







搜索引擎分类
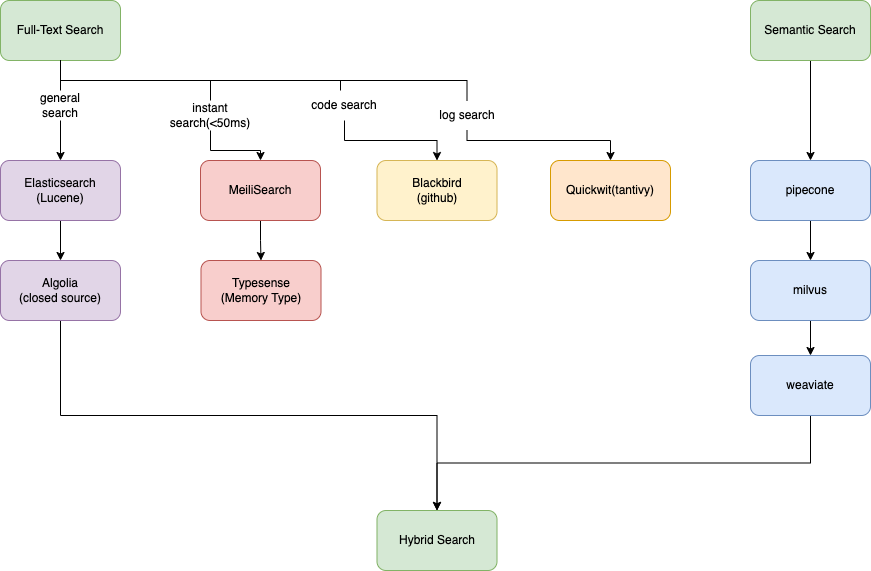
全文检索(full-text search/term-based search)
采用关键字(term-based)搜索方式进行。
按类型可以分为:
- 通用搜索(elasticsearch, algolia 等主流玩家,功能全)
- 实时搜索 (强调返回快,<50ms)
- 日志搜索 (强调低成本的海量存储及搜索)
- 代码搜索 (强调代码领域的搜索效果)
通用搜索
主流玩家(dominant player)
Elasticsearch
开源,java,基于Lucene内核。
核心竞争力,功能最全,用户基数最大。
通过开源建立影响力并通过免费版极大扩张用户基数。
私域领域,通过enterprise版本进行盈利。
(elastic-app帮助用户快速赋能, elastic-hadoop帮助用户在大数据场景下使用搜索)
公域领域,通过DbaaS进行盈利(思路同mongodb等)
(云厂商针对es的进行二次开发,在存储和计算分离,压缩索引等技术降低es的云使用成本,es也因此在7.11版本之后改变开源协议,阻止云厂商的这种影响es发展的行为)
Algolia
闭源,C++
核心竞争力,快速赋能用户/更易使用,更佳用户体验
帮助用户快速建立搜索能力(快速赋能),完全通过DbaaS的API调用进行盈利
Algolia和Elasticsearch的对比
其他玩家
新创业公司的常用机会点为:
通过新语言(Rust)和 新架构(存储和计算分离)等技术来实现更快,更低成本,更易用的搜索引擎,来和传统巨头进行竞争。
实时搜索:
