




其实不只是中文,英文,emoji都可以分隔开来
代码如下:
// https://stackoverflow.com/questions/40054732/c-iterate-utf-8-string-with-mixed-length-of-characters
// C++ iterate utf-8 string with mixed length of characters
#include <iostream>
#include <string>
#include <vector>
std::vector <std::string> split_chinese(std::string s) {
std::vector <std::string> t;
for (size_t i = 0; i < s.length();) {
int cplen = 1;
// 以下的几个if,要参考这里 https://en.wikipedia.org/wiki/UTF-8#Description
if ((s[i] & 0xf8) == 0xf0) // 11111000, 11110000
cplen = 4;
else if ((s[i] & 0xf0) == 0xe0) // 11100000
cplen = 3;
else if ((s[i] & 0xe0) == 0xc0) // 11000000
cplen = 2;
if ((i + cplen) > s.length())
cplen = 1;
t.push_back(s.substr(i, cplen));
i += cplen;
}
return t;
}
int main(int argc, char *argv[]) {
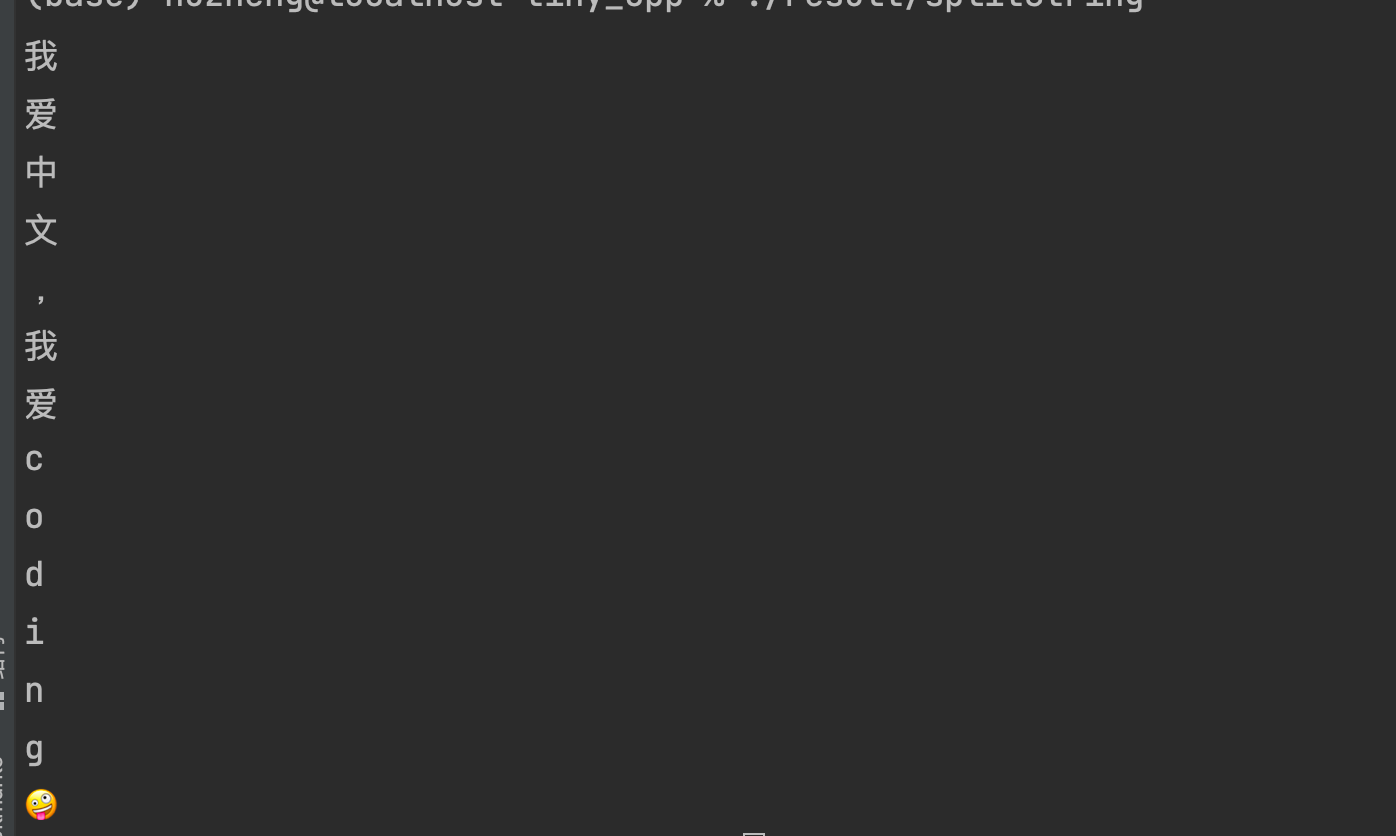
std::string s = "我爱中文,我爱coding🤪";
std::vector <std::string> t = split_chinese(s);
for (auto a: t) {
std::cout << a << std::endl;
}
return 0;
}
运行
build
clang++ SplitString.cpp -o splitString -std=c++17
run
./splitString



















 4609
4609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











