







 在Swift开发中,如果遇到只有OC版本的大型SDK或包,如MBProgressHUD,可以通过创建桥接文件来引入。首先,使用CocoaPods在Podfile中添加MBProgressHUB,然后执行podinstall。接着,创建并配置桥接头文件(.h),在其中引入OC库,这样整个项目就能使用这些OC库的功能了。
在Swift开发中,如果遇到只有OC版本的大型SDK或包,如MBProgressHUD,可以通过创建桥接文件来引入。首先,使用CocoaPods在Podfile中添加MBProgressHUB,然后执行podinstall。接着,创建并配置桥接头文件(.h),在其中引入OC库,这样整个项目就能使用这些OC库的功能了。
使用Swift进行iOS开发的小伙伴在开发过程中有没有遇到过这样一个问题,当想使用一些大型SDK或者GitHub里较出名的包时,发现这些包都是用OC写的,并没有Swift的版本,其中的缘由是iOS开发经历了两个时期,第一个时期是使用OC开发,第二个时期就是使用Swift开发,目前使用Swift开发逐渐变成主流,但很多OC的包还没有重构成Swift版本,那么当我们想使用这些OC写的第三方包时该怎么办呢?这时候我们就可以通过桥接文件来将OC代码变成Swift语法来使用。
就以一个较为出名的包举例:MBProgressHUD,该功能包常用于写加载框及提示框功能,且经常维护,但目前还未重构成Swift版本。
具体操作如下:
一、通过cocoapods导入MBProgressHUD
