







 Web Scraper是一款适合非程序员的免费Chrome插件,用于抓取网页内容。本文介绍了其安装过程和实战演练,包括如何配置抓取规则、导出数据以及处理翻页问题,提供了一个在车商悦官网抓取资讯信息的例子。
Web Scraper是一款适合非程序员的免费Chrome插件,用于抓取网页内容。本文介绍了其安装过程和实战演练,包括如何配置抓取规则、导出数据以及处理翻页问题,提供了一个在车商悦官网抓取资讯信息的例子。
以下是个人整理的学习笔记,仅供参考
webscraper 简介
Web Scraper 是一款免费的,适用于普通用户的爬虫工具,可以方便的通过鼠标和简单配置获取网页上的内容:文字、链接、图片、表格等,而无需写一行代码。
一、安装过程
webscraper是一个谷歌浏览器插件程序,所以想要使用首先要安装一个Chrome浏览器(可自行百度下载安装)
1、先下载好 webScraper 插件
前往网盘地址获取webScraper插件压缩包:
链接: https://pan.baidu.com/s/1BE47WDBPHEbY64sg3r8C1g
密码: ou30
2、打开Chrome浏览器的 扩展程序
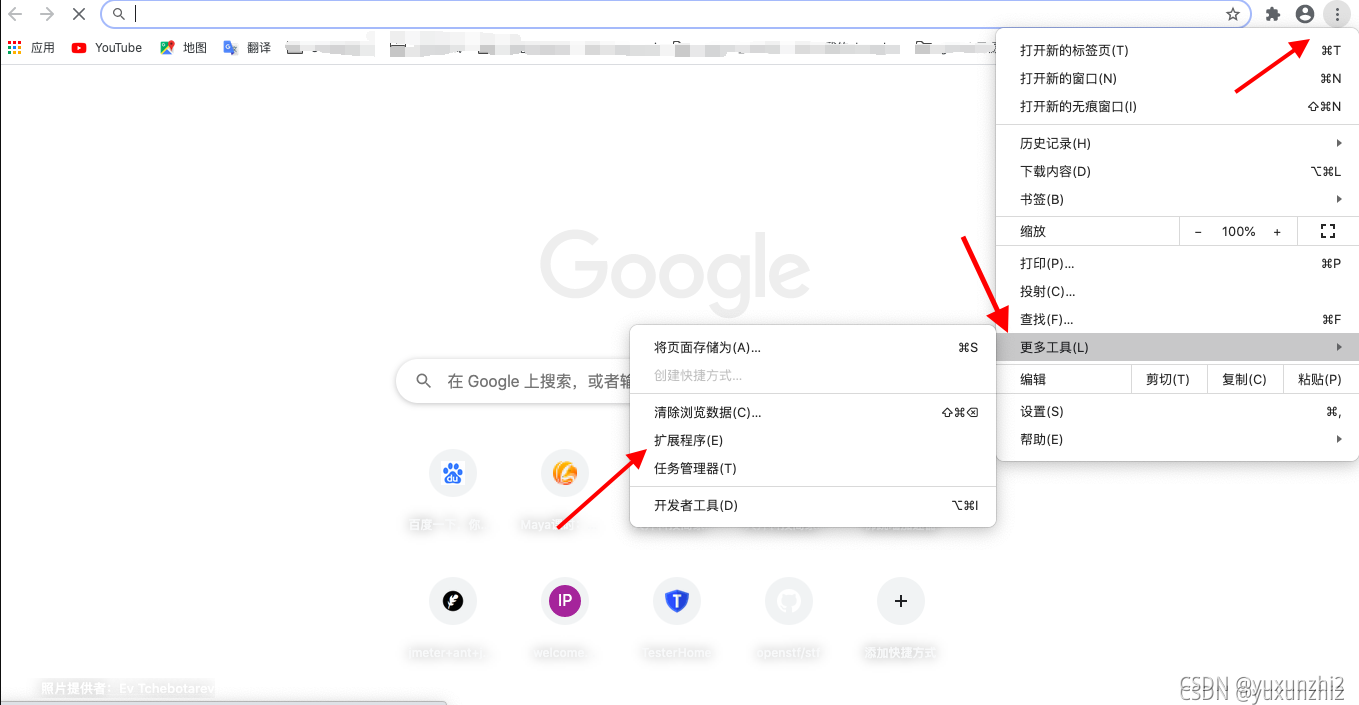
3、把下载好的 webscraper插件文件压缩包 鼠标点击拖进去,且打开 开发者模式
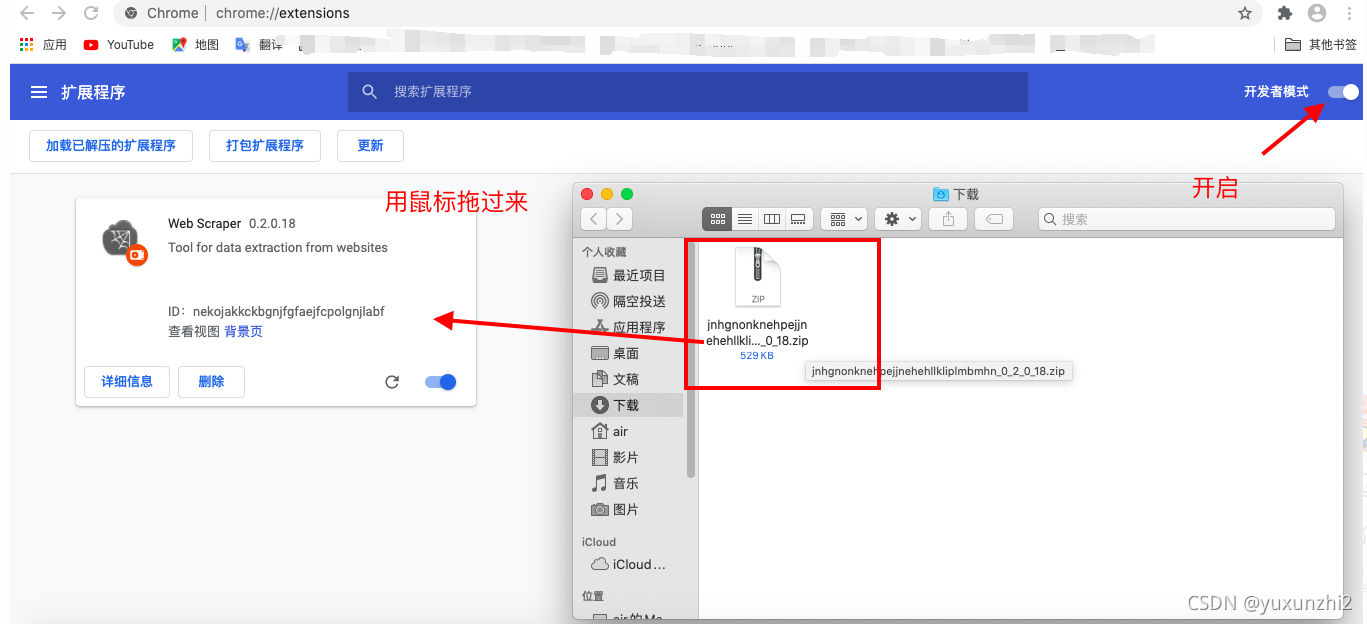
以上安装配置完成后,我们来小试一下牛刀。
二、实战演练
例如,我想抓取车商悦官网的一些资讯信息
