






1.textFile读取文件时,与线程数没有关系
例如:
TEXTFILE模式下如果文件没有给定分区则是按照文件数进行分区,这种情况是所有文件相同大的情况下
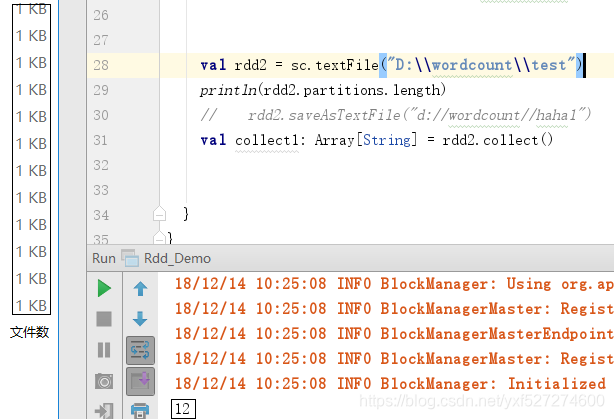
如果指定分区数textFile(path,3)则是三个分区,在文件不一样大的情况下,分区数则会增加,
例如:
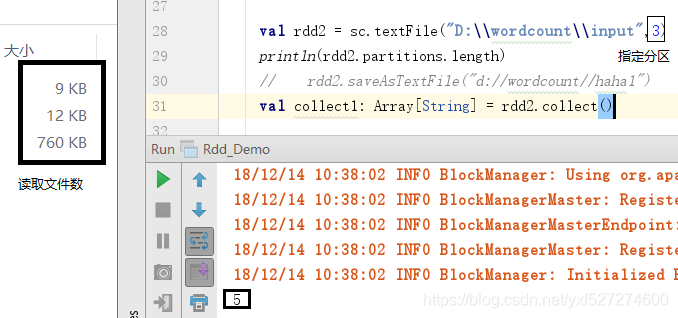
3个文件分别为9K,12K,760K加起来是781k,除以3等于260,9 / 260 <1.1(1个分区)二百六十零分之十二<1.1(1个分区)0.760 / 260> 1.1那么0- 260(又是一个分区),760-260 = 500500/260> 1.1(又是一个分区)500-260 = 240240/260 <1.1(又一个分区)那么总共就是5个分区,如下图
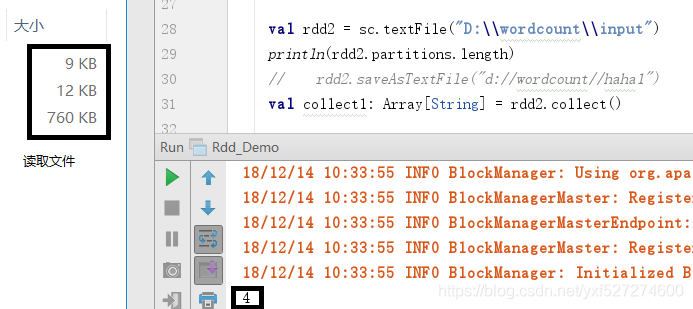
如果此时不给定分区数则是按照默认最小2个分区去计算,计算出来就是4个分区
2.parallelize模式下
当地是按照线程数去分区
例如:本地[3]就是3个分区
但是特别注意在prarllelize模式的本地下如果不指定线程数,则是1个分区
3.在伪分布式模式下
用火花壳直接启动查看分区则是1个分区
如果spark-shell --master则是按照伪集群模式(x为本机上启动的执行者数,y为每个执行者使用的核心数,z为每个执行者使用的内存)
spark-shell --master local-cluster [x,y,z] spark.default.parallelism = x * y

















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









