







 该博客详细介绍了如何将Python爬虫与MySQL数据库结合,通过三步操作实现数据的存储。首先在MySQL中创建表格,接着在PyCharm中编写Python代码进行数据插入,运行后成功入库153条数据,最后验证数据库中数据的完整性和准确性。
该博客详细介绍了如何将Python爬虫与MySQL数据库结合,通过三步操作实现数据的存储。首先在MySQL中创建表格,接着在PyCharm中编写Python代码进行数据插入,运行后成功入库153条数据,最后验证数据库中数据的完整性和准确性。
第一步:在mysql数据库中创建如下表及字段,代码如下:

第二步:在软件编辑器中输入如下代码,我用的是pycharm:
#coding:utf-8
import requests
from lxml import etree
import pymysql,logging
class Mspider:
def __init__(self):
self.db=pymysql.connect(host='localhost',
user='root',
password='yuner806432',
port=3306,
database='notebook')
self.cursor=self.db.cursor()
def store(self,name,descrite,price,scoring,count):
self.cursor.execute("insert into book (name,descrite,price,scoring,count) values (%s,%s,%s,%s,%s)",(name,descrite,price,scoring,count))
self.db.commit()
logging.warning('这里')
def getPage(self,url,headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'GBK'
html = r.text
result = etree.HTML(html)
data=result.xpath('//ul[@id="J_PicMode"]/li')
for x in data:
name1 = x.xpath('h3/span/a/text()')
descrite1 = x.xpath('h3/a/text()')
price1=x.xpath('div[@class="price-row"]//span/b[@class="price-type"]/text()')
scoring1=x.xpath('div[@class="comment-row"]/span[@class="score"]/text()')
count1=x.xpath('div[@class="comment-row"]//a[1]/text()')
#定义一个lambda函数去除网页数据为空的干扰,所有空数据设为none。
func=lambda x:'none' if len(x)==0 else x[0]
price=func(price1)
name=func(name1)
descrite=func(descrite1)
scoring=func(scoring1)
count=func(count1)
logging.warning('运行正常')
#写入mysql数据库
self.store(name,descrite,price,scoring,count)
def __del__(self):
self.db.close()
url='https://detail.zol.com.cn/notebook_index/subcate16_list_1.html?from=360Sub1'
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
if __name__ == '__main__':
myspider=Mspider()
myspider.getPage(url,headers)
第三步:运行之后,运行结果无误。如图:
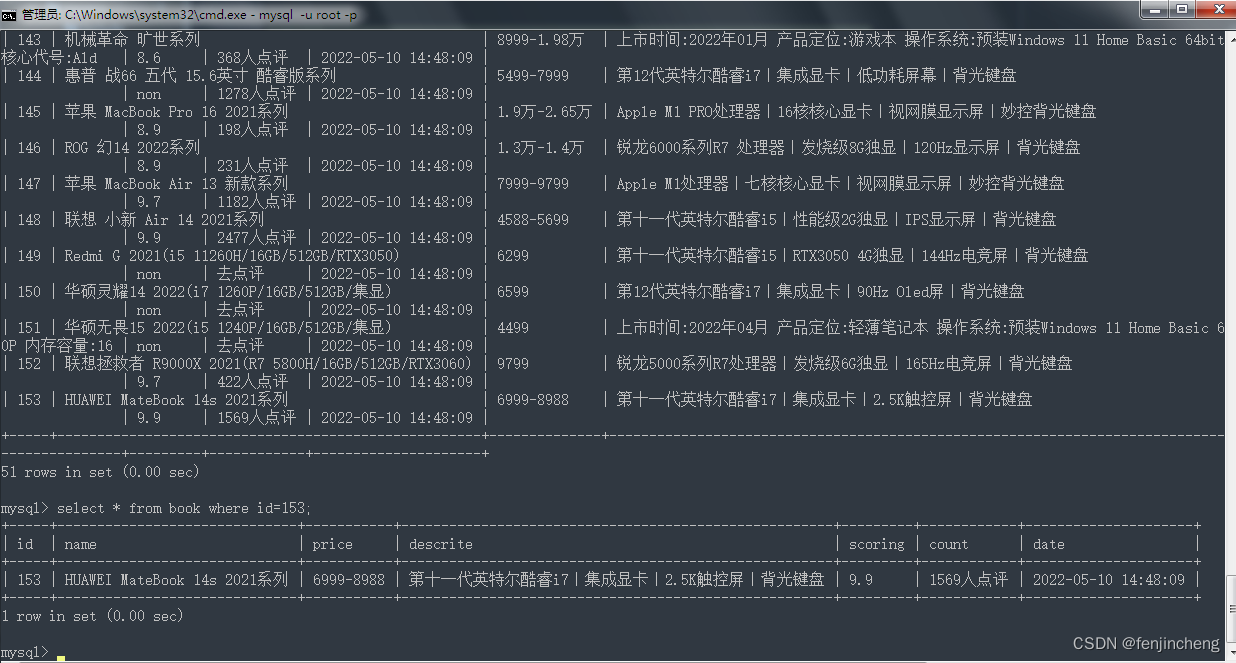
第四步:在数据库中查看数据,一切正常,输出了153条数据。
再单独查看了最后一条数据。结果如下:

















 1187
1187



 到【灌水乐园】发言
到【灌水乐园】发言