(车商悦官网访问地址是:http://www.cargeer.com/gw/zixun/)
1、首先打开车商悦官网,然后打开Chrome浏览器的 开发者工具,如下图:
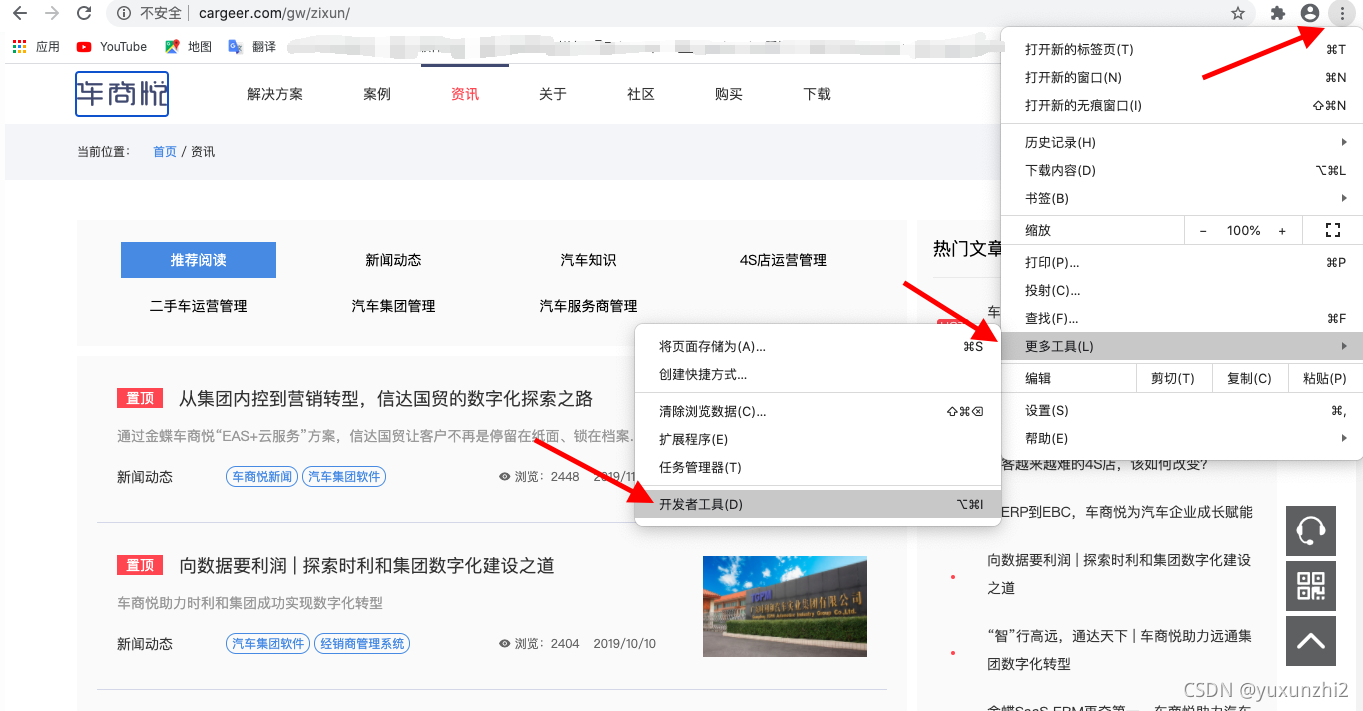
2、找到之前配置安装好的 webScraper ,如下图所示:
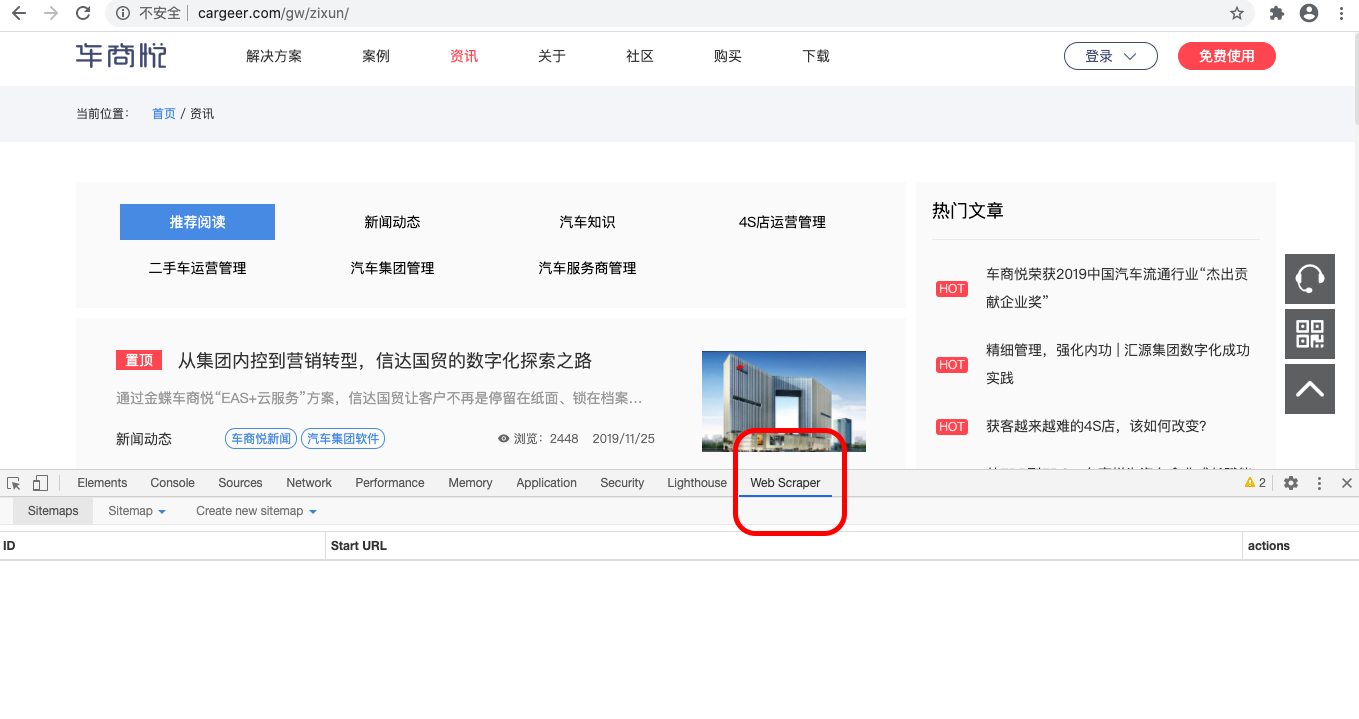
3、创建新增一个你要爬取数据的网站
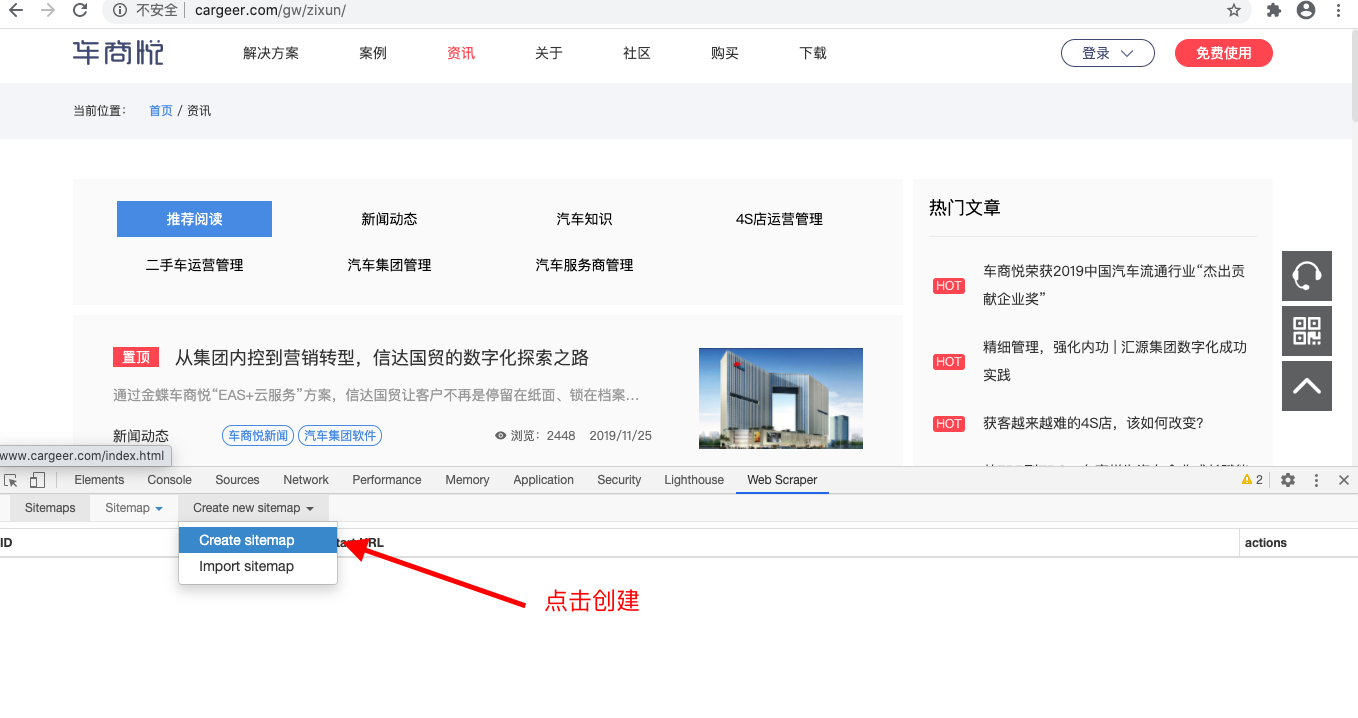
