




PCA是一种常用的数据降维算法,主要就是根据特征值提出特征值较大的几个特征向量,并将高维向量投影到特征向量上以达到数据降维的目的。
第一步当然是处理数据,将样本数据按列放入numpy的数据框(比如100个样本,每个样本4个数据,就是4行100列,反过来也可以,不过要注意调换内积的顺序)。
数据需要先做归一化,以减去所有样本的均值来实现。
from sklearn.datasets import load_iris
iris = load_iris()
data = iris['data']
data = data-np.mean(data, axis=0)
然后要计算出协方差矩阵,并计算出特征值及特征向量
def get_eigen(data):
data_cov = np.cov(data, rowvar=0)
eigen_val, eigen_vec = np.linalg.eig(data_cov)
return eigen_val, eigen_vec
然后对特征值排序,提出特征向量
def sort_eigen(eigen_val, eigen_vec, cut_num):
index = np.argsort(-eigen_val)
sort_vec = eigen_vec[:, index[:cut_num]]
return sort_vec
最后计算样本投到这里的新值
result = np.dot(data, sort_vec)
成功将四维数据压缩至二维:
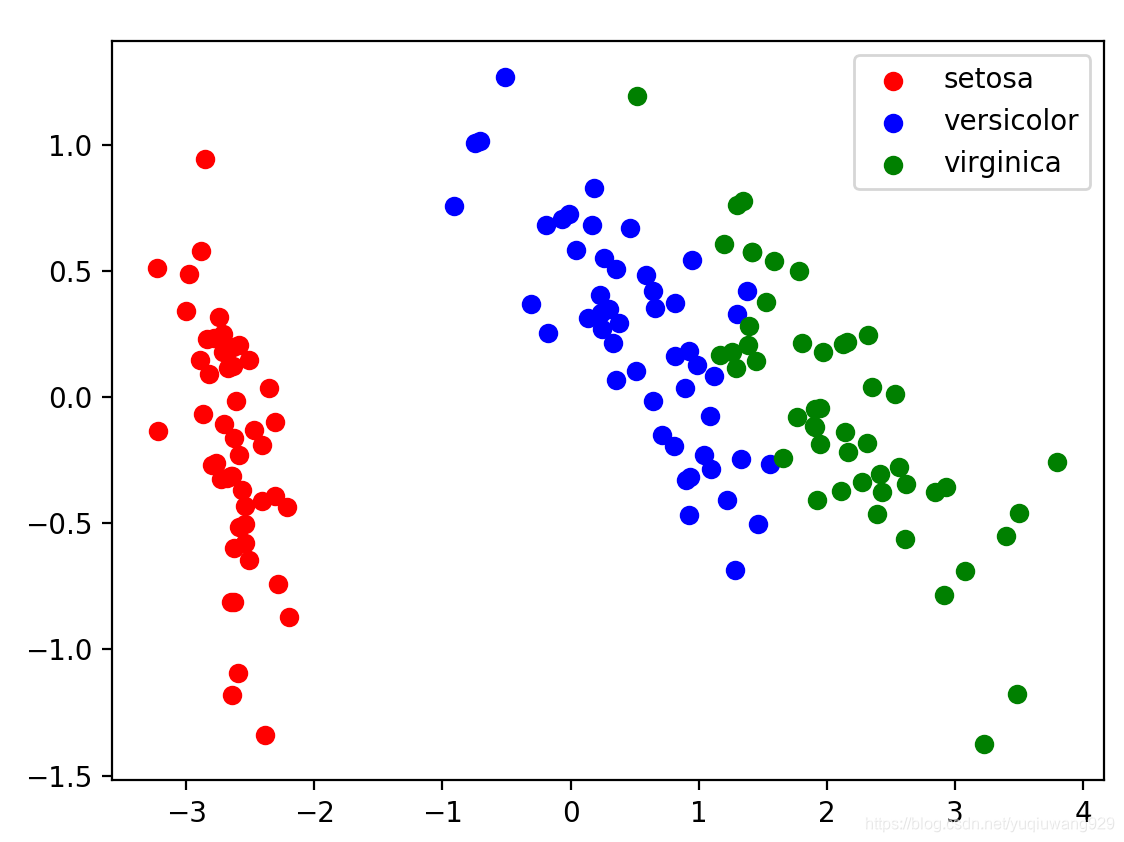
代码如下:
#!/usr/local/bin/python3
# -*- coding: UTF-8 -*-
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
def get_eigen(data):
data_cov = np.cov(data, rowvar=0)
eigen_val, eigen_vec = np.linalg.eig(data_cov)
return eigen_val, eigen_vec
def sort_eigen(eigen_val, eigen_vec, cut_num):
index = np.argsort(-eigen_val)
sort_vec = eigen_vec[:, index[:cut_num]]
return sort_vec
if __name__ == '__main__':
iris = load_iris()
data = iris['data']
data = data - np.mean(data, axis=0)
_val, _vec = get_eigen(data)
_vec = sort_eigen(_val, _vec, 2)
result = np.dot(data, _vec)
print(result)
colors = ["r", "b", "g"]
labels = list(set(iris['target']))
for idx, label in enumerate(labels):
plt.scatter(result[iris['target'] == label][:, 0], result[iris['target'] == label][:, 1], c=colors[idx],
label=iris['target_names'][idx])
plt.legend(loc='upper right')
plt.show()
在sklearn中也有封装pca方法,可以直接调用,以下方式会更简单
# -*- coding: utf-8 -*-
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
iris = load_iris()
pca = PCA(n_components=2)
datas = pca.fit_transform(iris['data'])
labels = list(set(iris['target']))
colors = ["r", "b", "g"]
plt.figure(figsize=(16, 10))
for idx, label in enumerate(labels):
plt.scatter(datas[iris['target']==label][:, 0], datas[iris['target']==label][:, 1], c=colors[idx], label=iris['target_names'][idx])
plt.legend(loc='upper right')
plt.savefig("iris.png")

















 2449
2449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









