




姿态估计旨在 RGB 图片和 Video 中的人体像素映射到肢体的三维曲面(3D surface),其涉及了很多计算机视觉任务,如目标检测,姿态估计,分割,等等. 姿态估计的应用场景不仅包括关键点定位,如图形(Graphics),增强显示(Augmented Reality, AR),人机交互(Human-Computer Interaction,HCI),还包括 3D 目标识别的很多方面。
层出不穷的姿态检测深度网络模型,在最近两三年如雨后春笋般出现。今天我们选AlphaPose导出骨骼3D关键点位置,并在游戏引擎的去运行相关的模型。相关的代码都已提交到github, 我们提供算法解决视频2D到游戏3D骨骼的转换。算法不局限于抖音上的视频, 只是作者使用的视频都是从抖音上爬来的。
识别视频
首先将从抖音扒来的视频导入到模型,由AlphaPose生产识别后的运动姿势, 并使用Video3DPose中的方法渲染成视频, 如下:
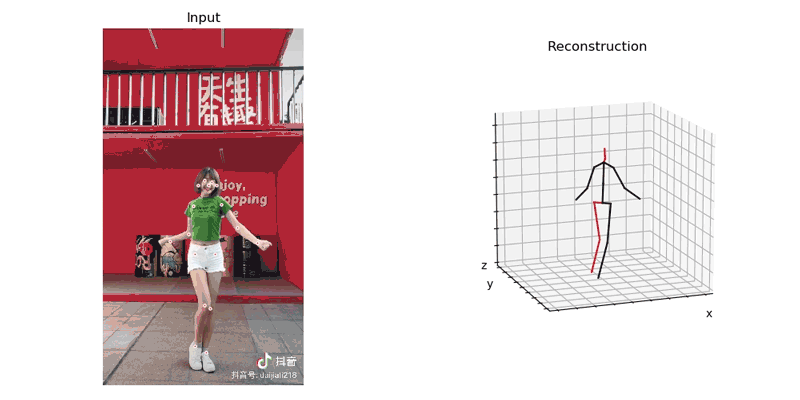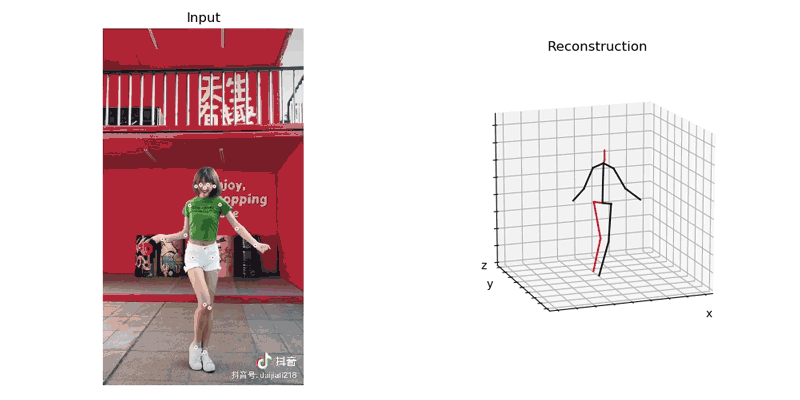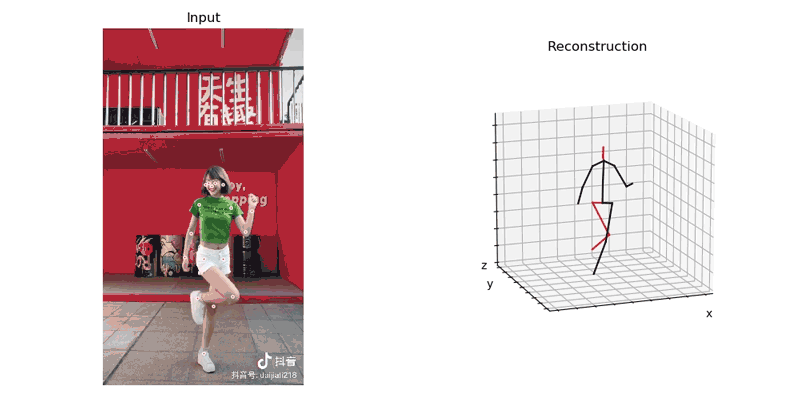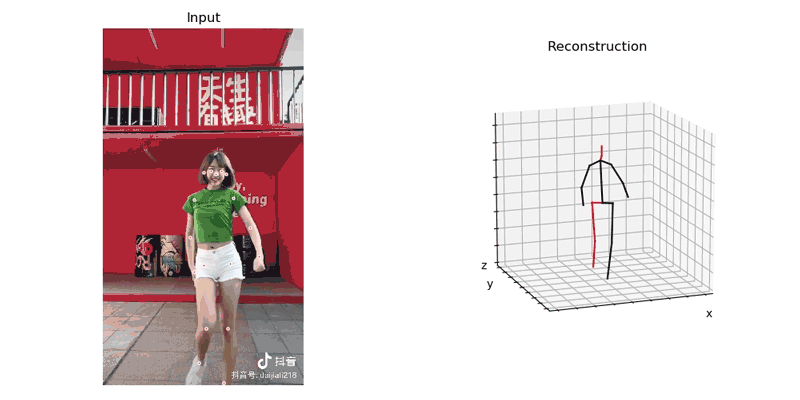