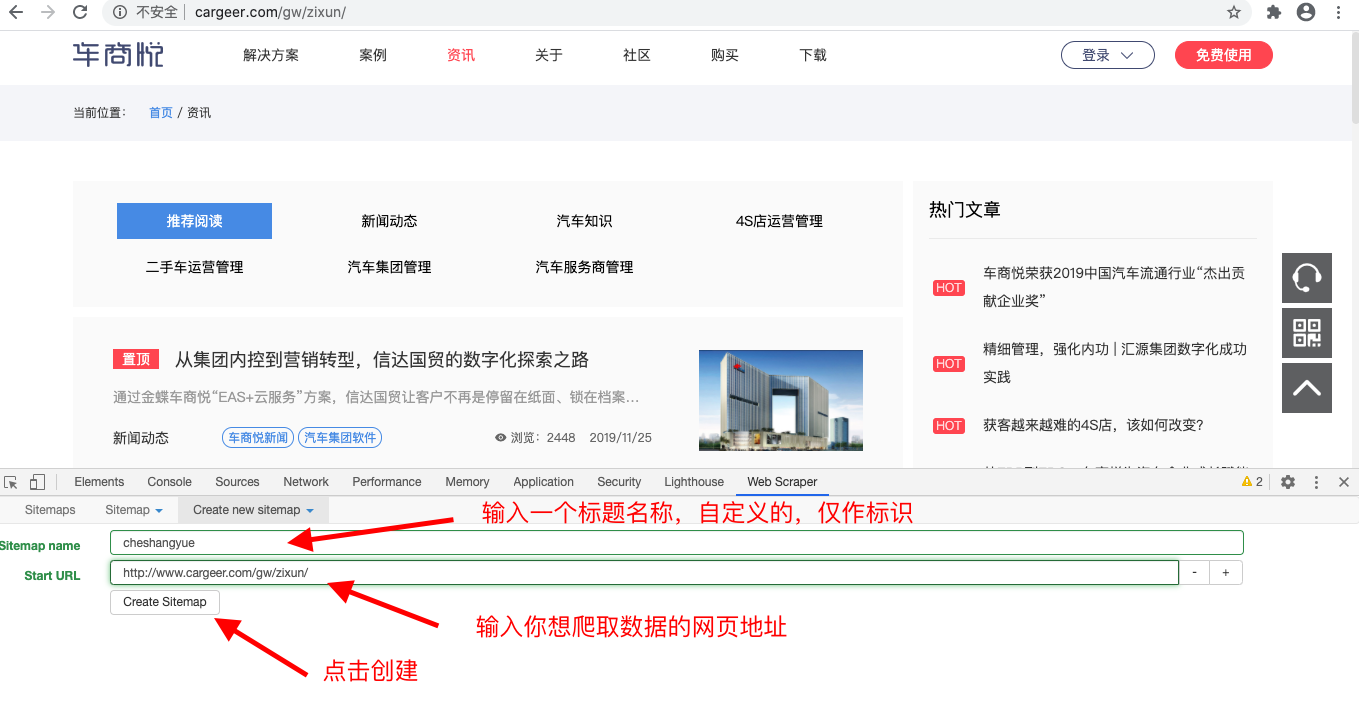
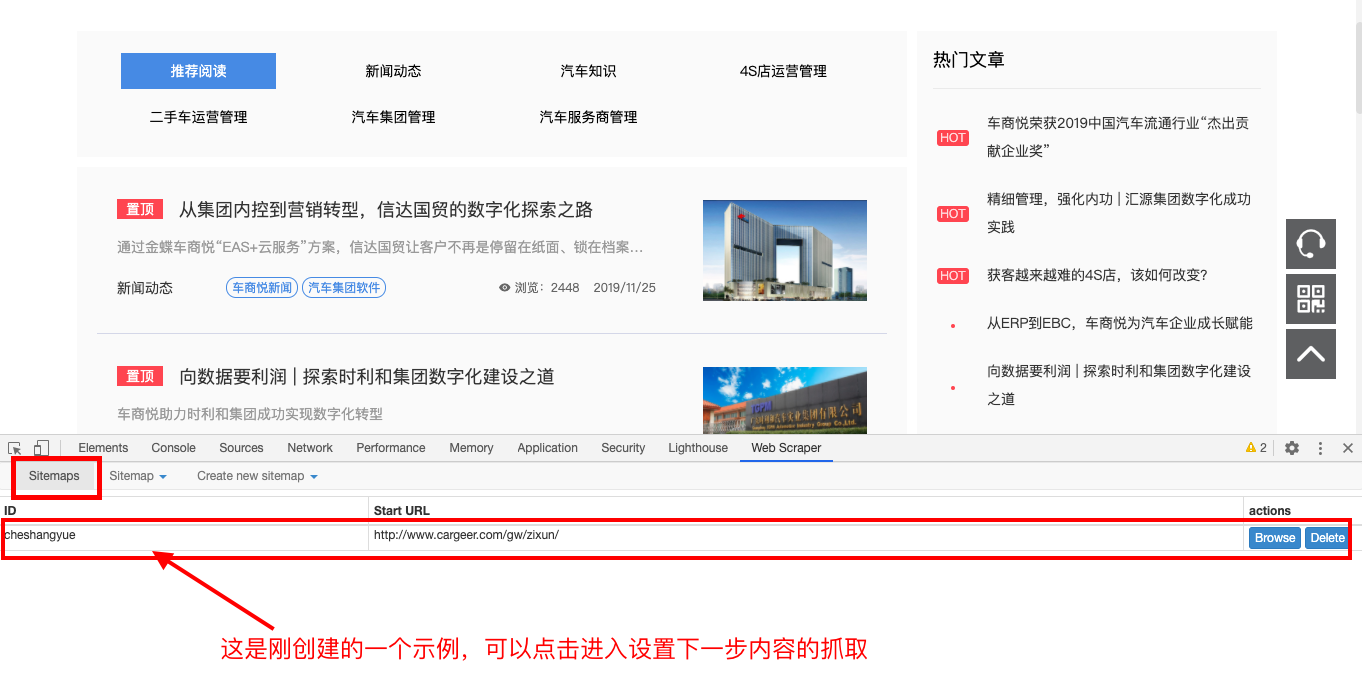
4、完整的操作过程如下:
操作视频获取地址:
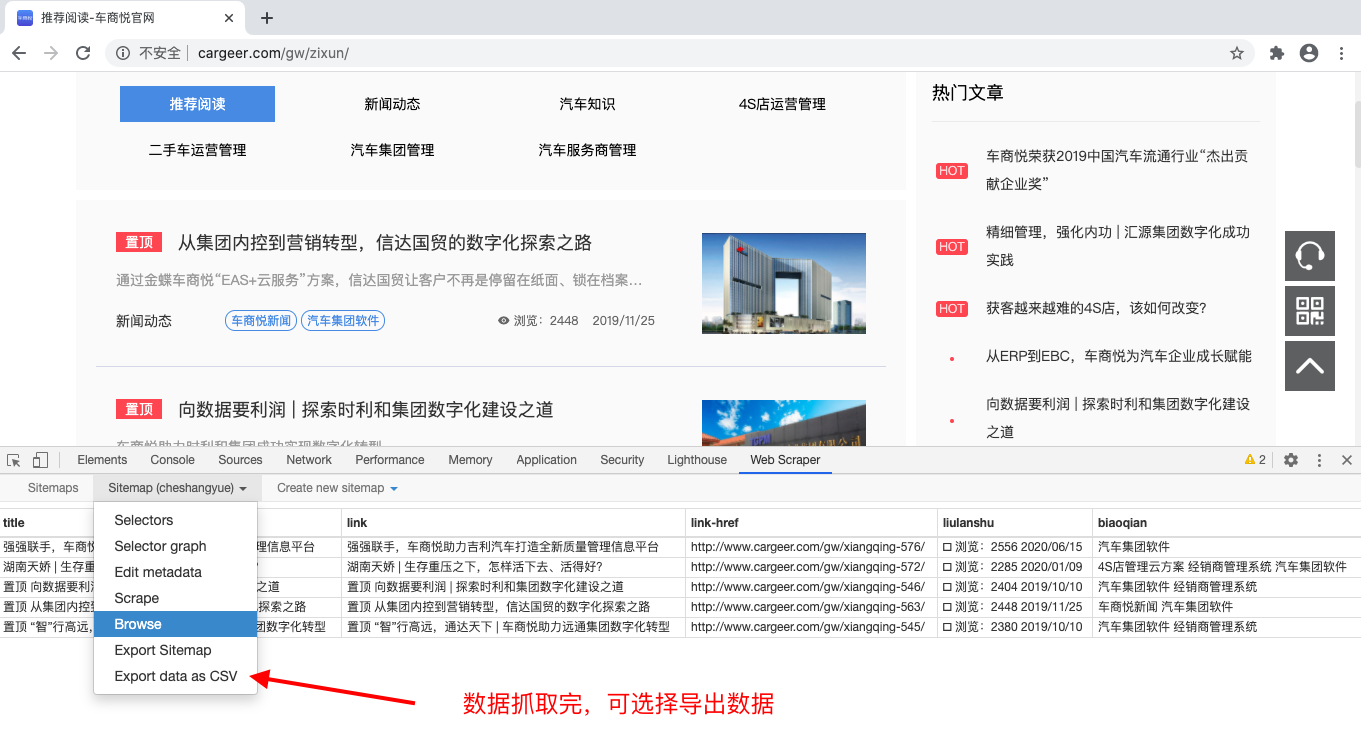
5、最后抓取的数据,可以选择导出
6、以上只是抓取了一页的数据,若想抓取多页(涉及翻页),可以用以下方法解决
在此仅列举一种方法,还有其他方法可自行百度查询
