







 本文介绍如何使用Scrapy框架进行数据爬取,并详细讲解了数据导出至JSON、CSV等多种格式及存入MySQL数据库的方法。通过ItemPipeline组件实现数据清理、验证和存储,提供了一个完整的爬虫项目示例。
本文介绍如何使用Scrapy框架进行数据爬取,并详细讲解了数据导出至JSON、CSV等多种格式及存入MySQL数据库的方法。通过ItemPipeline组件实现数据清理、验证和存储,提供了一个完整的爬虫项目示例。
上章回顾
前两章Python实战演练之scrapy初体验和Python实战演练之跨页爬取中讲到了scrapy项目的创建,爬虫的创建,数据的爬取以及跨页爬取。
数据导出
通过shell命令爬取的数据往往需要我们存放在某处
例如:执行如下命令来启用数据爬取
$ scrapy crawl crouses
将结果保存到文件中:格式:json、csv、xml、pickle、marshal等
$ scrapy crawl crouses -o fangs.json
$ scrapy crawl crouses -o fangs.csv
$ scrapy crawl crouses -o fangs.xml
$ scrapy crawl crouses -o fangs.pickle
$ scrapy crawl crouses -o fangs.marshal
除此之外,更多的时候我们需要将其存入数据库中。
存入数据库
我这里使用的mysql数据库,数据库管理工具使用的是Navicat Premium
mysql的安装以及Navicat如何连接mysql我空的时候再写出来跟大家分享吧。
ItemPipeline的介绍
- 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理
- 每个item pipeline组件(有时称之为”Item Pipeline“)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理
- 以下是item pipeline的一些典型应用:
清理HTML数据
验证爬取的数据(检查item包含某些字段)
查重(并丢弃)
将爬取结果保存到数据库中
如何自定义ItemPipeline
- 编写自己的item pipeline很简单,每个item pipelines组件是一个独立的Python类,同时必须实现以下方法:
process_item(item,spider) 必须
open_spider(spider) 可选
close_spider(spider) 可选
process_item(item,spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个Item(或任何继承类)对象,或是抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理(可用于做数据过滤)
参数:
- item(Item 对象)-被爬取的item
- spider(Spider对象)-爬取该item的spider
此外,他们也可实现以下方法。
open_spider(spider)
当spider被开启时,这个方法被调用。
参数:
- spider(Spider 对象)- 被开启的spider
close_spider(spider)
当spider被关闭时,这个方法被调用
参数:
- spider(Spider 对象)- 被关闭的spider
这里pipelins.py代码如下:
import pymysql
class EducsdnPipeline(object):
def process_item(self, item, spider):
return item
class MysqlPipeline(object):
def open_spider(self, spider):
'''负责连接数据库'''
self.db = pymysql.connect()
# 获取游标对象
self.cursor = self.db.cursor()
def process_item(self, item, spider):
'''执行数据表的写入操作'''
sql = "insert into courses(title,url,pic,teacher,time,price) values('%s','%s','%s','%s','%s','%s')"%(item['title'],item['url'],item['pic'],item['teacher'],str(item['time']),str(item['price']))
self.cursor.execute(sql)
self.db.commit()
return item
def close_spider(self, spider):
'''关闭连接数据库'''
self.db.close()
注意:
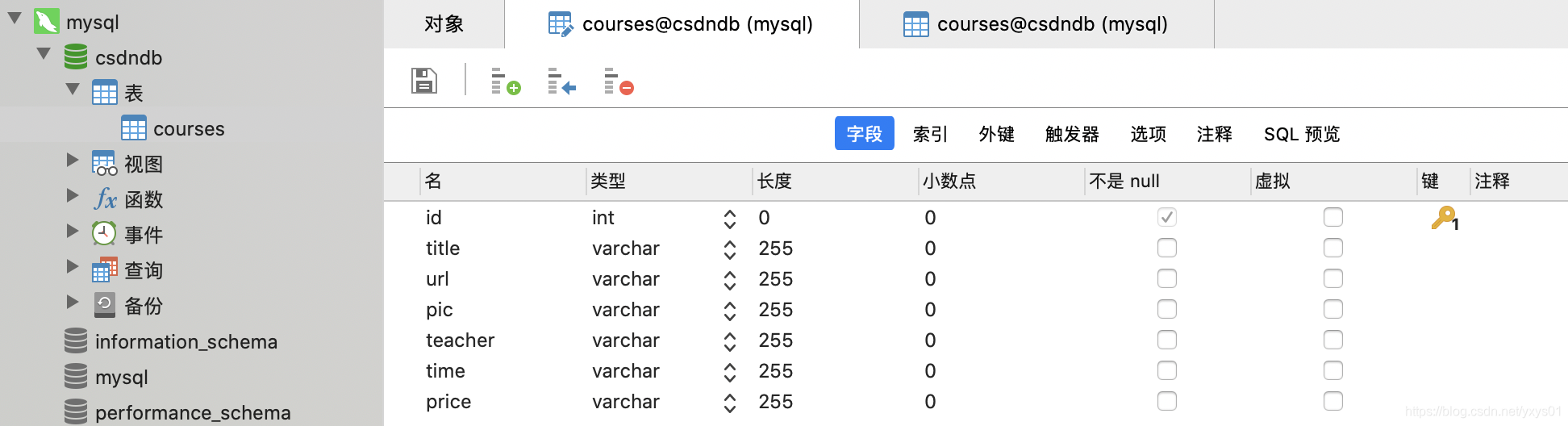
这里的操作是插入数据,前提是我已经在Navicat建好一个csdndb的数据库,并新建一个叫courses的表,如图所示:
一般数据库的连接中会传入数据库的名称,用户,密码,端口之类的参数,但是为了后面方便更改,将其放在settings里面处理。
在settings里面添加:
ITEM_PIPELINES = {
# 'educsdn.pipelines.EducsdnPipeline': 300,
'educsdn.pipelines.MysqlPipeline': 301,
}
MYSQL_HOST = "localhost"
MYSQL_DATABASE = "csdndb"
MYSQL_USER = "root"
MYSQL_PASS = "xxxxxx" #没有也可以留空
