






1. 基本语法
RANK() OVER (PARTITION BY <column_name> ORDER BY <column_name> ASC|DESC)
- PARTITION BY:如果你想按照某一列对数据进行分区,可以使用
PARTITION BY。每个分区内的数据排名将从 1 开始。如果不使用PARTITION BY,则排名会在整个结果集上生成。 - ORDER BY:决定排名的顺序,通常是基于某个列的升序(
ASC)或降序(DESC)来排序。
2. 关键点:
RANK()会对相同的值赋予相同的排名,并且会跳过后续的排名。例如,如果两个值并列第一,那么接下来的排名会跳到第三位,而不是第二位。- 它与
ROW_NUMBER()不同,后者不会跳过排名。
3. 更详细的示例:
假设我们有一个员工销售成绩表,包含以下字段:

我们将展示如何使用 RANK() 来按销售额为员工排名。
4. 示例 1:简单的 RANK() 排名
SELECT EmployeeName, SalesAmount,
RANK() OVER (ORDER BY SalesAmount DESC) AS Rank
FROM Sales;
解释:
- 我们按照
SalesAmount的降序来排序。 RANK()会为每一行分配一个排名。
结果:

说明:
Eve的销售额最大,所以她的排名是 1。Bob和Carol的销售额相同,所以他们都获得了排名 2。接下来,排名跳到 4,而不是 3。Alice和Dave的销售额分别为 1000 和 500,他们分别排在 4 和 5。
5. 示例 2:使用 PARTITION BY 分区排名
如果你希望按部门对员工进行分区并在每个部门内进行排名,你可以使用 PARTITION BY:
假设我们的表格现在多了一个 Department 字段:
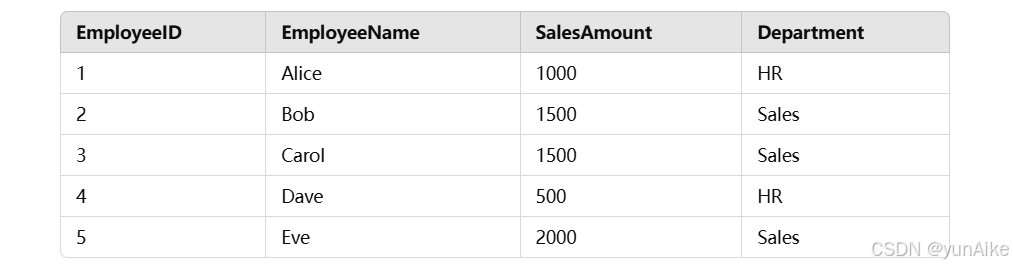
你可以按部门(Department)分区并排名:
SELECT EmployeeName, Department, SalesAmount,
RANK() OVER (PARTITION BY Department ORDER BY SalesAmount DESC) AS Rank
FROM Sales;
结果:
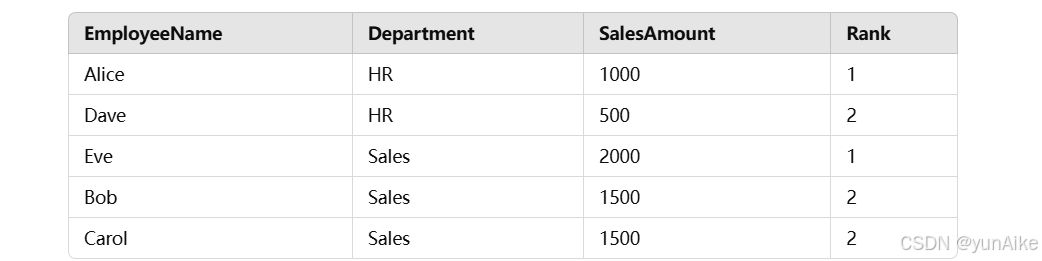
说明:
RANK()会在每个部门内独立排名。- 在
HR部门中,Alice排名第一,Dave排名第二。 - 在
Sales部门中,Eve排名第一,Bob和Carol排名第二。
6. 总结
RANK()可以用于为结果集中的数据排序并生成排名。- 对于重复的值,它会分配相同的排名,但跳过后续排名。
PARTITION BY使得可以在分组后单独生成排名,适用于按不同类别进行排名的场景。

















 4570
4570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