-
如下图所示,我点击翻页,该网页地址会呈现有规律的改变
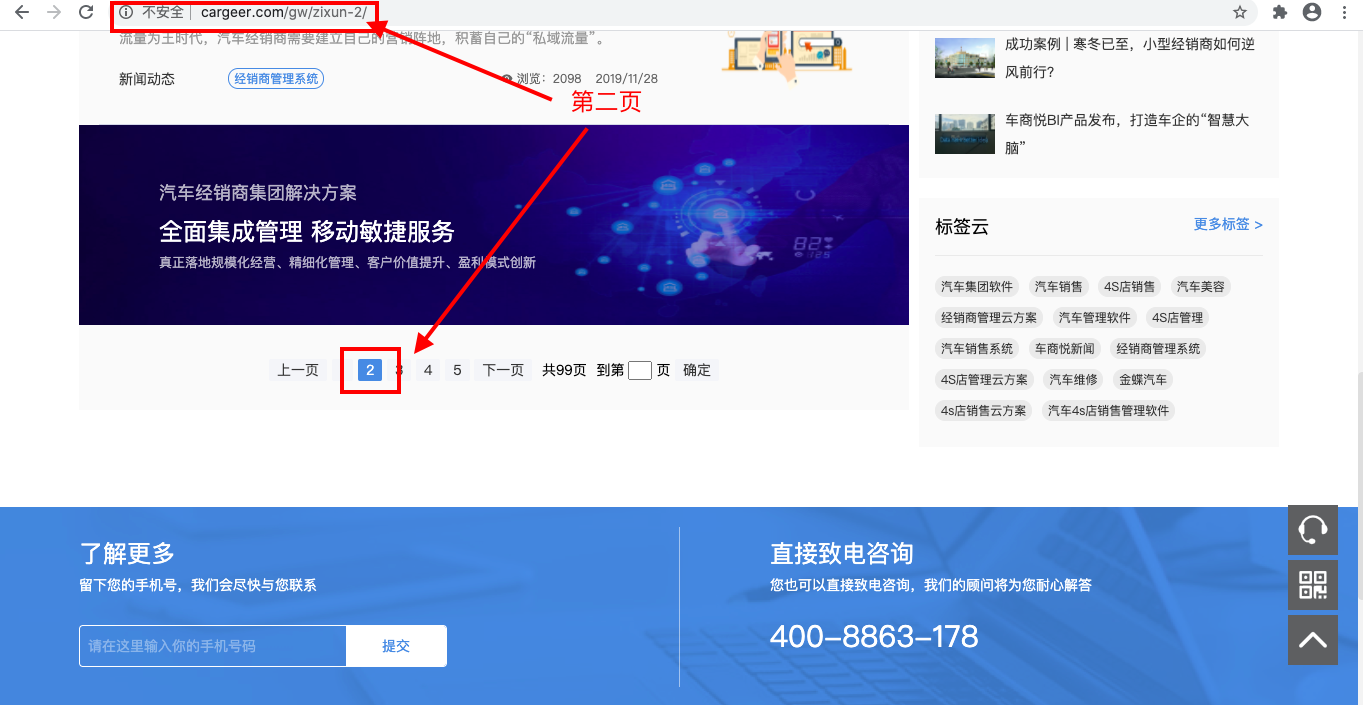
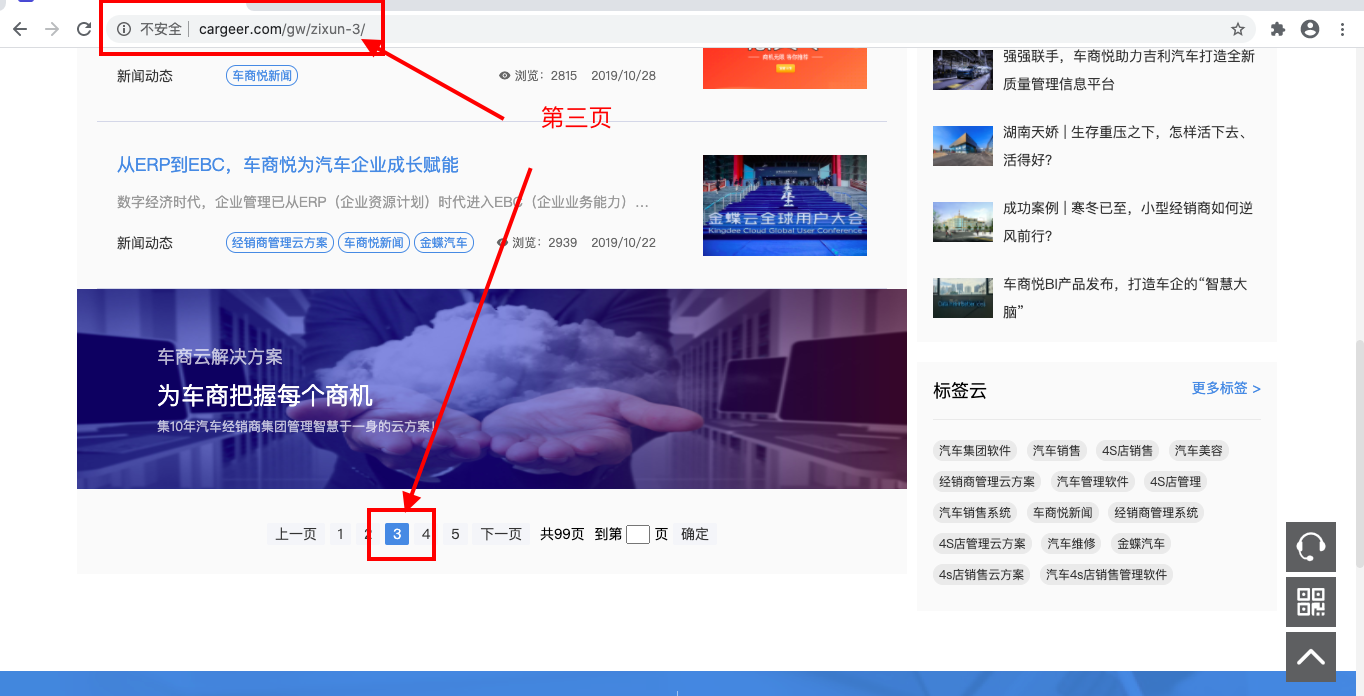
-
然后我只需要修改一下我要抓取数据的网页地址,在路径后面添加一个范围即可,如下图:
1、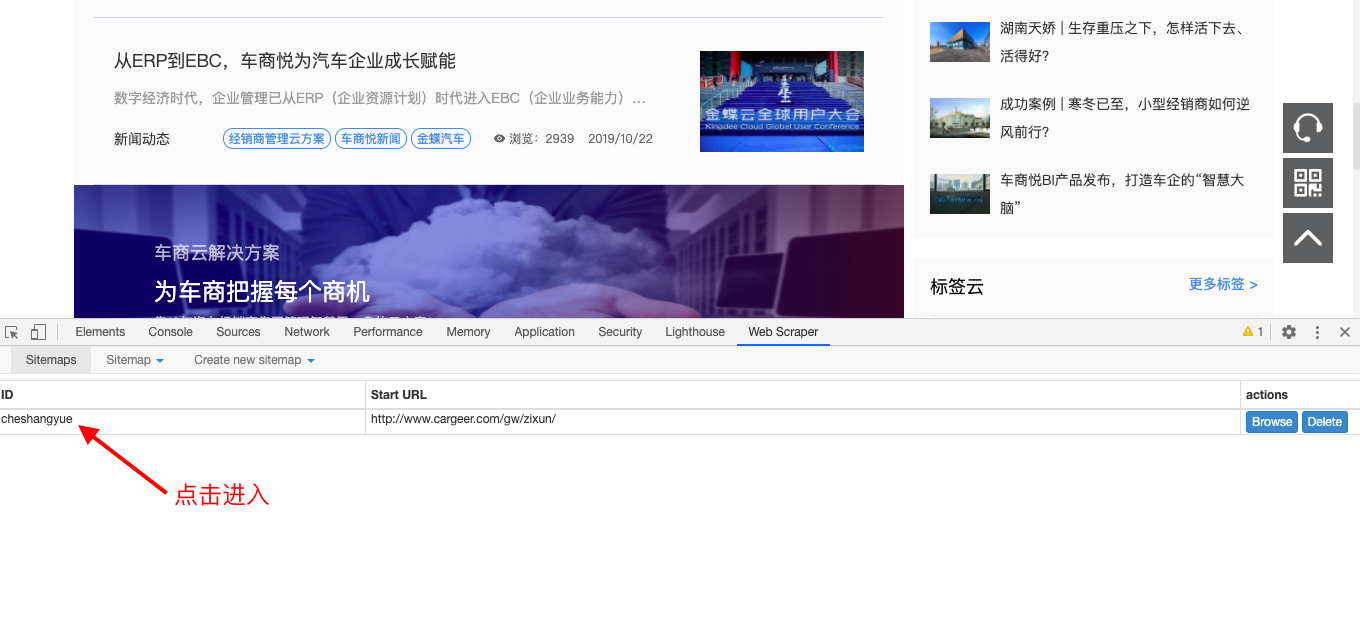
2、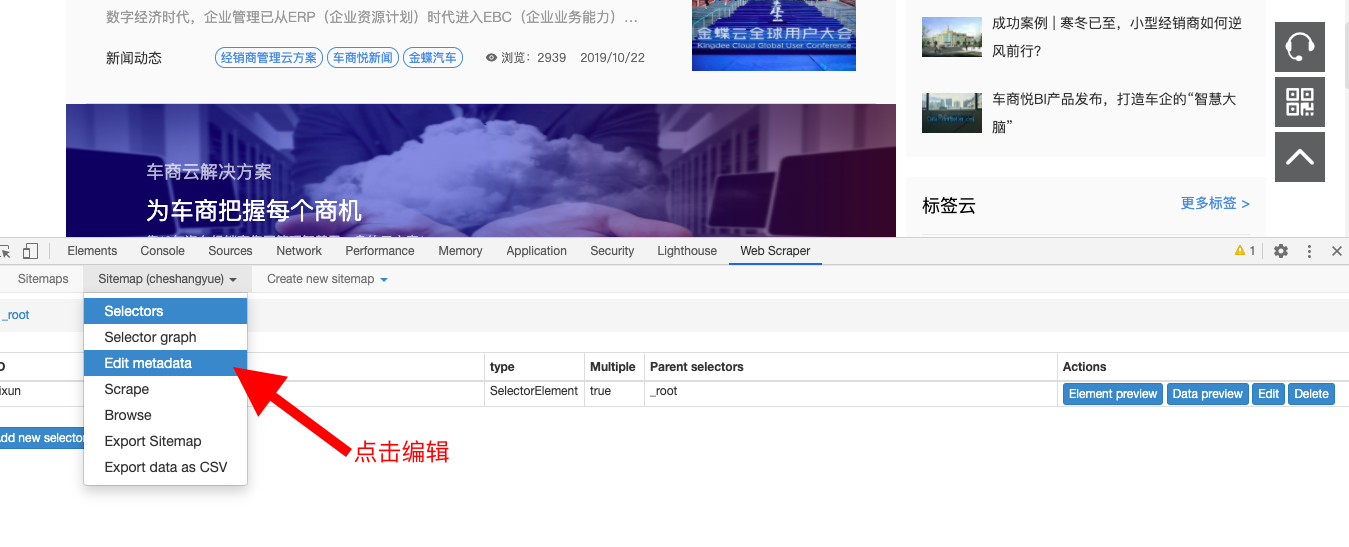
