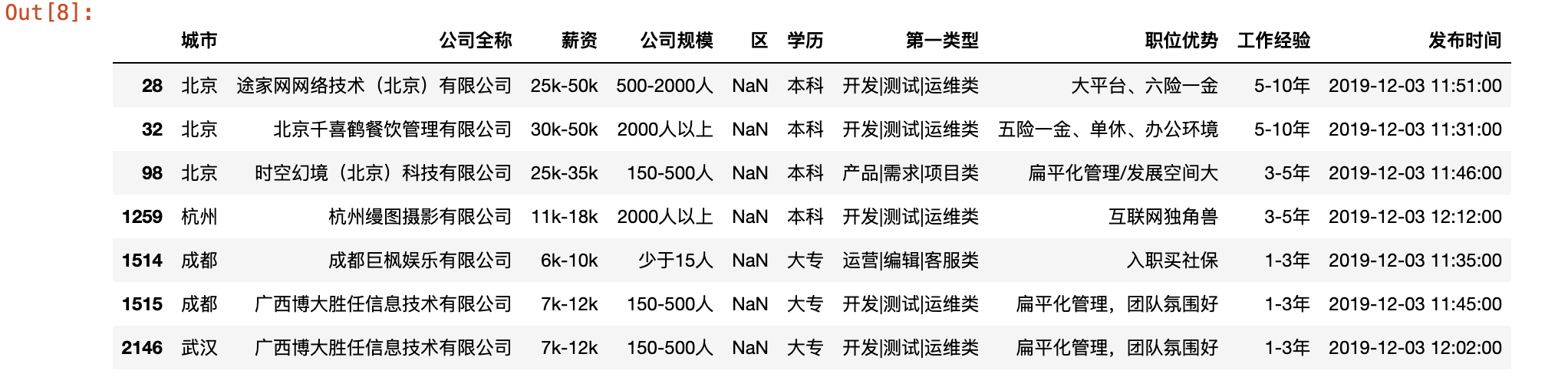
# 填充一个指定的值
final_df = final_df.fillna('未知')
final_df.loc[28]

3.数据分析与展现
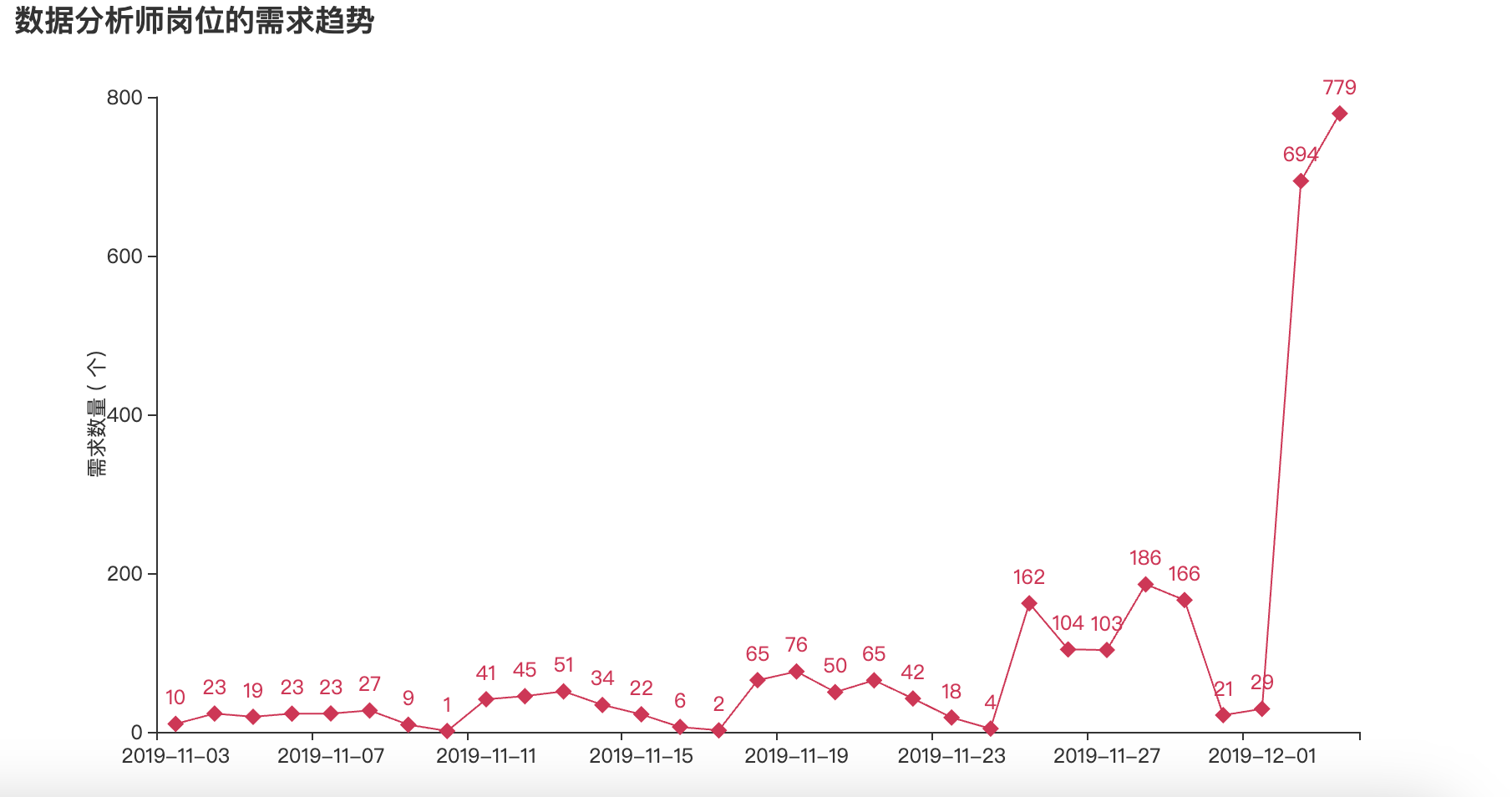
3.1数据分析师岗位的需求趋势
final_df['发布时间'] = final_df['发布时间'].dt.strftime('%Y-%m-%d')
final_df.head(10)
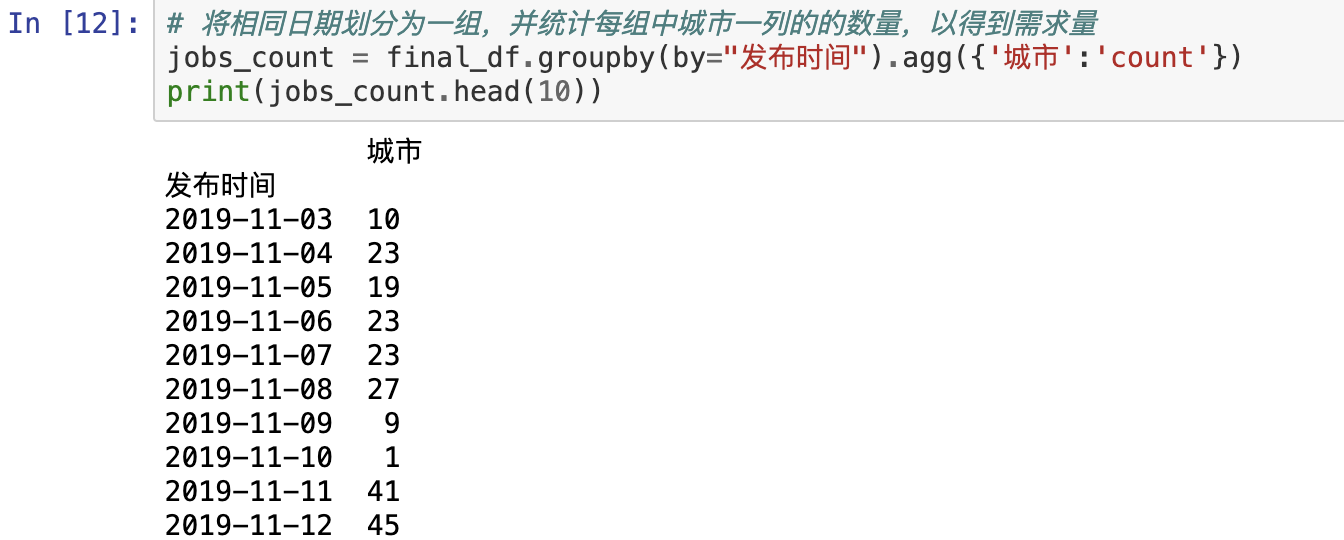
# 将相同日期划分为一组,并统计每组中城市一列的的数量,以得到需求量
jobs_count = final_df.groupby(by="发布时间").agg({'城市':'count'})
print(jobs_count.head(10))
from pyecharts.globals import WarningType
WarningType.ShowWarning = False
line_demo = (