1.在Podfile文件中写入命令
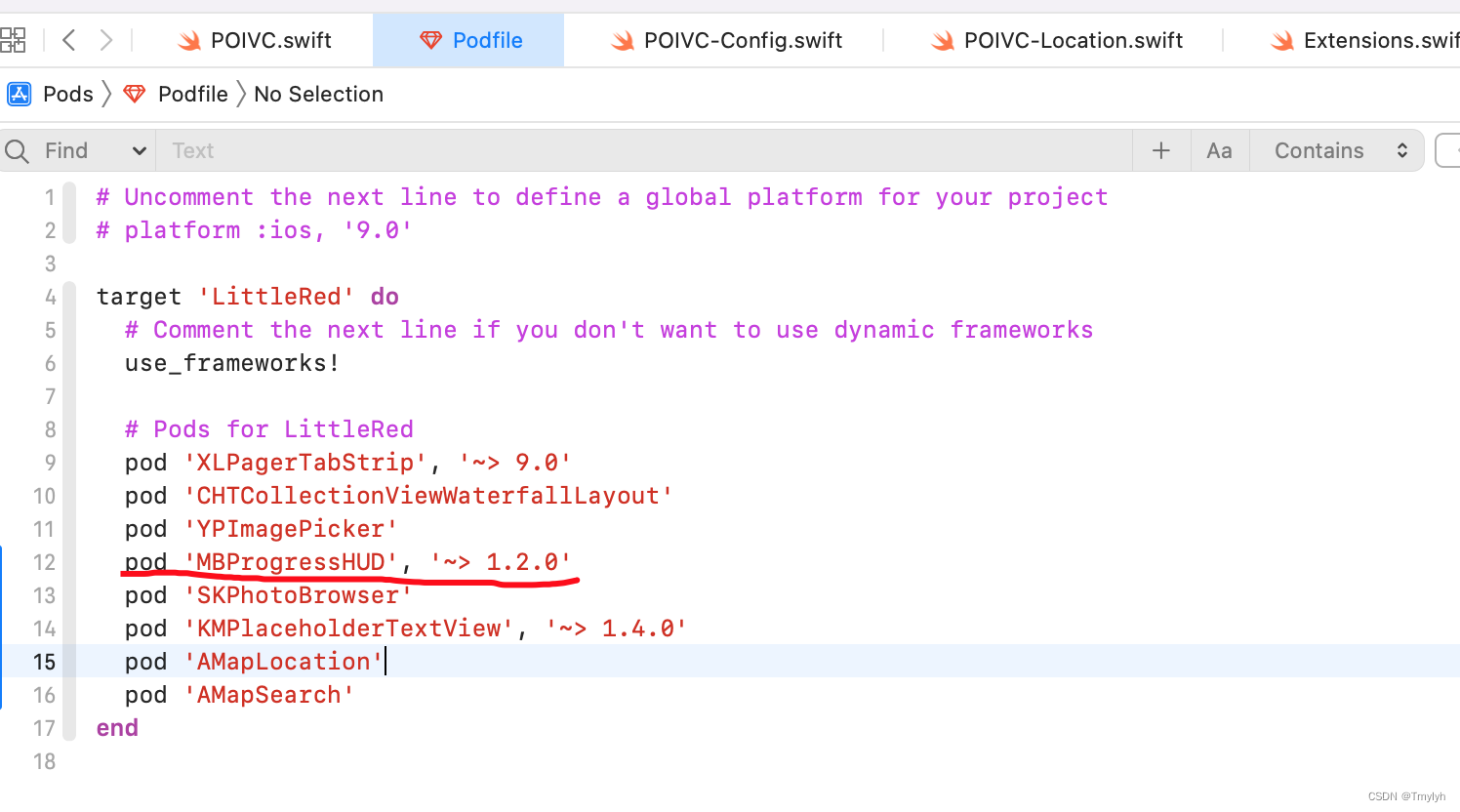
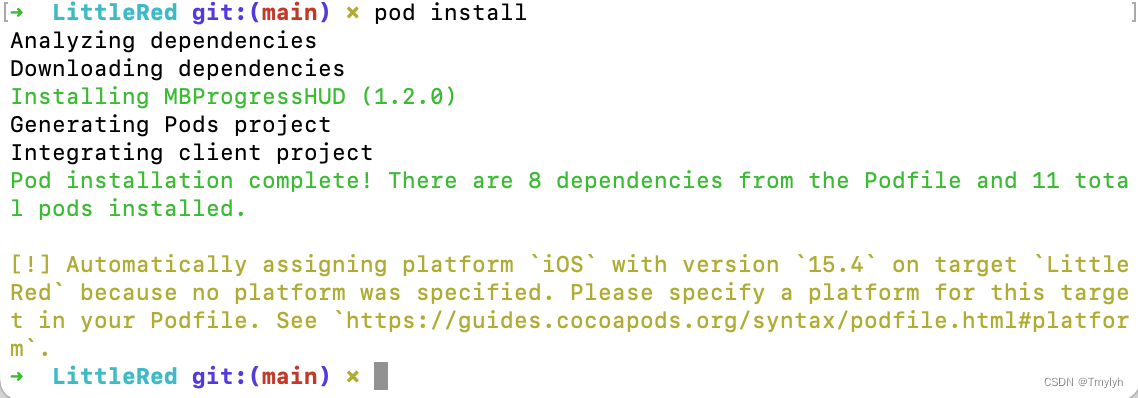
2.在终端执行pod install 命令引入该OC包
二、创建桥接文件-连接OC和Swift的文件
官方文档:https://developer.apple.com/documentation/swift/importing-objective-c-into-swift
