







1、交叉熵函数:表达真实样本标签与预测概率之间的差值。
链接:简单的交叉熵损失函数,你真的懂了吗?_红色石头的专栏-优快云博客_交叉熵损失函数
2、softmax回归:假设目标分类结果有J种,softmax函数表达了当前样本在[1---J]这J中结果上的概率分布。
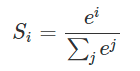
3、机器学习初始化权值W为何要随机生成很小的数字
机器学习初始化权值W为何要随机生成很小的数字_disasters的博客-优快云博客
初始化参数W和b时,通常使用一下代码:
W = np.random.randn((2,2)) * 0.01
b = np.zeros((2,1))
W是随机生成了符合高斯分布的数,再*0.01,使得W很小,
为何要随机生成? 因为如果像b一样全赋0值,就会产生对称性,假如hidden layer有两个由输入值产生的神经元,则由于对称性,无论是正向传播还是反向传播,这两个本应表示不同特征的神经元所做的运算都是一致的,即对称的,not well,所以随机生成了一些数赋值给矩阵W,计算b就不用担心对称性的问题,故直接赋0值
而*0.01使得W很小是因为,可以参照激活函数sigmoid和tanh,当W很大,用W * X+b=a得到的a很大,再用对a用激活函数如sigmoid(a),由于a很大了,sigmoid(a)中的a会趋向正无穷或负无穷,则函数值sigmoid(a)趋向于一个平缓的趋势,在梯度下降的时候计算的梯度很小,会导致学习的很慢,故使得W取一个很小的值(激活函数图sigmoid,tanh在网上可以很容易找到)。不过在某些情况下不取0.01.会取其他的比较小的值
4、神经网络优化算法综述
神经网络优化算法综述_YoungGy的专栏-优快云博客_神经网络优化算法综述
各种梯度下降算法
【深度学习】常见优化算法_shenxiaolu1984的专栏-优快云博客_常见优化算法
拟牛顿法
5、常用激活函数
https://www.chamwen.com/2019/01/07/ML_activate/
6、CNNs中激活函数为什么用relu
为什么在CNNs中激活函数选用ReLU,而不用sigmoid或tanh函数?_benniaofei18的博客-优快云博客_rnn激活函数为啥不用sigmoid
a、反向传播求梯度时计算量小
b、sigmoid容易出现梯度消失
c、relu使一部分元素为0,能防止过拟合
7、为什么用tanh

















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