Line(init_opts=opts.InitOpts(theme=ThemeType.ROMA))
# 添加x轴、y轴的数据、系列名称
.add_xaxis(jobs_count.index.tolist())
.add_yaxis('', jobs_count.values.tolist(), symbol='diamond',
symbol_size=10)
# 设置标题
.set_global_opts(title_opts=opts.TitleOpts(
title="数据分析师岗位的需求趋势"),
yaxis_opts=opts.AxisOpts(name="需求数量 ( 个)",
name_location="center", name_gap=30))
)
line_demo.render_notebook()
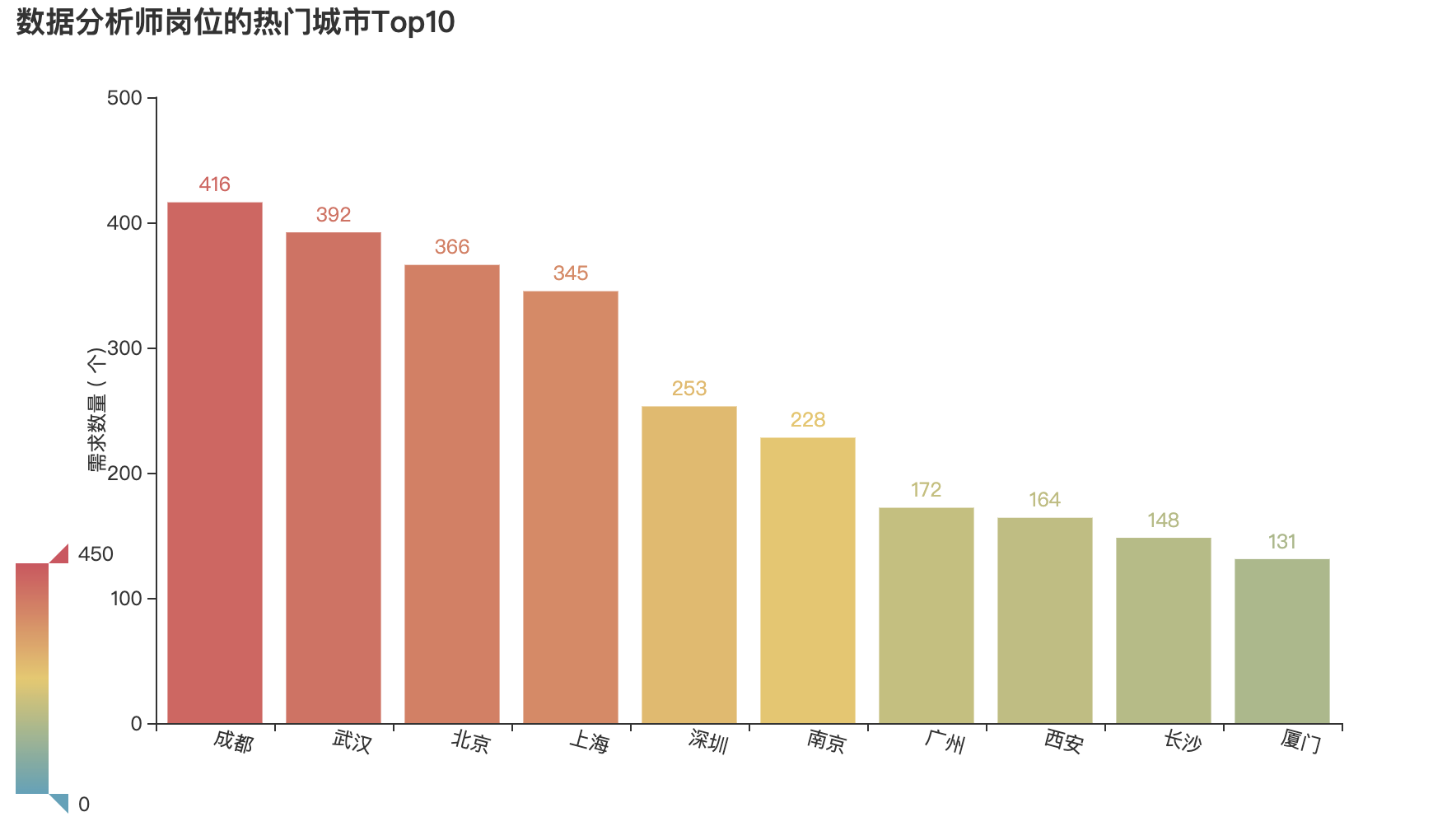
3.2数据分析师岗位的热门城市Top10
city_num = final_df['城市'].value_counts()
city_num.head(10)

# 将前10个结果转换为列表类型的数据
city_values = city_num.values[:10].tolist()
