









说在前面:
总算完整的学习了一遍事务管理,有些事自己的领悟,大多还是参考现有的很多资料。作为一个知识的搬运工,我把知识做了一个总结,也算对这段时间的学习有个交代。
内容主要是:事务的定义,以及不同架构的事务使用。特别是现在微服务架构盛行的时候。对分布式事务起码需要了解
一、分布式与集群概念
1.分布式是将不同的业务分布在不同的地方
2.集群是将几台服务器集中在一起,实现同一业务
3.分布式中每个节点,都可以做集群
- 服务架构
传统服务 -----> SOA -----> 微服务架构
| 功能 | SOA | 微服务 |
| 组件大小 | 大块业务逻辑 | 单独任务或小块业务逻辑 |
| 耦合 | 通常松耦合 | 总是松耦合 |
| 公司架构 | 任何类型 | 小型、专注于功能交叉团队 |
| 管理 | 着重中央管理 | 着重分散管理 |
| 目标 | 确保应用能够交互操作 | 执行新功能、快速拓展开发团队 |
1.SOA特点:
两个主要角色:服务提供者(Provider)和服务使用者(Consumer)
系统集成:站在系统的角度,解决企业系统间的通信问题,把原先散乱、无规划的系统间的网状结构,梳理成规整、可治理的系统间星形结构,这一步往往需要引入一些产品,比如ESB、以及技术规范、服务管理规范;这一步解决的核心问题是【有序】
系统的服务化:站在功能的角度,把业务逻辑抽象成 可复用、可组装的服务,通过服务的编排实现业务的 快速再生,目的:把原先固有的业务功能转变为通用的业务服务,实现业务逻辑的快速复用;这一步解决的核心问题是【复用】
业务的服务化:站在企业的角度,把企业职能抽象成可复用、可组装的服务;把原先职能化的企业架构转变为服务化的企业架构,进一步提升企业的对外服务能力;“前面两步都是从技术层面来解决系统调用、系统功能复用的问题”。第三步,则是以业务驱动把一个业务单元封装成一项服务。这一步解决的核心问题是【高效】
2.微服务架构
某种程度上是面向服务的架构SOA继续发展的下一步
1.通过服务实现组件化
开发者不再需要协调其它服务部署对本服务的影响。
2.按业务能力来划分服务和开发团队
开发者可以自由选择开发技术,提供 API 服务
3.去中心化
每个微服务有自己私有的数据库持久化业务数据
每个微服务只能访问自己的数据库,而不能访问其它服务的数据库
某些业务场景下,需要在一个事务中更新多个数据库。这种情况也不能直接访问其 它微服务的数据库,而是通过对于微服务进行操作。
数据的去中心化,进一步降低了微服务之间的耦合度,不同服务可以采用不同的数 据库技术(SQL、NoSQL等)。在复杂的业务场景下,如果包含多个微服务,通常在客户 端或者中间层(网关)处理。
4.基础设施自动化(devops、自动化部署)
Java EE部署架构,通过展现层打包WARs,业务层划分到JARs最后部署为EAR一 个大包,而微服务则打开了这个黑盒子,把应用拆分成为一个一个的单个服务,应用 Docker技术,不依赖任何服务器和数据模型,是一个全栈应用,可以通过自动化方式 独立部署,每个服务运行在自己的进程中,通过轻量的通讯机制联系,经常是基于HTTP 资源API,这些服务基于业务能力构建,能实现集中化管理(因为服务太多啦,不集中 管理就无法DevOps啦)。
三、事务
1.柔性事务VS刚性事务
本地事务采用刚性事务, JDBC(单库的事务)
分布式事务使用柔性事务 JTA(多库的事务)
刚性事务是指严格遵循ACID原则的事务, 例如单机环境下的数据库事务
柔性事务是指遵循BASE理论的事务, 通常用在分布式环境中, 常见的实现方式有:
两阶段提交(2PC), TCC补偿型提交, 基于消息的异步确保型, 最大努力通知型.
