







学习目标
- 识别存储数据的各种方法
- 概述Oracle数据类型
- 区分扩展ROWID和受限ROWID
- 勾勒出一行的结构
- 创建常规表和临时表
- 管理表内的存储结构
- 重新组织、截断和删除表
- 拖放表中的列
表的类型
1. Regular Table (普通表)
普通表是 Oracle 数据库中最基本的存储类型。通常,当你创建一个没有指定特殊存储要求的表时,Oracle 会默认创建一个普通表。它的特点是数据存储结构简单,不做任何特殊的优化。
存储结构:
- 行存储:每一行数据都会被存储为独立的记录,Oracle 会为每个行分配一个存储块。在没有分区或聚簇的情况下,表中的所有数据行都存储在同一个表空间内(通常是一个逻辑上的容器)。
- 数据访问:对于普通表来说,数据库会根据查询的条件来决定数据访问的方式,通常是全表扫描或索引扫描。
性能影响:
- 访问速度:普通表的访问速度受到表大小、查询条件、索引和数据库的物理存储管理的影响。如果表很大,查询效率可能会降低。
- 没有优化的并行查询:如果没有分区,Oracle 数据库不能对查询进行优化,尤其是在多核、多处理器的服务器上,查询可能无法充分利用硬件资源。
管理和优化:
- 索引优化:可以通过创建索引来优化查询,但对于大量数据的普通表,单纯依赖索引并不能完全解决性能问题。
- 分区(Partitioning):如果表非常大,可以考虑通过分区技术来改善性能。
2. **Partitioned Table (分区表) **
分区表是一种可以提高大规模数据处理能力的存储方式,它将一个大的表分割成多个较小的、逻辑上独立的分区。每个分区可以单独存储在不同的物理位置,这样可以优化数据访问和管理。
分区的类型:
-
范围分区 (Range Partitioning):
- 根据列的值范围来划分数据。例如,根据日期或数字范围将数据划分成不同的分区。
- 适用于时间序列数据(例如,按年或月划分日志数据)。
-
哈希分区 (Hash Partitioning):
- 根据列值的哈希值来分配数据到不同的分区。
- 适用于负载均衡需求,特别是当没有自然的范围来分区数据时。
-
列表分区 (List Partitioning):
- 根据列的预定义值列表来划分数据。例如,根据地区代码或国家进行分区。
-
复合分区 (Composite Partitioning):
- 结合多种分区方式,首先通过一个策略分区,然后在每个分区内再应用另一种分区方式。
- 例如,首先按年份进行范围分区,然后在每个年份分区内进行哈希分区。
分区的优点:
- 数据管理灵活性:分区使得大型表的数据可以更易于管理。例如,你可以对单独的分区进行备份、恢复或删除。
- 性能优化:分区表可以通过分区裁剪(Partition Pruning)来提高查询性能,只扫描相关的分区,而不是全表扫描。
- 并行查询:分区表通常能更好地支持并行查询,不同的分区可以在多个处理器上并行处理,提高查询的速度。
管理和优化:
- 自动分区管理:Oracle 允许通过自动分区管理来动态创建新分区或重组现有分区。
- 分区合并与拆分:可以动态地合并或拆分分区,以适应数据的增长和查询的变化。
3. Index-Organized Table (索引组织表)
索引组织表(IOT)是将数据存储在一个或多个 B-树索引中的表,与传统的堆表不同,数据行按主键顺序存储在索引中,而非独立存储在表空间。
结构和性能:
- 数据存储方式:数据行按主键的顺序存储在索引的叶节点中。因此,索引组织表实际上将主键和数据一起存储,避免了传统表和索引之间的冗余存储。
- 溢出段 (Overflow Segment):当某一行数据超过主键索引所能存储的空间时,Oracle 会为其创建溢出段来存储额外的列数据。
优势:
- 减少存储空间:因为主键数据和表数据都存储在同一结构中,所以相较于传统表和独立索引的组合,存储需求较小。