代表产品:meilisearch(注重简单易用和运行快,算法对标Algolia,(meilisearch和主流搜索引擎的对比 ))
日志搜索:
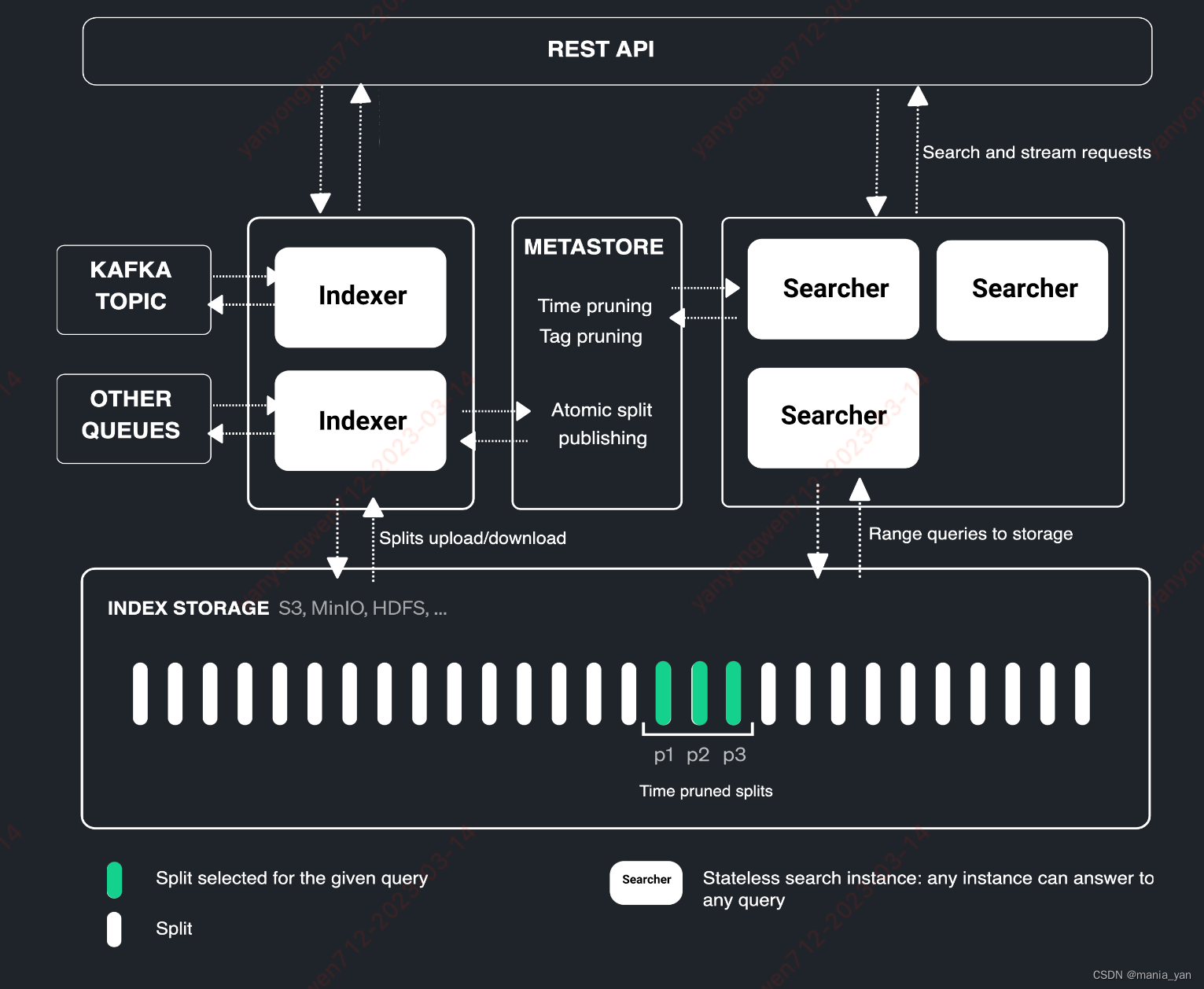
代表产品:Quickwit(差异化竞争力为:专注解决日志场景,更低成本)
关键设计:
【语言】rust——速度快
【索引】【存储】采用对象存储存储索引文件 —— 海量,无限拓展
【索引】【splits】将index细分为splits,通过hotcache文件可以在高延迟对象存储中做到<60ms的split打开速度,time filter可以通过split上的timestamp属性快速过滤无关的splits
【索引】【属性】metadata采用关系型数据库PG进行存储
【数据源】文件用于初始化,MQ Kafka用于持续获取数据
【集群】采用chitchat协议对失败节点进行检测
【分布式搜索】root节点收到query,从metastore中查询index的metadata,找出相关的splits;将splits分发给leaf nodes;返回聚合结果;
代码搜索:
由于传统的全文检索在代码领域的效果并不好,所以,例如github在2023年全新推出了它的自研代码搜索引擎。
语义搜索(semantic-search/vector-search)
将Everything转义为深度学习的embedding并根据相似度进行召回。openai对embedding的解析
近年AI浪潮涌现了一批向量数据库:pipecone, weaviate, redis, qdrant, milvus
传统搜索引擎巨头elasticsearch和algolia也加入了向量搜索的领域,非常热闹。
搜索领域为什么需要引入语义搜索?
