1. 多头注意力
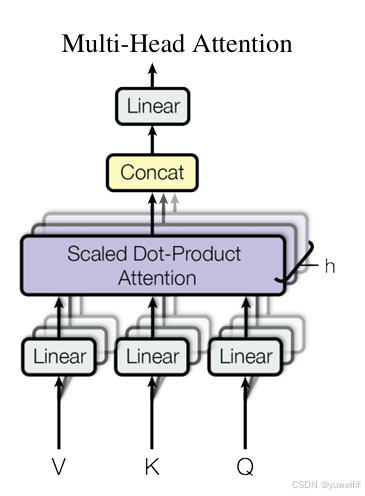

2. 并行计算的维度
2.1 头间并行
- 原理:由于每个头的计算是相互独立的,即不同头的投影、注意力分数计算和输出计算过程互不影响,因此可以在多个计算设备(如 GPU 核心)上并行地计算各个头的结果。例如,在一个具有多个 GPU 核心的系统中,可以将每个头分配给一个独立的核心进行计算。
- 优点:这种并行方式可以显著提高计算效率,因为多个头可以同时进行计算,减少了总的计算时间。而且实现相对简单,只需要将不同头的计算任务分配到不同的计算资源上即可。
2.2 批次并行
- 原理:在处理多个样本组成的批次数据时,不同样本之间的多头注意力计算也是相互独立的。因此,可以在多个计算设备上并行地处理不同的样本。例如,将一个批次的样本平均分配到多个 GPU 上,每个 GPU 独立地对分配到的样本进行多头注意力计算。
- 优点:批次并行可以充分利用多个计算设备的计算资源,提高整体的计算吞吐量。尤其是在处理大规模数据集时,批次并行可以显著缩短训练时间。
3. pytorch实现
3.1 使用 torch.nn.DataParallel
import torch
import torch.nn as nn
# 定义多头注意力模块
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 定义投影矩阵
self.W_q = nn.ModuleList([nn.Linear(d_model, self.d_k) for _ in range(num_heads)])
self.W_k = nn.ModuleList([nn.Linear(d_model, self.d_k) for _ in range(num_heads)])
self.W_v = nn.ModuleList([nn.Linear(d_model, self.d_k) for _ in range(num_heads)])
self.W_o = nn.Linear(num_heads * self.d_k, d_model)
def forward(self, Q, K, V):
heads = []
for h in range(self.num_heads):
Q_h = self.W_q[h](Q)
K_h = self.W_k[h](K)
V_h = self.W_v[h](V)
attn_scores = torch.matmul(Q_h, K_h.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
attn_probs = torch.softmax(attn_scores, dim=-1)
head_output = torch.matmul(attn_probs, V_h)
heads.append(head_output)
# 拼接多头输出
concat_heads = torch.cat(heads, dim=-1)
output = self.W_o(concat_heads)
return output
# 初始化参数
d_model = 512
num_heads = 8
batch_size = 16
seq_len = 10
# 创建输入数据
Q = torch.randn(batch_size, seq_len, d_model)
K = torch.randn(batch_size, seq_len, d_model)
V = torch.randn(batch_size, seq_len, d_model)
# 创建多头注意力模型
model = MultiHeadAttention(d_model, num_heads)
# 使用 DataParallel 进行并行计算
if torch.cuda.device_count() > 1:
print(f"Using {torch.cuda.device_count()} GPUs!")
model = nn.DataParallel(model)
model.cuda()
# 将输入数据移动到 GPU
Q = Q.cuda()
K = K.cuda()
V = V.cuda()
# 前向传播
output = model(Q, K, V)
print("Output shape:", output.shape)
3.2 使用 torch.nn.DistributedDataParallel
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
# 定义多头注意力模块
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 定义投影矩阵
self.W_q = nn.ModuleList([nn.Linear(d_model, self.d_k) for _ in range(num_heads)])
self.W_k = nn.ModuleList([nn.Linear(d_model, self.d_k) for _ in range(num_heads)])
self.W_v = nn.ModuleList([nn.Linear(d_model, self.d_k) for _ in range(num_heads)])
self.W_o = nn.Linear(num_heads * self.d_k, d_model)
def forward(self, Q, K, V):
heads = []
for h in range(self.num_heads):
Q_h = self.W_q[h](Q)
K_h = self.W_k[h](K)
V_h = self.W_v[h](V)
attn_scores = torch.matmul(Q_h, K_h.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
attn_probs = torch.softmax(attn_scores, dim=-1)
head_output = torch.matmul(attn_probs, V_h)
heads.append(head_output)
# 拼接多头输出
concat_heads = torch.cat(heads, dim=-1)
output = self.W_o(concat_heads)
return output
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
def run(rank, world_size):
setup(rank, world_size)
# 初始化参数
d_model = 512
num_heads = 8
batch_size = 16
seq_len = 10
# 创建输入数据
Q = torch.randn(batch_size, seq_len, d_model).to(rank)
K = torch.randn(batch_size, seq_len, d_model).to(rank)
V = torch.randn(batch_size, seq_len, d_model).to(rank)
# 创建多头注意力模型
model = MultiHeadAttention(d_model, num_heads).to(rank)
ddp_model = DDP(model, device_ids=[rank])
# 前向传播
output = ddp_model(Q, K, V)
print(f"Rank {rank} Output shape:", output.shape)
cleanup()
if __name__ == "__main__":
world_size = torch.cuda.device_count()
mp.spawn(run, args=(world_size,), nprocs=world_size, join=True)

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