- 快速访问:对主键的查询和范围查询非常高效,因为数据本身已经按照主键排序并存储在 B-树索引中。
使用场景:
- 主键查询频繁:适用于那些大多数查询都基于主键进行的应用,例如用户信息查询。
- 空间优化:当存储空间非常重要时,IOT 是一个理想选择,尤其是在主键数据和其他列数据密切相关的情况下。
限制:
- 非主键查询:对于非主键字段的查询,索引组织表的性能可能不如普通表和传统索引。
- 更新操作:对于频繁更新的数据,IOT 可能会带来额外的维护开销,尤其是当行数据很大时。
4. Clustered Table (聚簇表)
聚簇表将多个相关表的数据存储在同一数据块中,目的是减少磁盘 I/O 并提高查询效率。数据是根据聚簇键进行组织的,聚簇键由一个或多个列组成。
数据存储方式:
- 共享数据块:在聚簇表中,相关表的数据存储在同一个数据块内,减少了磁盘 I/O,尤其是在对这些表进行连接查询时。
- 聚簇键:决定了哪些数据应当被存储在同一个数据块中,通常是被经常一起查询的列。
优势:
- 查询性能优化:对于经常联接的表,聚簇表可以显著减少 I/O,特别是在连接查询时,多个表的数据可以一起加载,避免了磁盘上的多次访问。
- 高效的物理存储:适合存储那些经常一起使用的、关系密切的表。
使用场景:
- 表连接优化:聚簇表适合用于存储有强关联的表,例如,订单表和客户表通常会被一起查询,这时将它们放入同一个聚簇可以提高连接效率。
- 读取密集型操作:适用于需要频繁读取且表之间存在强依赖关系的场景。
缺点与限制:
- 更新代价较高:因为聚簇键的更新可能导致数据行迁移,这会增加额外的 I/O。
- 全表扫描性能较差:尽管在联接查询中性能更好,但在进行全表扫描时,聚簇表的性能不如普通表。
总结与对比:
| 表类型 | 存储方式 | 特点 | 适用场景 |
|---|---|---|---|
| 普通表 (Regular Table) | 无特殊组织,数据顺序存储 | 默认表类型,简单,易管理 | 小型或中型应用,数据访问不复杂 |
| 分区表 (Partitioned Table) | 将表数据分为多个分区 | 支持范围分区、哈希分区等,数据分区可以存储在不同表空间 | 大规模数据,分区查询需求强烈,适合并行查询 |
| 索引组织表 (Index-Organized Table) | 数据存储在主键的B树索引中 | 主键列作为索引存储,节省存储空间,提高查找速度 | 需要快速主键查找和范围查询的应用场景 |
| 聚簇表 (Clustered Table) | 相关表数据共享数据块,按聚簇键组织 | 多表共享数据块,减少I/O,适合强相关的表 | 多个表经常一起查询的场景,适合改进联合查询性能 |
小结
- 普通表 是最常用的表类型,适用于大多数数据存储和管理场景。
- 分区表 则适用于需要处理大规模数据并且要进行高效并行查询的场景。
- 索引组织表 提供了一种节省存储和加速主键查询的方式,适合对主键查询频繁的应用。
- 聚簇表 可以通过共享数据块来提升相关表的数据查询性能,但不适合全表扫描。
Oracle数据类型
当然!以下是您列出的每个数据类型的详细介绍。我们将按顺序逐一讲解这些数据类型,涵盖它们的语法、用途、特点以及适用场景。
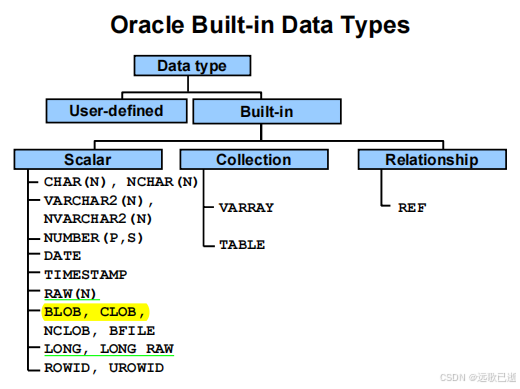
1. CHAR(N) 和 NCHAR(N)
CHAR(N):
- 用途:
CHAR(N)是用于存储固定长度字符数据的类型。N是字符的数量,如果存储的数据长度小于N,Oracle 会用空格来填充数据以达到指定的长度。 - 语法:
CHAR(N),其中N表示最大字符数(1 到 2000 字符)。 - 特点:
- 固定长度,不管存储的数据长度多短,都会填充空格以满足
N长度。 - 适用于存储固定长度的字符串,如国别代码、邮政编码等。
- 固定长度,不管存储的数据长度多短,都会填充空格以满足
- 例子:
CREATE TABLE example_table ( fixed_string CHAR(10) -- 存储长度为 10 的字符串 );