1.创建.h文件
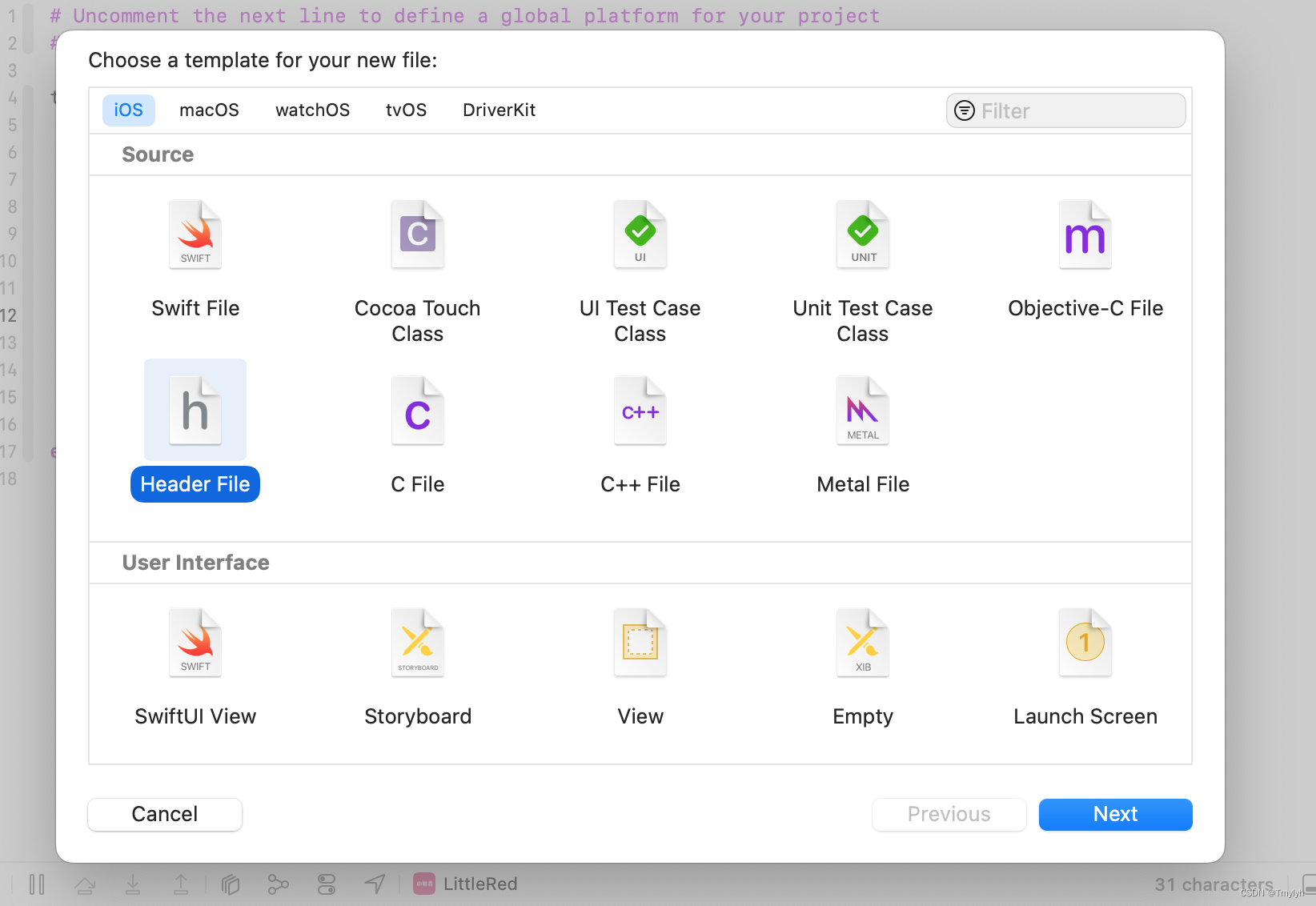
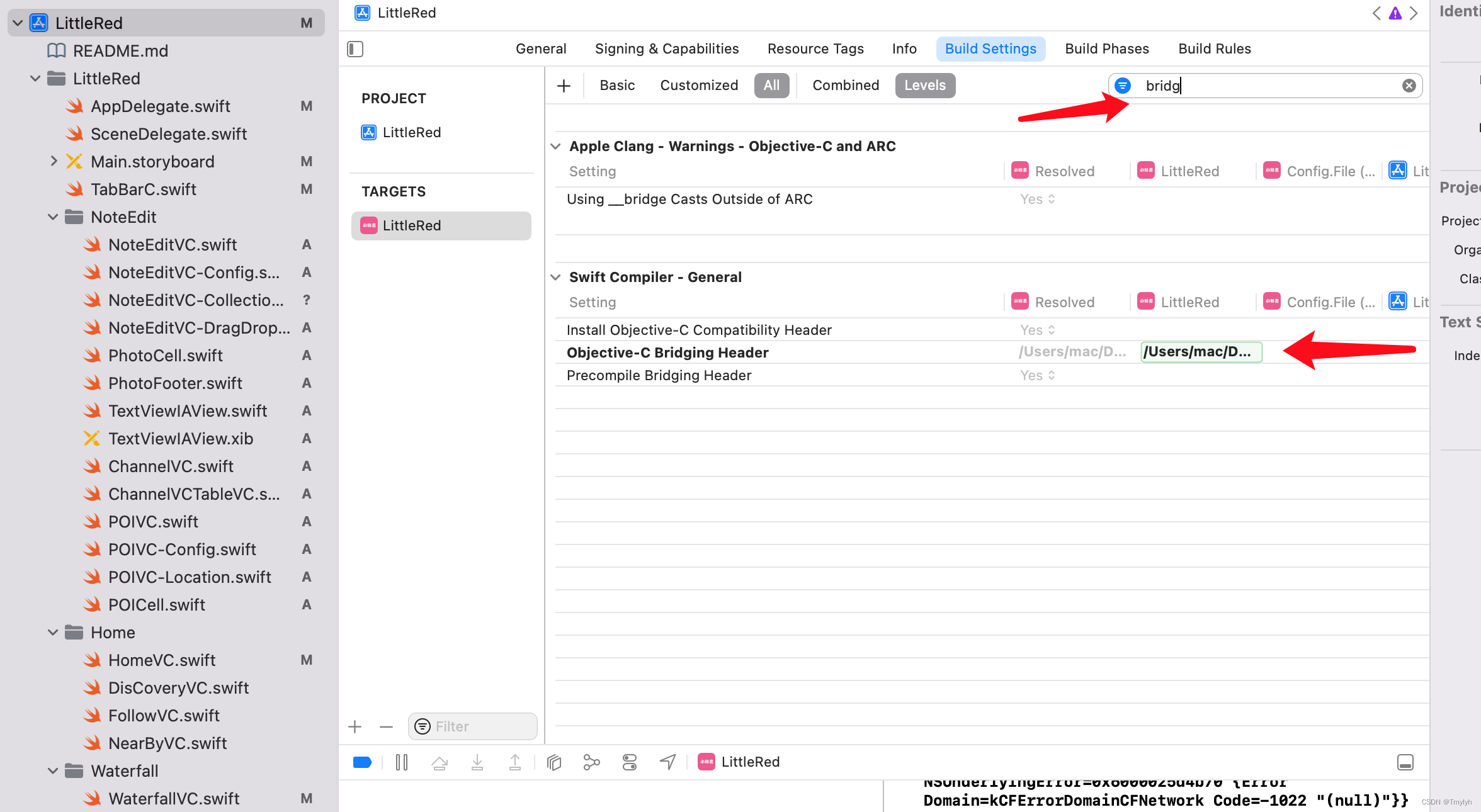
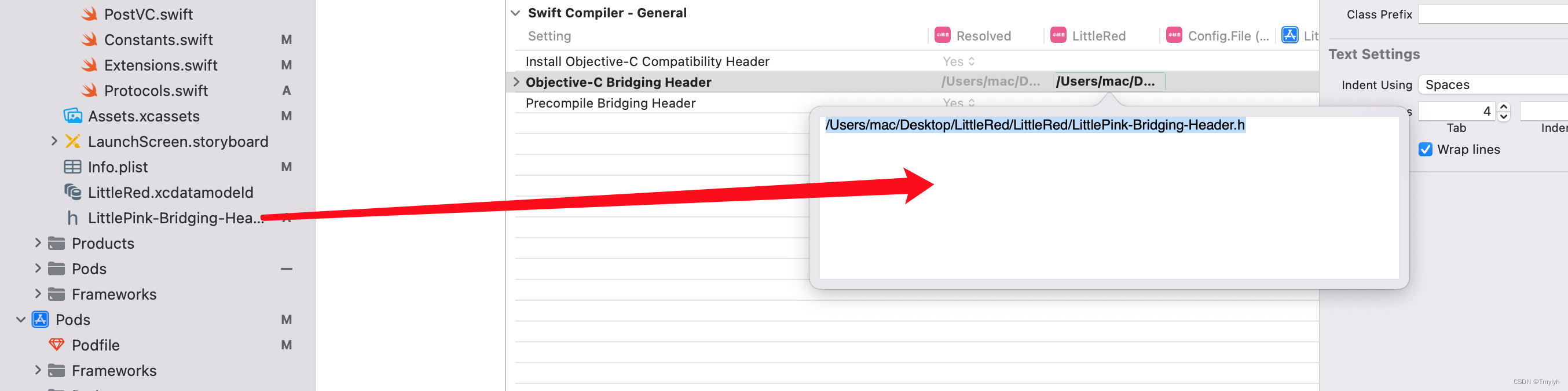
2.设置路径
创建好桥接文件后,进入项目找到OC Bridging Header,点击第二个,将桥接文件直接拖入编辑框设置路径。
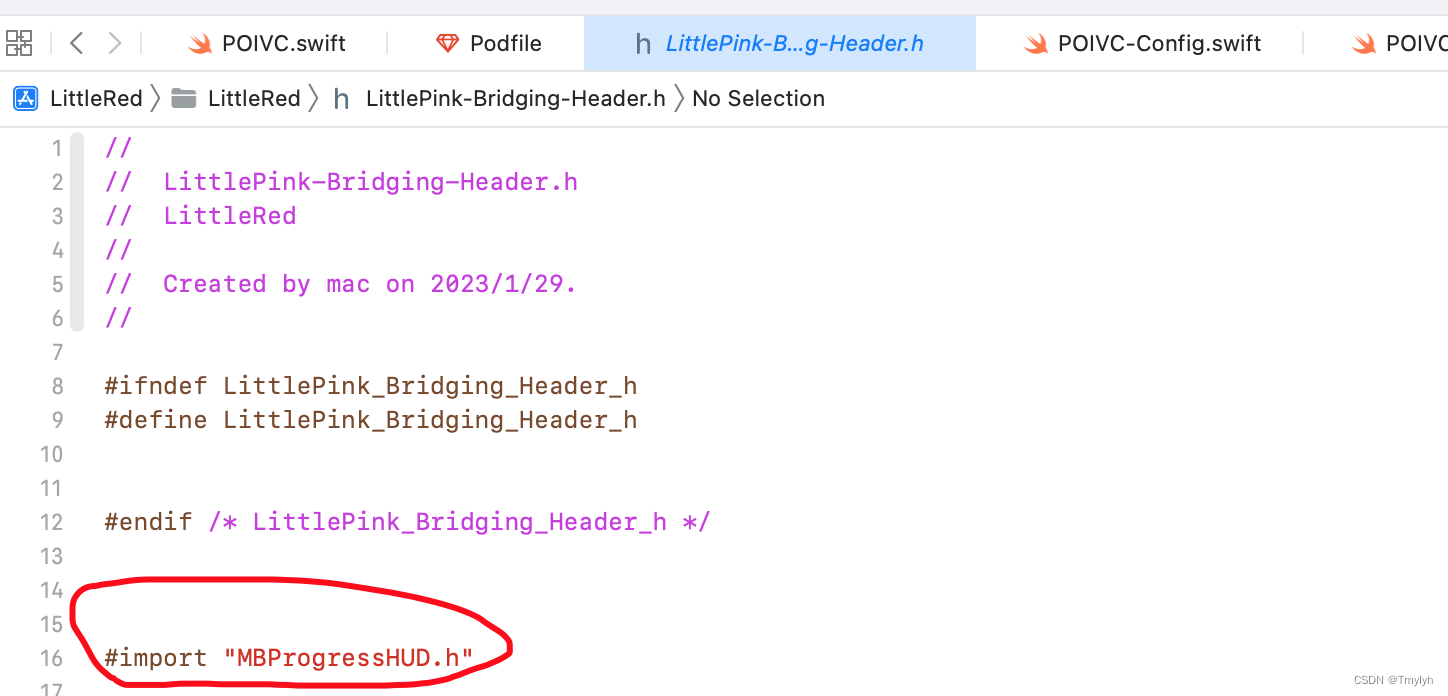
