









ArrayList使用forEach遍历的时候删除元素会报错吗?
答:其实不一定,如果删除的元素是倒数第二个则不会报错,
否则报错ConcurrentModificationException。
原因:举个栗子
List<String> lists = new ArrayList<String>();
lists.add("1");
lists.add("2");
lists.add("3");
lists.add("4");如果要删除等于“3”的元素,我们都知道ArrayList底层是类似数组的形式才存储数据的,生成一个元素后,后面的元素要往前移动,同时lists的size减1。这时lists变成[“1”,“2”,“4”],大小为3。
使用forEach遍历时:
for(String s :lists){
if(s.equals("3")){
lists.remove(s);
}
}
//这是一颗语法糖,编译后相当于:
for(Iterator i = lists.iterator();i.hasNext();){
String s = (String)i.next();
if(s.equals("3")){
list.remove(s);
}
}Iterator的hasNext()方法判断了size和当前下标cursor是否一样,一样则说明已经没有元素了。
如果remove了“3”这个元素之后,size会变成3,这时候遍历的下标cursor刚好是3,因此不会再进行下一次循环,直接结束了,此时元素“4”是没有被遍历到的。
假如lists中的元素是[“1”,“2”,“3”,“4”,“5”],即3不再是倒数第二个元素了呢?
此时会进行下一次循环,先判断i.hasNext(),发现当前下标cursor不等于size,执行i.next(),试图取出下一个值“4”,这时候就报错了,原因在i.next()中:
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}Iterator取下一个值时候会先判断modCount是否和expectedModCount一样,不一样就报错。
这里的modCount是删除的元素的数量计数,expectedModCount是Iterator期望的删除数量,使用Iterator的remove()方法的时候,Iterator会将调用ArrayList.this.remove(lastRet)删除元素同时使得modCount++,然后将modCount的值赋给expectedModCount,确保它们一样。
所以到这里我们就可以发现问题了,在forEach循环体里,我们直接使用的是lists.remove(“3”)的方法来删除元素,导致了expectedModCount和modCount不一致。
所以要在遍历的时候删除元素,不能使用forEach遍历的方式,要使用Iterator的方法。
下面是修改后的代码:
String s= null;
for(Iterator i = lists.iterator(); i.hasNext(); ){
s=(String)i.next();
if(s.equals("3")){
i.remove();
}
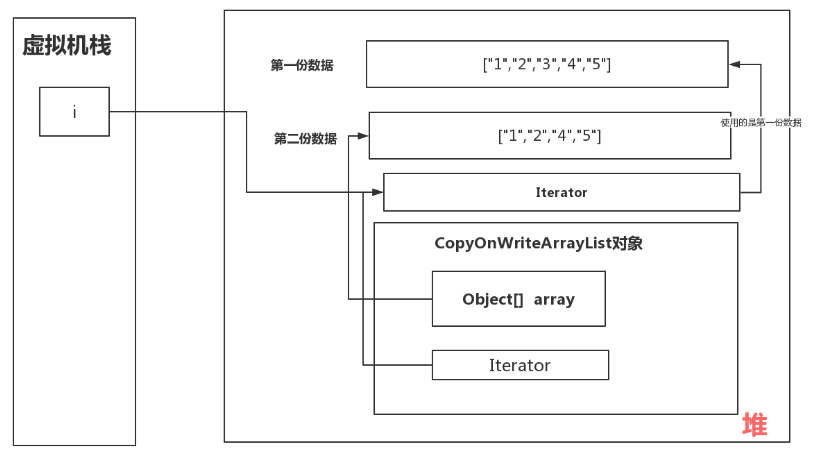
}还有一种方法是使用CopyOnWriteArrayList代替ArrayList,这是一种写时复制的容器,每次添加删除元素的时候都会复制一份旧的数据,新建一个新数据,在新数据进行修改后再修改旧数据的指针指到新数据。这样的话,遍历的数据其实都是第一份的旧数据,旧数据是没有变的,我们使用旧数据遍历,使用新数据判断值。
画个图表达下我的理解:
为帮助开发者们提升面试技能、有机会入职BATJ等大厂公司,特别制作了这个专辑——这一次整体放出。
大致内容包括了: Java 集合、JVM、多线程、并发编程、设计模式、Spring全家桶、Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、MongoDB、Redis、MySQL、RabbitMQ、Kafka、Linux、Netty、Tomcat等大厂面试题等、等技术栈!
需要获取以下这些面试题答案以及学习资料得话麻烦关注+好评之后
直接点击此链接→【点我直接获取】 即可免费获取哦~~

看完三件事❤️
- 如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
- 点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
- 关注作者公众号 『 java烂猪皮 』,不定期分享原创知识。
- 关注后回复【666】扫码即可获取学习资料包。
- 同时可以期待后续文章ing🚀。


















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