NCHAR(N):
- 用途:
NCHAR(N)是 Unicode 字符数据类型,用于存储多语言文本数据,特别适用于存储非 ASCII 字符(如中文、日文、阿拉伯文等)。 - 语法:
NCHAR(N),其中N为最大字符数。 - 特点:
- 与
CHAR类型类似,但NCHAR使用 Unicode 编码来存储字符。 - 每个字符占用两个字节。
- 与
- 例子:
CREATE TABLE example_table ( unicode_string NCHAR(10) -- 存储 10 个 Unicode 字符 );
2. VARCHAR2(N) 和 NVARCHAR2(N)
VARCHAR2(N):
- 用途:
VARCHAR2(N)是可变长度的字符数据类型,存储时仅占用实际字符长度,适合存储不定长的字符串。 - 语法:
VARCHAR2(N),其中N表示最大字符数。 - 特点:
VARCHAR2类型只会使用存储数据所需的空间,不会自动填充空格,因此比CHAR更节省空间。- 广泛用于存储可变长度的字符串,如名字、地址等。
- 例子:
CREATE TABLE example_table ( variable_string VARCHAR2(50) -- 存储最多 50 个字符的可变长度字符串 );
NVARCHAR2(N):
- 用途:
NVARCHAR2(N)是 Unicode 版本的可变长度字符数据类型,适用于存储多语言字符(如中文、日文等)。 - 语法:
NVARCHAR2(N),其中N为最大字符数。 - 特点:
- 使用 Unicode 字符集存储字符数据,每个字符占用两个字节。
- 适用于需要存储多语言数据的应用。
- 例子:
CREATE TABLE example_table ( unicode_variable_string NVARCHAR2(50) -- 存储最多 50 个 Unicode 字符的可变长度字符串 );
3. NUMBER(P, S)
NUMBER(P, S):
- 用途:
NUMBER(P, S)是用于存储数值数据的最常用数据类型,支持非常高的精度。 - 语法:
NUMBER(P, S),其中P是精度(即总位数,最大为 38 位),S是小数点后的位数。P范围:1 到 38S范围:0 到P
- 特点:
- 适用于存储整数、浮动小数、货币等各种数值数据。
- 如果不指定
S,则默认是整数。
- 例子:
CREATE TABLE example_table ( salary NUMBER(10, 2) -- 存储最多 10 位数字,其中 2 位为小数 );
4. DATE
DATE:
- 用途:
DATE用于存储日期和时间,精确到秒。 - 语法:
DATE - 特点:
- 存储日期、时间、秒的信息,包括:年份、月份、日期、小时、分钟、秒。
- Oracle 会自动存储日期和时间,不仅限于日期。
- 可以通过
TO_DATE函数将字符串转换为DATE类型。
- 例子:
CREATE TABLE example_table ( hire_date DATE -- 存储雇佣日期(包括时间) );
5. TIMESTAMP
TIMESTAMP:
- 用途:
TIMESTAMP类型比DATE提供更高的精度,支持毫秒级(小数秒)时间戳。 - 语法:
TIMESTAMP(P),其中P表示毫秒部分的精度(最多为 9 位,表示纳秒级精度)。 - 特点:
- 存储日期和时间(包括毫秒级精度)。
- 适用于需要高精度时间戳的场景。
- 例子:
CREATE TABLE example_table ( timestamp_column TIMESTAMP(3) -- 存储包括毫秒级精度的时间戳 );
6. RAW(N)
RAW(N):
- 用途:
RAW用于存储二进制数据,通常用于存储图像、加密数据等。 - 语法:
RAW(N),其中N表示字节数(最大 2000 字节)。 - 特点:
RAW类型用于存储二进制数据。- 适用于存储图片、声音等媒体文件,或者用于加密数据的存储。
- 例子:
CREATE TABLE example_table ( image_data RAW(2000) -- 存储 2000 字节的二进制数据 );
7. BLOB, CLOB, NCLOB, BFILE
BLOB:
- 用途:
BLOB(Binary Large Object)用于存储二进制大对象,适用于存储图像、音频、视频等大型二进制文件。 - 特点:
- 支持存储非常大的二进制数据(最大 4 GB)。
- 适用于图像、音频文件等非文本数据。
CLOB:
- 用途:
CLOB(Character Large Object)用于存储大量文本数据,适合存储长文本,如文章、文档等。 - 特点:
- 支持存储大量字符数据(最大 4 GB)。
- 适用于存储长文本数据(如文档、HTML 文件)。
NCLOB:
- 用途:
NCLOB是CLOB的 Unicode 版本,适用于存储多语言字符数据(例如中文、日文等)。 - 特点:
- 支持存储大量 Unicode 字符数据(最大 4 GB)。
BFILE:
- 用途:
BFILE用于存储指向外部二进制文件的路径,文件本身存储在数据库外部。 - 特点:
- 适用于存储外部文件(如图像或视频文件),并通过数据库引用这些文件。
- 最大支持 4 GB。
8. LONG 和 LONG RAW
LONG:
- 用途:
LONG用于存储长文本数据,最多可存储 2 GB 的字符数据。 - 特点:
- 用于存储单列的长文本数据。
- Oracle 已经不推荐使用
LONG类型,转而推荐使用CLOB类型。
LONG RAW:
- 用途:
LONG RAW用于存储长二进制数据,最多可存储 2 GB 的二进制数据。 - 特点:
- 与
LONG类似,但用于存储二进制数据。 - 已不推荐使用,推荐使用
BLOB类型。
- 与
9. ROWID 和 UROWID
ROWID:
- 用途:
ROWID存储表中每行的物理地址,Oracle 用它来快速定位数据行。 - 特点:
- 每个行都有一个唯一的
ROWID。 - 对于性能优化来说,
ROWID是非常高效的访问方式。
- 每个行都有一个唯一的
UROWID:
与 ROWID 类似,但它可以跨表使用。
10. VARRAY
VARRAY:
- 用途:
VARRAY是一种集合类型,用于存储定长的元素列表,所有元素具有相同的数据类型。 - 特点:
- 它是固定大小的数组,最多可以包含一定数量的元素。
- 适用于存储元素数量已知且不会发生太多变化的数据。
- 例子:
CREATE TYPE number_array AS VARRAY(5) OF NUMBER; -- 定义一个最多包含 5 个数字的数组
11. TABLE
TABLE:
- 用途:
TABLE类型用于存储一组相同数据类型的元素,可以视作一个自定义的表类型,通常用于存储多个值。 - 特点:
- 适用于存储具有复杂结构的数据集合。
- 它是一个集合类型,可以与其他表类型联合使用。
12. REF
REF:
- 用途:
REF类型用于存储对对象类型的引用。 - 特点:
- 类似于对象指针,
REF用于引用表中的其他对象类型的数据。 - 适用于表示对象间的关联关系。
- 类似于对象指针,
比较类型之间的区别
这部分主要介绍了 Oracle 内置数据类型,并且详细讲解了如何使用不同的数据类型来存储 标量数据(Scalar Data Types)、集合数据(Collection Data Types)、和 关系数据(Relationship Data Types)。它还区分了 LONG 类型 和 LOB 类型,并且探讨了不同数据类型的特性与应用场景。我们可以从以下几个方面来深入了解这部分内容:
1. 标量数据类型(Scalar Data Types)