三、引入第三方包
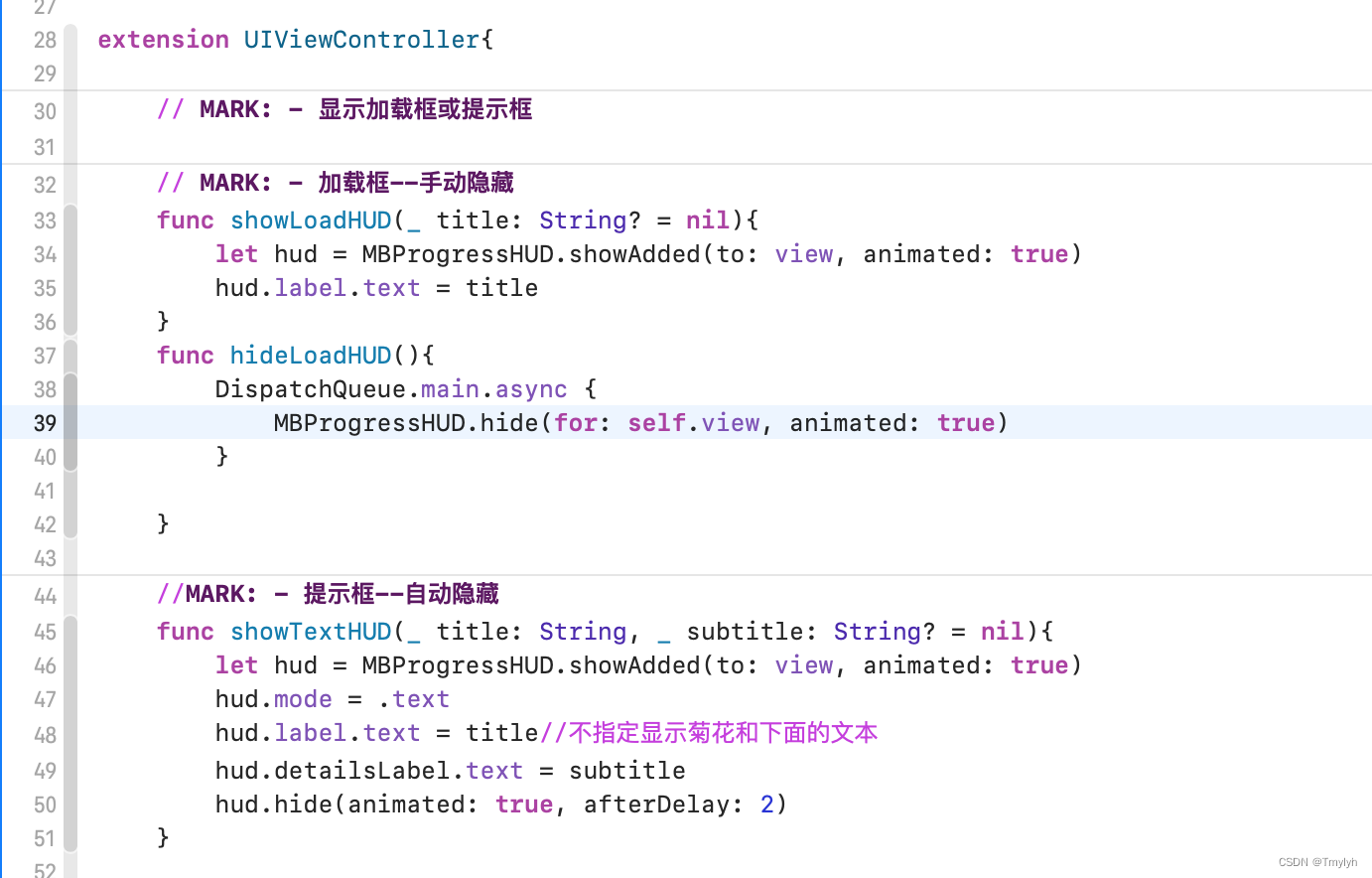
在桥接文件中通过OC语法引入包,接着在整个项目中都可以使用该包的功能了。
以上就是本章的全部内容,喜欢就点个赞和收藏留个足迹吧,有关Podfile中内容的解析也可以在作者主页找哦。

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