2.事务相关定义
ACID(Atomicity,Consistency,Isolation,Durability)
Atomicity原子性:一个事务中所有操作都必须全部完成,要么全部不完成。
Consistency一致性. 在事务开始或结束时,数据库应该在一致状态。
Isolation隔离层. 事务将假定只有它自己在操作数据库,彼此不知晓。
Durability. 一旦事务完成,就不能返回。
CAP帽子理论: CAP(Consistency, Availability, Partition Tolerance)
Consistency(一致性), 数据一致更新,所有数据变动都是同步的
Availability(可用性), 好的响应性能
Partition tolerance(分区容忍性) 可靠性
BASE思想: BASE(Basically avaliable, soft state, eventually consistent):
是分布式事务实现的一种理论标准,分布式系统的一致性和可用性不能兼得的问题
BASE模型反ACID模型,完全不同ACID模型,牺牲高一致性,获得可用性或可靠性:
Basically Available基本可用。支持分区失败(e.g. sharding碎片划分数据库)
Soft state软状态 状态可以有一段时间不同步,异步。
Eventually consistent最终一致,最终数据是一致的就可以了,而不是时时高一致。
3.刚性事务:
事务的定义:事务表示一个由一系列的数据库操作组成的不可分割的逻辑单位,其中的操作要么全做要么全都不做。
事务的特性 ACID(Atomicity,Consistency,Isolation,Durability)
1、原子性:同一个事务的操作要么全部成功执行,要么全部撤消
2、隔离性:事务的所有操作不会被其它事务干扰
3、一致性:在操作过程中不会破坏数据的完整性
4、持久性:一旦事务完成了,那么事务对数据所做的变更就完全保存在了数据库 中
4个隔离级别
1:默认的隔离级别,同数据库一样的,如果不做特别设置,
mysql默认的是可重复读,而oracle默认的是读提交
2:读未提交,即一个事务可以读取另外一个事务中未提交的数据,
即脏读数据存在,性能最好,但是没啥用
3:读提交,即一个事务只能读取到另一个事务提交后的数据,
oracle数据库默认隔离级别;存在不可重复读问题,即交叉事务出现,
A事务两次读取数据可能会读到B事务提交的修改后的数据,
即在同一个事务中读到了不同的数据,也叫不可重复读
4:可重复读,即一个事务只能读取到在次事务之前提交的数据,而之后提交不能 读取到,不管对方的事务是否提交都读取不到,mysql默认的隔离级别。
此隔离级别有可能会遇到幻读现象,但是mysql 基于innodb引擎实现的数据 库已经通过多版本控制解决了此问题,所以可以不考虑了。
7个传播方式
int PROPAGATION_REQUIRED = 0; //事务传播级别1:当前如果有事务,
Spring就会使用该事务;否则会开始一个新事务;(这也是默认设置和定义)
int PROPAGATION_SUPPORTS = 1;//事务传播级别2:如果有事务,
Spring就会使用该事务;否则不会开始一个新事务
int PROPAGATION_MANDATORY = 2; //事务传播级别3:当前如果有事务,
Spring就会使用该事务;否则会因为没有事务而抛出异常
int PROPAGATION_REQUIRES_NEW = 3;//事务传播级别4:总是要开启一个新事务。
如果当前已经有事务,则将已有事务挂起
int PROPAGATION_NOT_SUPPORTED = 4;//事务传播级别5:
代码总是在非事务环境下执行,如果当前有事务,则将已有事务挂起,再执行 代码,之后恢复事务
int PROPAGATION_NEVER = 5; //事务传播级别6:绝对不允许代码在事务中执行。
如果当前运行环境有事务存在,则直接抛出异常,结束运行
int PROPAGATION_NESTED = 6;//事务传播级别7:该级别支持嵌套事务执行。如果 没有父事务存在,那么执行情况与PROPAGATION_REQUIRED一样;