MYSQL_PORT = 3306
回到pipelines.py,改为:
import pymysql
class EducsdnPipeline(object):
def process_item(self, item, spider):
return item
class MysqlPipeline(object):
def __init__(self, host, user, password, database, port):
self.host = host
self.user = user
self.password = password
self.database = database
self.port = port
@classmethod
def from_crawler(cls, crawler):
# 自动调用;为了实例化当前类对象;cls就是当前这个类
return cls(
host = crawler.settings.get("MYSQL_HOST"),
user = crawler.settings.get("MYSQL_USER"),
password = crawler.settings.get("MYSQL_PASS"),
database = crawler.settings.get("MYSQL_DATABASE"),
port = crawler.settings.get("MYSQL_PORT")
)
def open_spider(self, spider):
'''负责连接数据库'''
self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset="utf8", port=self.port)
# 获取游标对象
self.cursor = self.db.cursor()
def process_item(self, item, spider):
'''执行数据表的写入操作'''
sql = "insert into courses(title,url,pic,teacher,time,price) values('%s','%s','%s','%s','%s','%s')"%(item['title'],item['url'],item['pic'],item['teacher'],str(item['time']),str(item['price']))
self.cursor.execute(sql)
self.db.commit()
return item
def close_spider(self, spider):
'''关闭连接数据库'''
self.db.close()
除此之外,还要在courses.py中将item传入pipelines中
courses.py完整代码如下:
import scrapy
from educsdn.items import CoursesItem
class CoursesSpider(scrapy.Spider):
name = 'courses'
allowed_domains = ['edu.youkuaiyun.com']
start_urls = ['https://edu.youkuaiyun.com/courses/o280/p1']
#第一页
p = 1
def parse(self, response):
# 解析课程信息
# 获取当前请求页面下的所有课程信息
print(dd.xpath("./div[@class='titleInfor'/text()]").extract())
dl = response.selector.css("div.course_item")
# 遍历课程信息并封装到item
for dd in dl:
item = CoursesItem()
item['title'] = dd.css("span.title::text").extract_first()
item['url'] = dd.css("a::attr(href)").extract_first()
item['pic'] = dd.css("img::attr(src)").extract_first()
item['teacher'] = dd.css("span.lecname::text").extract_first()
item['time'] = dd.css("span.course_lessons::text").extract_first()
item['price'] = dd.css("p.priceinfo i::text").extract_first()
# print(item)
# 将数据送入pipelines
yield item
# 跨页提取信息
self.p += 1
if self.p < 4:
next_url = 'https://edu.youkuaiyun.com/courses/o280/p'+ str(self.p)
url = response.urljoin(next_url)
yield scrapy.Request(url=url,callback=self.parse)
其实就是将print(item)改为yield item
其他代码在前两章有写,这里就不多说了,项目代码后期我会上传到Github上,敬请期待。
回到控制台
educsdn $ scrapy crawl courses
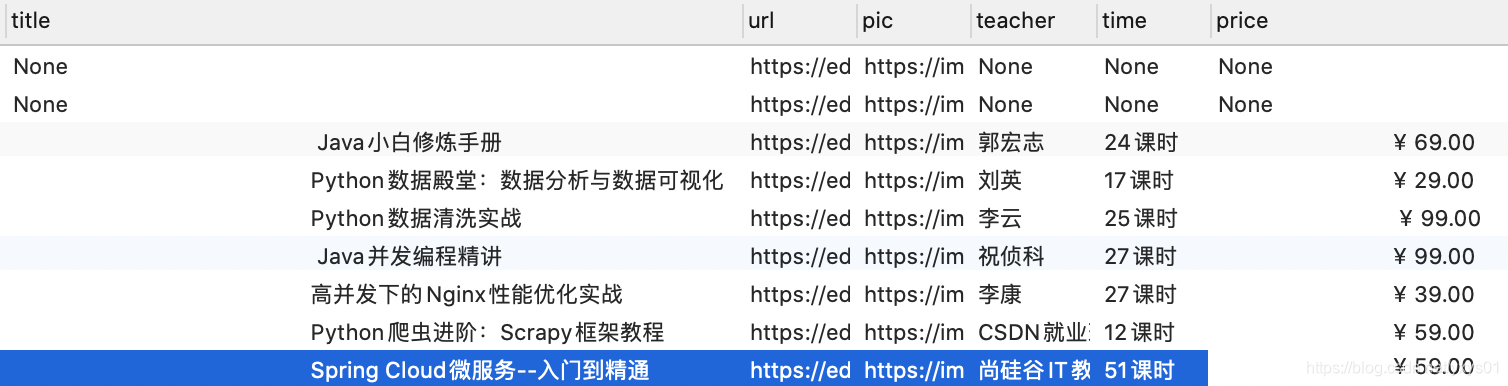
刷新数据库
如下所示,已经成功插入数据


















 3354
3354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