3、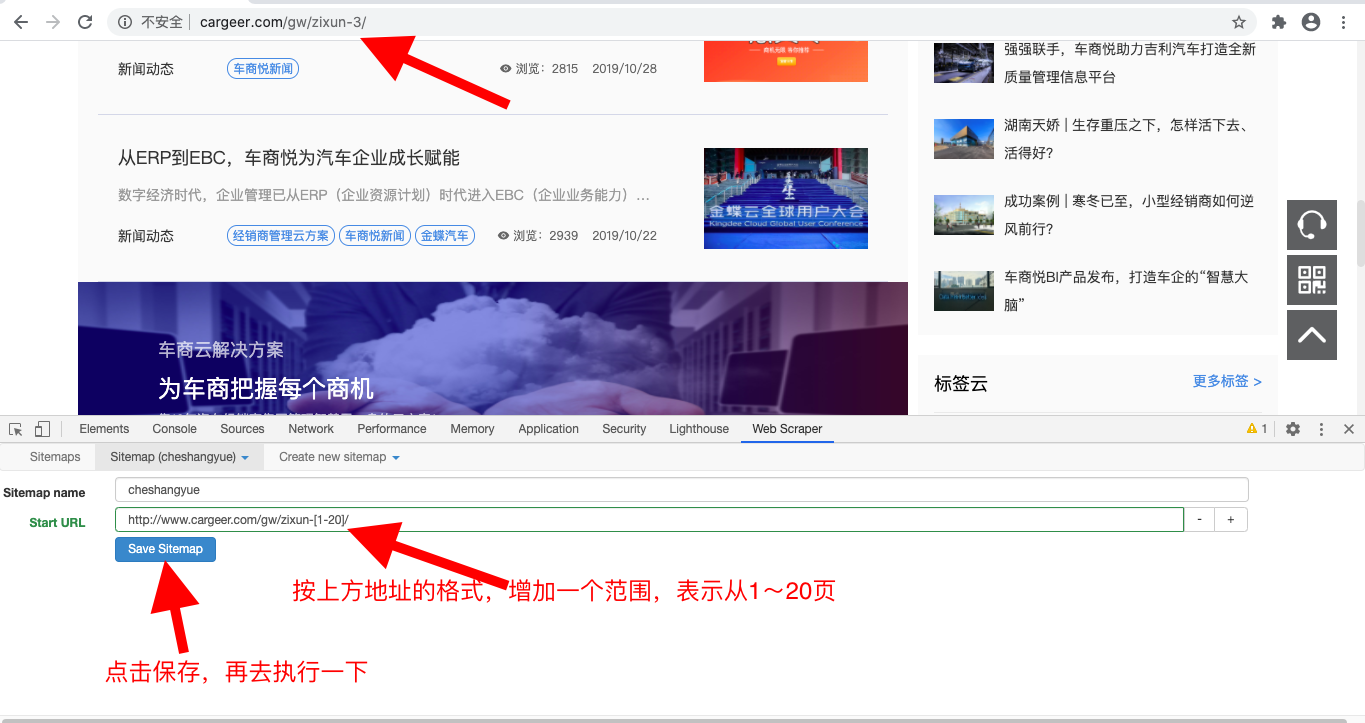
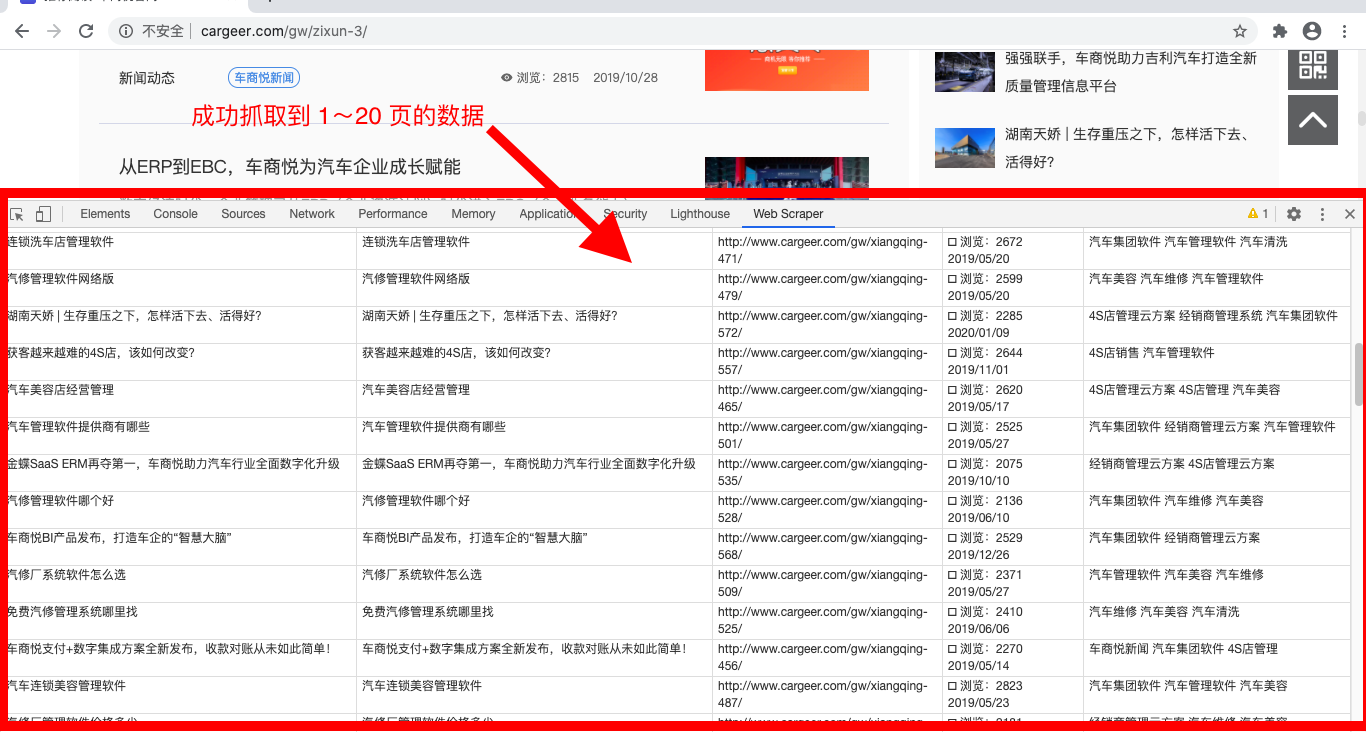
7、查看爬取结果
参考
如何使用web scraper收集大量微博信息
Web Scraper官网教程
翻页选择器Element click selector --webscraper操作手册
Web Scraper 使用教程(五)- 进阶用法(Element scroll down)
简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
介绍一款好用又易学的爬虫工具:web scraper
Web Scraper教程
Web scraper 爬虫傻瓜教程(不断更新中)
————————————————

















 3582
3582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