使用工具将numpy格式的数据转换成二进制(bytes), 以供之后在unity里解析使用。我们输出的时候查看numpy对象shape是(x,17,3), 地一维x代表帧数, 第二维代表17个关节,第三维代表关键点(joint)的3d位置。
Unity 运行模型
将上一步Python环境里生成的关键点信息(二进制文件),导入到Unity里,使用IO接口解析出来,由于Video3DPose默认使用的[hunman3.6数据集]骨骼的标记是17个部位,这里我们创建了17个GameObject,代表17个关节节点, 并使用LineRender组件把相关的关节连接成线。在Mono的Update函数,我们更新导出模型的3d关键点位置信息,于是一个运动的骨骼人行动起来了。 关于[hunman3.6数据集]关节编号的详细介绍,见本文最后的附录。
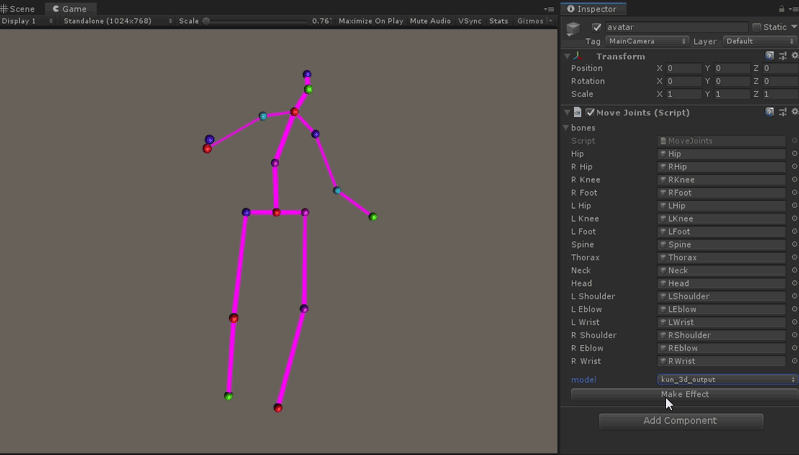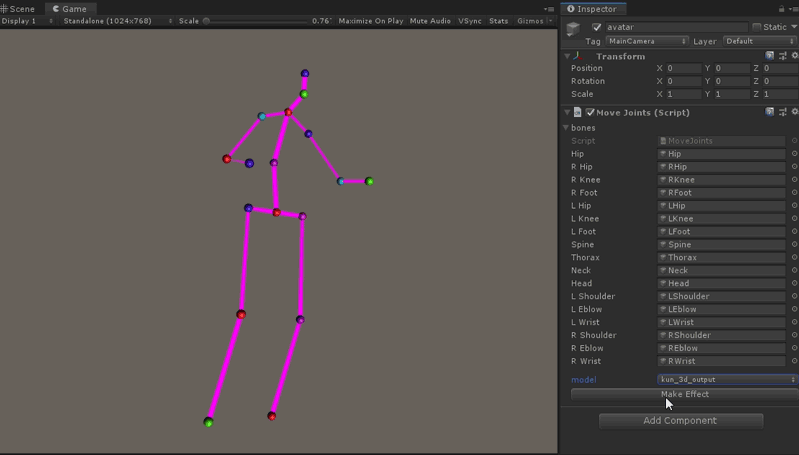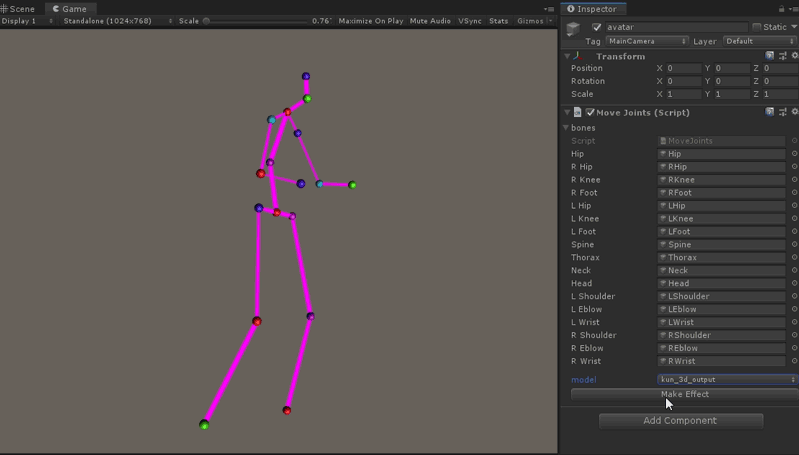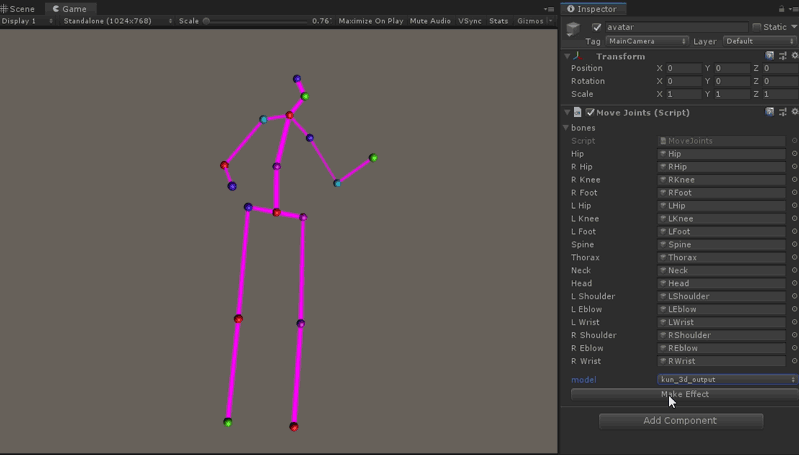
代码如下, 在Update中插值更新17组关节的位置,pose_joint数组的顺序对应到hunman3.6数据集关节编号。
protected override void LerpUpdate(float lerp)
{
Hip.position = Vector3.Lerp(Hip.position, pose_joint[0], lerp);
RHip.position = Vector3.Lerp(RHip.position, pose_joint[1], lerp);
RKnee.position = Vector3.Lerp(RKnee.position, pose_joint[2], lerp);
RFoot.position = Vector3.Lerp(RFoot.position, pose_joint[3 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7542
7542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