- 可以让文本搜索召回率更高
a. 保留词位置信息:
普通的文本检索,没有词的位置信息,无法解决词相同,但含义不一样的问题。
例如:A给B分配任务 / B给A分配任务
is this interesting? / this is interesting
b. 多语言搜索
c. 同义词搜索
d. 分词错误场景下的搜索
2 支持图片,音频,视频的搜索。
支持文本搜索图片( CLIP模型 )(Zero Shot Learning ) pipecone的以文搜图例子
3 支持时序数据的搜索
可以分析金融领域的历史数据来预测现在的K线趋势 pipecone的时序数据搜索
向量搜索是目前搜索引擎的主流演进方向
目前大部分搜索引擎都在向这个方向进行创业和演进。
openAI提到的几个向量数据库有:pipecone, weaviate, qdrant
elasticsearch及内核lucene新版本主要都是围绕向量搜索的功能进行演进。
国内做到的比较成功的有milvus
甚至连redis也在跟进向量搜索,推出了redis-search
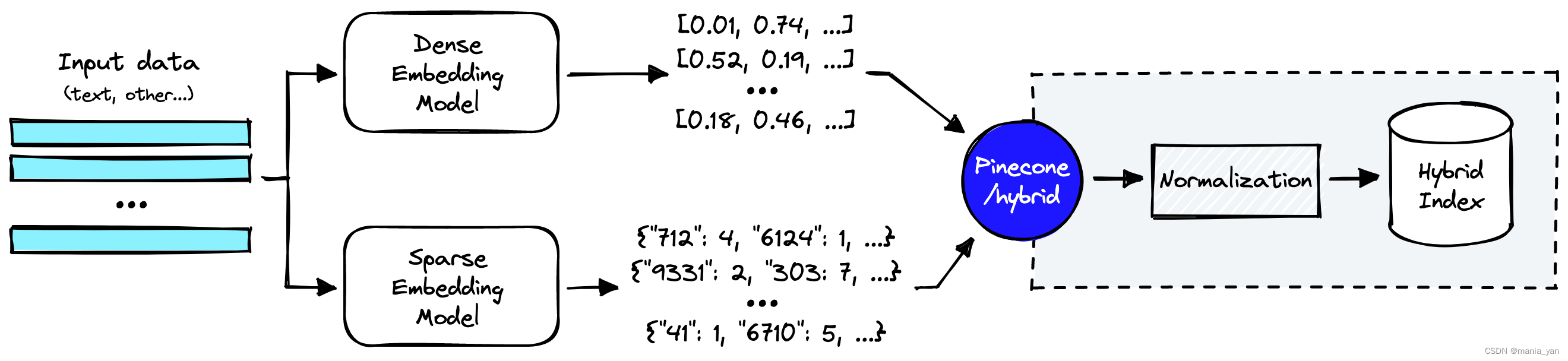
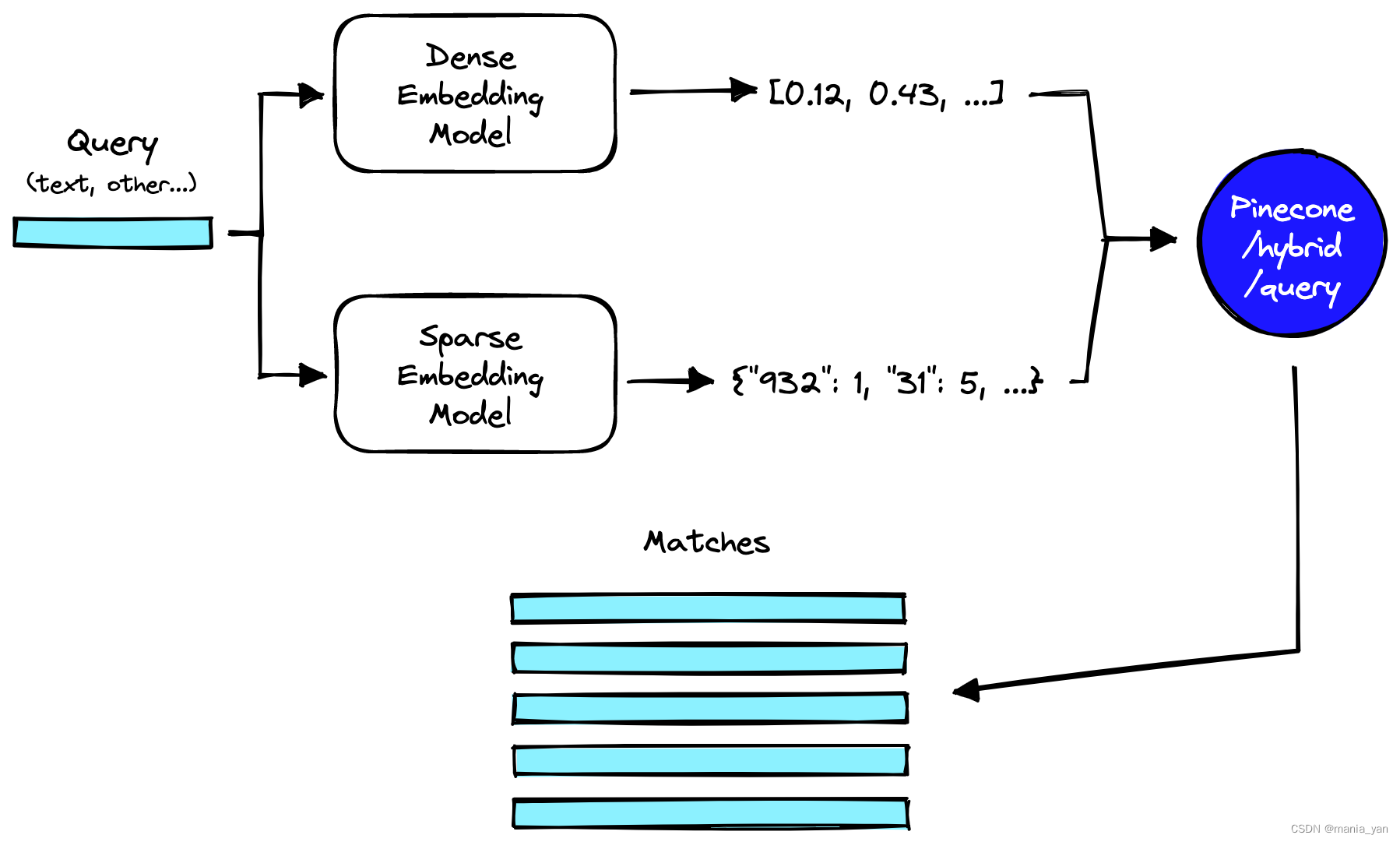
混合搜索
向量搜索的核心竞争力之一是混合搜索能力(hybrid search)
传统的文本搜索产生sparse embedding, 向量搜索产生dense embedding,2者能一起搜索,一起打分排序输出。
混合搜索相比普通的向量搜索,具有如下优势:
- 2路搜索,提高召回率(需要解决一起召回后的统一打分和排序问题)
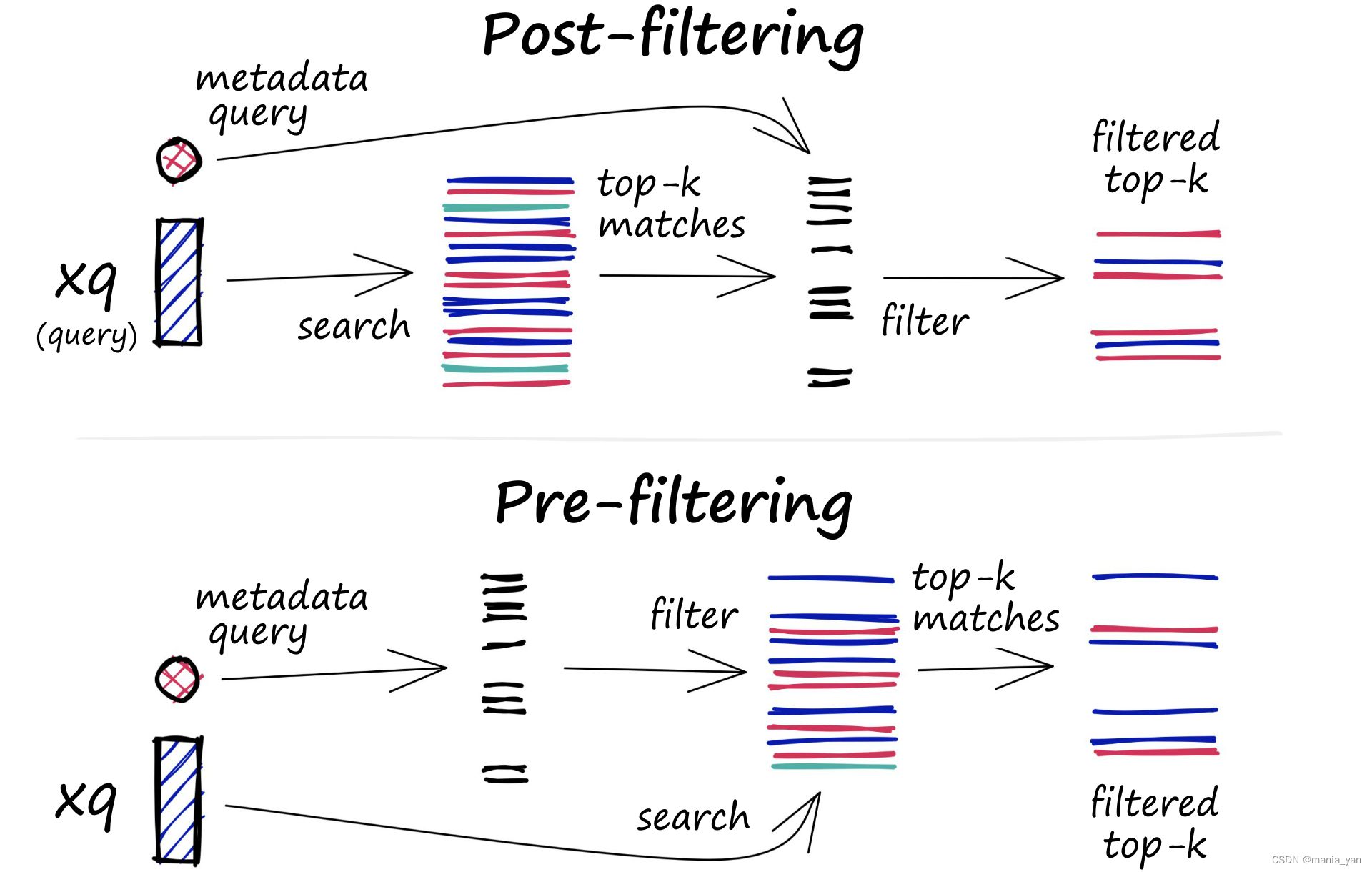
- 文本作为metadata进行事前过滤,减少无效输出
pipecone号称具有最好的混合搜索方案,但是没有公开具体算法。
搜索引擎的演进方向
- 采用能充分释放硬件性能的新语言进行开发(如,rust)
- 更低成本(存储计算分离,索引改造),更易用(用户/开发体验),更快(新语言)的方向演进产品
- 混合搜索 (文本及向量的混合搜索)

















 61
61

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









