






一、 查询性能优化
1. 使用 Explain 进行分析
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
-
select_type : 查询类型,有简单查询、联合查询、子查询等
-
key : 使用的索引
-
rows : 扫描的行数
mysql> explain select * from user_info where id = 2\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: user_info partitions: NULL type: const possible_keys: PRIMARY key: PRIMARY key_len: 8 ref: const rows: 1 filtered: 100.00 Extra: NULL 1 row in set, 1 warning (0.00 sec)
更多内容请参考:MySQL 性能优化神器 Explain 使用分析
2. 优化数据访问
1. 减少请求的数据量
(一)只返回必要的列
最好不要使用 SELECT * 语句。
(二)只返回必要的行
使用 WHERE 语句进行查询过滤,有时候也需要使用 LIMIT 语句来限制返回的数据。
(三)缓存重复查询的数据
使用缓存可以避免在数据库中进行查询,特别要查询的数据经常被重复查询,缓存可以带来的查询性能提升将会是非常明显的。
2. 减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
3. 重构查询方式
1. 切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
DELEFT FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);
rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")
} while rows_affected > 0
2. 分解大连接查询
将一个大连接查询(JOIN)分解成对每一个表进行一次单表查询,然后将结果在应用程序中进行关联,这样做的好处有:
-
让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
-
分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
-
减少锁竞争;
-
在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可扩展。
-
查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
SELECT * FROM tab JOIN tag_post ON tag_post.tag_id=tag.id JOIN post ON tag_post.post_id=post.id WHERE tag.tag='mysql'; SELECT * FROM tag WHERE tag='mysql'; SELECT * FROM tag_post WHERE tag_id=1234; SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
二、最左匹配原则的底层原理
最左匹配原则都是针对联合索引来说的,所以我们可以从联合索引的原理来了解最左匹配原则。
我们都知道索引的底层是一颗 B+ 树,那么联合索引当然还是一颗 B+ 树,只不过联合索引的键值数量不是一个,而是多个。构建一颗 B+ 树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建 B+ 树。例子:假如创建一个(a,b,c)的联合索引,那么它的索引树是这样的:
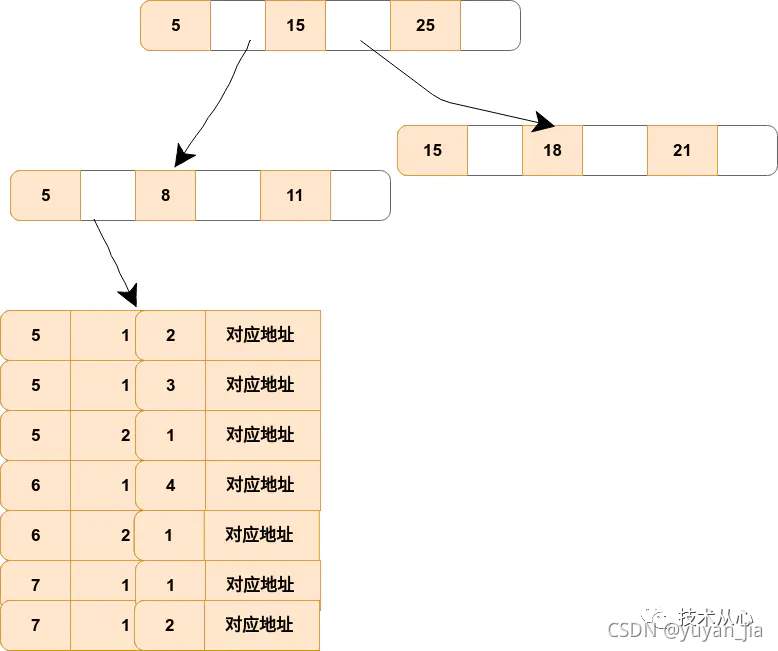
该图就是一个形如(a,b,c)联合索引的 b+ 树,其中的非叶子节点存储的是第一个关键字的索引 a,而叶子节点存储的是三个关键字的数据。这里可以看出 a 是有序的,而 b,c 都是无序的。但是当在 a 相同的时候,b 是有序的,b 相同的时候,c 又是有序的。通过对联合索引的结构的了解,那么就可以很好的了解为什么最左匹配原则中如果遇到范围查询就会停止了。以 select * from t where a=5 and b>0 and c =1; #这样a,b可以用到(a,b,c),c不可以 为例子,当查询到 b 的值以后(这是一个范围值),c 是无序的。所以就不能根据联合索引来确定到底该取哪一行。
总结
在 InnoDB 中联合索引只有先确定了前一个(左侧的值)后,才能确定下一个值。如果有范围查询的话,那么联合索引中使用范围查询的字段后的索引在该条 SQL 中都不会起作用。值得注意的是,in 和 = 都可以乱序,比如有索引(a,b,c),语句 select * from t where c =1 and a=1 and b=1,这样的语句也可以用到最左匹配,因为 MySQL 中有一个优化器,他会分析 SQL 语句,将其优化成索引可以匹配的形式,即 select * from t where a =1 and b=1 and c=1


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