典型的应用是批量数据入库,开启父事务对一批数据入库,而对于每条入库的 数据都有一个子事务对应,
那么当所有的子事务成功,父事务提交,才算成功,否则,就都失败。
JDBC 注解/编程式
1.注解 @Transaction
推荐使用注解
2.编程式
TransactionDefinition def = new DefaultTransactionDefinition();
TransactionStatus status = transactionManager.getTransaction(def);
try{
业务逻辑。。。
transactionManager.commit(status);//提交
}catch(Exception e){
transactionManager.rollback(status);//回滚
throw e;
}
- 柔性事务:
https://blog.youkuaiyun.com/u010425776/article/details/79516298
- 分布式事务处理种类
1)、两阶段提交(2PC)型
对应技术上的XA、JTA/JTS
2)、事务补偿型(TCC事务)
3)、异步确保型
4)、最大努力型(消息队列)
2.分布式事务管理(多数据库)实现方式:
- 基于XA协议的两阶段提交方案
交易中间件与数据库通过 XA 接口规范,使用两阶段提交来完成一个全局事务, XA 规范的基础是两阶段提交协议。
第一阶段是表决阶段,所有参与者都将本事务能否成功的信息反馈发给协调者;第二阶段是执行阶段,协调者根据所有参与者的反馈,通知所有参与者,步调一致地在所有分支上提交或者回滚。
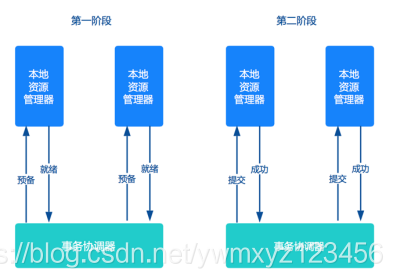
两阶段提交方案应用非常广泛,几乎所有商业OLTP数据库都支持XA协议。但是两阶段提交方案锁定资源时间长,对性能影响很大,基本不适合解决微服务事务问题
- TCC方案
在电商、金融领域落地较多。TCC方案其实是两阶段提交的一种改进。其将整个业务逻辑的每个分支显式的分成了Try、Confirm、Cancel三个操作。Try部分完成业务的准备工作,confirm部分完成业务的提交,cancel部分完成事务的回滚。基本原理如下图所示。
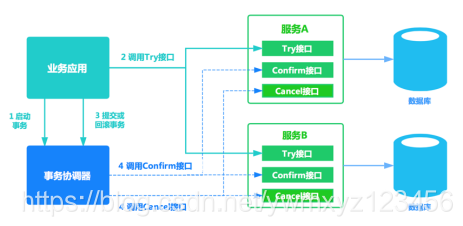
事务开始时,业务应用会向事务协调器注册启动事务。之后业务应用会调用所有服务的try接口,完成一阶段准备。之后事务协调器会根据try接口返回情况,决定调用confirm接口或者cancel接口。如果接口调用失败,会进行重试。
TCC方案让应用自己定义数据库操作的粒度,使得降低锁冲突、提高吞吐量成为可能。 当然TCC方案也有不足之处,集中表现在以下两个方面:
对应用的侵入性强。业务逻辑的每个分支都需要实现try、confirm、cancel三 个操作,应用侵入性较强,改造成本高。
实现难度较大。需要按照网络状态、系统故障等不同的失败原因实现不同的回滚策略。为了满足一致性的要求,confirm和cancel接口必须实现幂等。
上述原因导致TCC方案大多被研发实力较强、有迫切需求的大公司所采用。微服务倡导服务的轻量化、易部署,而TCC方案中很多事务的处理逻辑需要应用自己编码实现,复杂且开发量大。
- 基于消息的最终一致性方案
通过消息中间件保证上、下游应用数据操作的一致性
。基本思路是将本地操作和发送消息放在一个事务中,保证本地操作和消息发送要么两者都成功或者都失败。下游应用向消息系统订阅该消息,收到消息后执行相应操作。
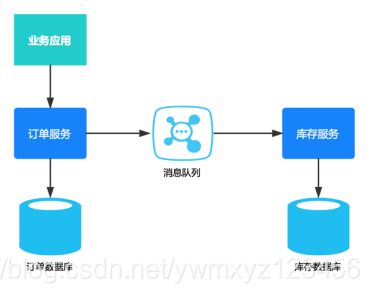
消息方案从本质上讲是将分布式事务转换为两个本地事务,然后依靠下游业务的重试机制达到最终一致性。基于消息的最终一致性方案对应用侵入性也很高,应用需要进行大量业务改造,成本较高。
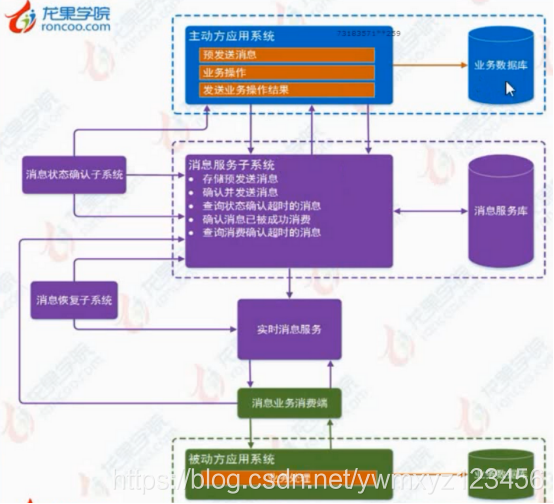
- 异步确保型

- 案例解析
- 基于支付系统真实业务场景进行具体问题实现和详细讲解分布式事务
https://www.oschina.net/question/3573545_2282562

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