city_index = city_num.index[:10].tolist()
bar_demo = (
Bar()
# 添加x轴、y轴的数据、系列名称
.add_xaxis(city_index)
.add_yaxis("",city_values)
# 设置标题
.set_global_opts(title_opts=opts.TitleOpts(
title='数据分析师岗位的热门城市Top10'),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(max_=450),
yaxis_opts=opts.AxisOpts(name="需求数量 ( 个)",
name_location="center", name_gap=30))
)
bar_demo.render_notebook()
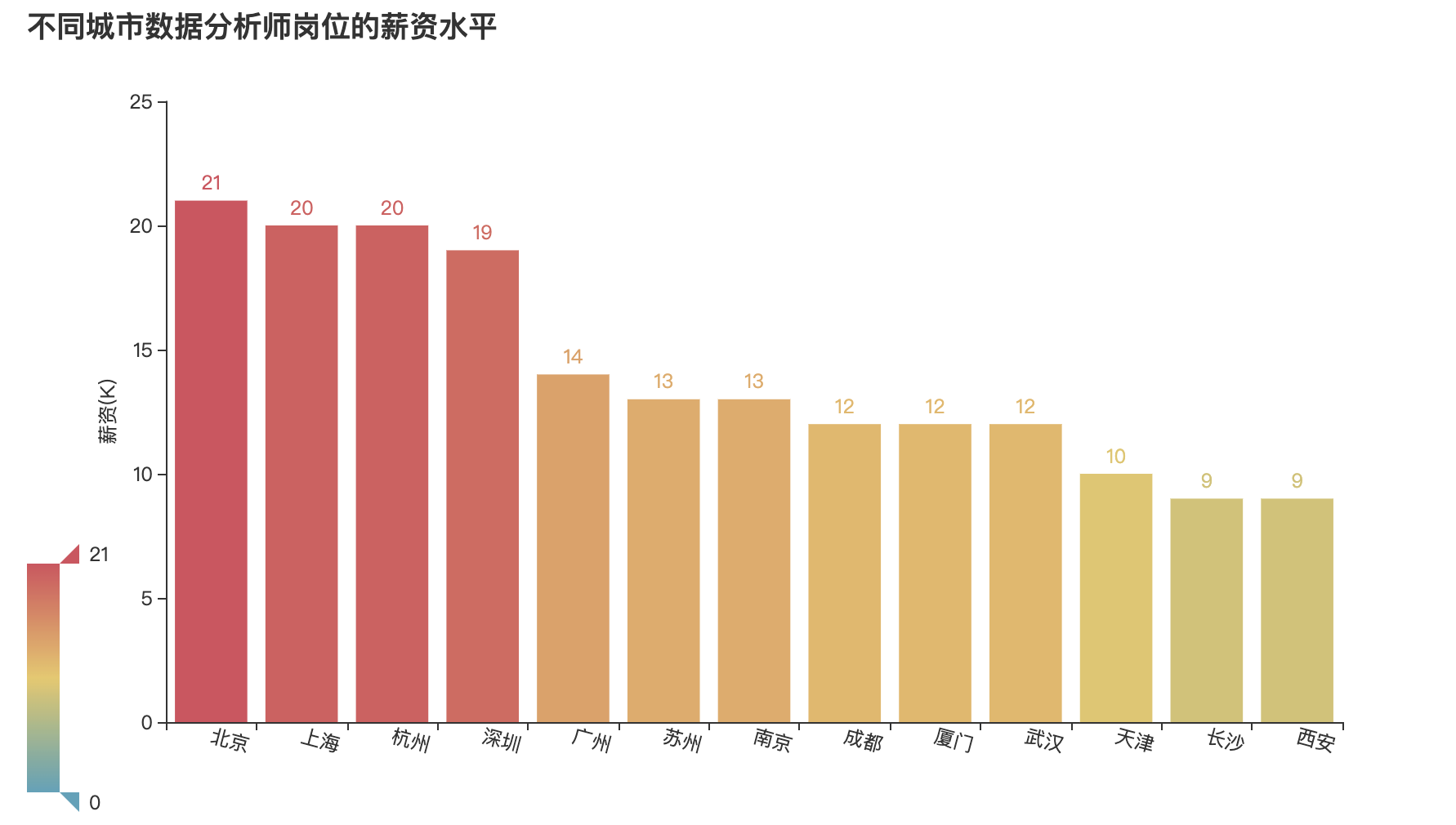
3.3不同城市数据分析师岗位的薪资水平
# 将数据里面的大写K转化为小写字母k
final_df['薪资'] = final_df['薪资'].str.lower().fillna(" ")
# 增加两列,一列是薪资范围的最大值,一列是薪资范围的最小值
final_df["薪资最小值"] = final_df["薪资"].str.extract(r'(\d+)').astype(int)
final_df["薪资最大值"] = final_df["薪资"].str.extract(r'\-(\d+)').astype(int)
average_df = final_df[["薪资最小值", "薪资最大值"]]
final_df["薪资平均值"] = average_df.mean(axis=1)
final_df.drop(columns=["薪资"], inplace=True)
final_df.head(10)
companyNum = final_df.groupby('城市')['薪资平均值'].mean().sort_values(ascending=False)
companyNum = companyNum.astype(int)
company_values = companyNum.values.tolist()
company_index = companyNum.index.tolist()
# 绘制柱形图
bar_demo2 = (
Bar()
# 添加x轴、y轴的数据、系列名称
.add_xaxis(company_index)
.add_yaxis("",company_values)
# 设置标题
.set_global_opts(title_opts=opts.TitleOpts(
title='不同城市数据分析师岗位的薪资水平'),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(max_=21),
yaxis_opts=opts.AxisOpts(name="薪资(K)",
name_location="center", name_gap=30))
)
bar_demo2.render_notebook()
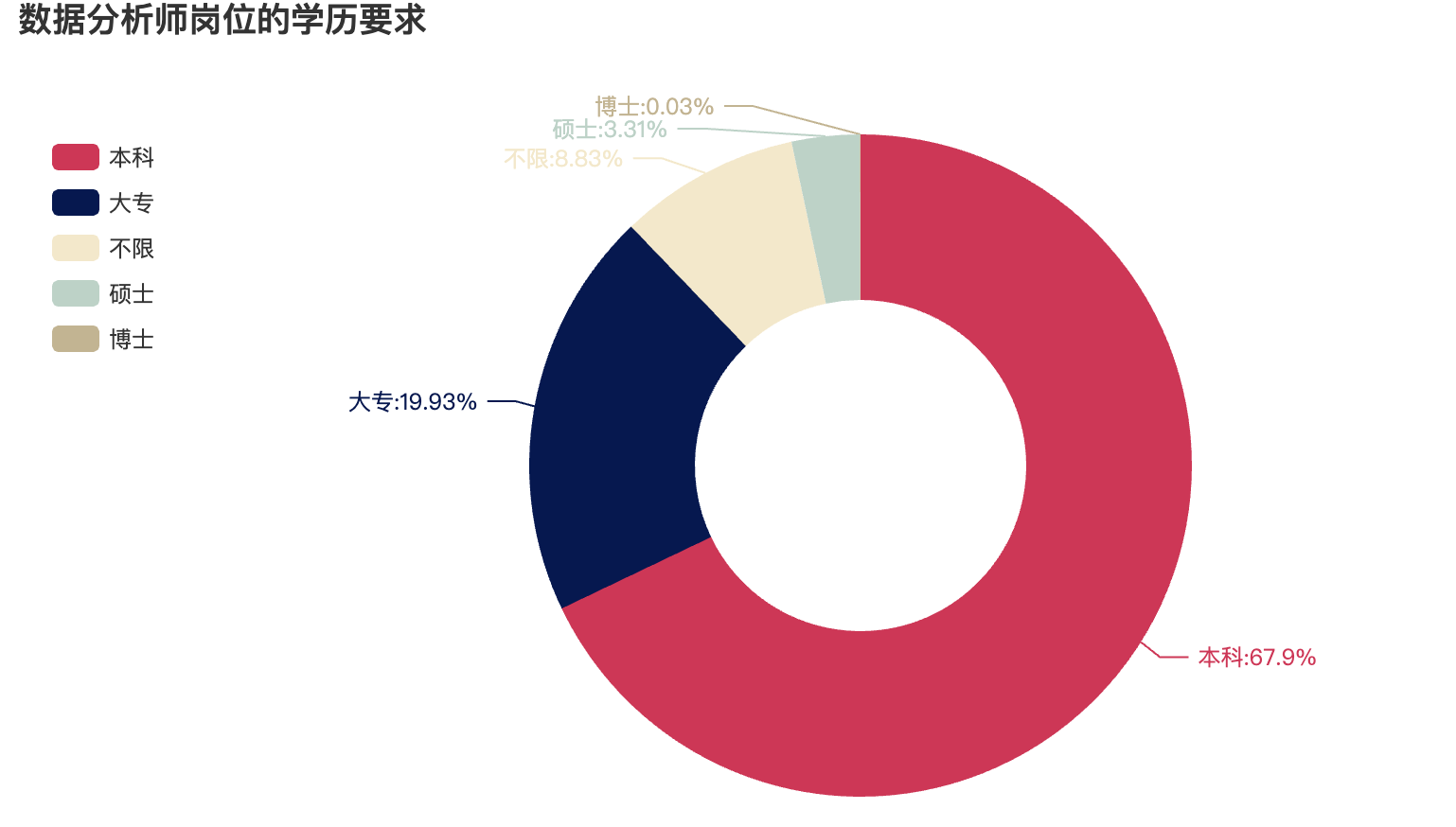
3.4 数据分析师岗位的学历要求
# 数据分析师岗位对学历的要求占比
education = final_df["学历"].value_counts()
cut_index = education.index.tolist()
cut_values = education.values.tolist()
data_pair = [list(z) for z in zip(cut_index,cut_values)]
# 绘制饼图
pie_obj = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.ROMA))
.add('', data_pair, radius=['35%', '70%'])
.set_global_opts(title_opts=opts.TitleOpts(
title='数据分析师岗位的学历要求'),
legend_opts=opts.LegendOpts(orient='vertical',
pos_top='15%', pos_left='2%'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
)
pie_obj.render_notebook()



















 1451
1451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