标量数据类型用于存储单一值,每列的数据类型通常是标量类型。标量数据类型可分为 字符数据、数字数据、日期和时间 数据,以及 二进制数据。在 Oracle 数据库中,这些类型包括:
字符数据类型
-
CHAR(N) 和 NCHAR(N):这两种类型用于存储定长字符数据,其中
CHAR是固定长度的,而NCHAR用于存储国际字符集(Unicode)字符数据。NCHAR 可用于存储多语言文本,特别是需要固定宽度的字符集。 -
VARCHAR2(N) 和 NVARCHAR2(N):这两种类型用于存储可变长度的字符数据。与
CHAR类型不同,VARCHAR2和NVARCHAR2仅使用实际数据的字节数,因此能够节省存储空间。VARCHAR2用于存储变长字符数据(例如名字、地址等)。NVARCHAR2是VARCHAR2的 Unicode 版本,适用于多语言支持。
数字数据类型
- NUMBER(P, S):用于存储数字。
P表示精度(总位数),S表示小数点后的位数。Oracle 的NUMBER类型具有非常高的灵活性,可以存储从整数到浮动小数的各种数字。
日期和时间数据类型
- DATE:存储日期和时间,包括日期、时间(小时、分钟、秒)。它总是占用 7 字节固定长度。
- TIMESTAMP:在
DATE的基础上,增加了对毫秒级甚至纳秒级精度的支持,适合需要更高时间精度的场景。
二进制数据类型
- RAW(N):用于存储原始的二进制数据,不进行字符集转换,适合存储图片、音频等二进制数据。
大型对象(LOB)数据类型
- BLOB、CLOB、NCLOB、BFILE:
- BLOB(Binary Large Object)用于存储二进制大对象,如图像、音频、视频等。
- CLOB(Character Large Object)用于存储大文本数据,支持最大 4GB 的字符数据。
- NCLOB 是 CLOB 的 Unicode 版本,用于存储多语言字符数据。
- BFILE 用于存储数据库外部的二进制数据,通常用于存储较大的文件。
LONG 和 LONG RAW:
- LONG 和 LONG RAW 类型是较早的 Oracle 数据类型,主要用于存储较大的数据(如图像、文档等)。这些类型已经被 LOB 类型取代,LOB 提供了更好的性能和功能支持。
2. 关系数据类型(Relationship Data Types)
关系数据类型主要用于在数据库中表示表与表之间的关系,通常用于存储 引用(Reference)。常用的关系数据类型包括 REF 类型。
- REF 类型用于存储对某一行或对象的引用。例如,您可以使用
REF类型将一个订单项引用到产品表中的某个产品行,而无需在订单项表中重复存储产品的详细信息。
3. 集合数据类型(Collection Data Types)
集合数据类型用于存储一组数据,通常是多个相同类型的元素。Oracle 提供了两种集合类型:VARRAY 和 Nested Table。
VARRAY(Varying Array)
- VARRAY 是一个有序的元素集合,其中每个元素的类型相同。VARRAY 有一个固定的大小,且最大大小在创建时需要指定。适合存储元素数量较少的集合,比如存储客户的多个电话号。
- 例子:存储客户的多个电话号,可以使用
VARRAY存储长度固定的数组。
Nested Table
- Nested Table 是一个无序的记录集合,每个记录具有相同的结构。与
VARRAY不同,Nested Table没有预定义的大小限制,并且表内的数据可以被分开存储(与父表分离)。Nested Table的特点是可以存储大量的记录,因此适用于复杂数据存储需求。
4. LONG、LONG RAW 与 LOB 类型的比较
在 Oracle 中,LONG 和 LONG RAW 数据类型用于存储大型数据,但它们存在一些限制(如存储方式和访问方式)。而 LOB(Large Object) 类型提供了更加灵活和高效的存储方式。以下是它们之间的比较:
| 特性 | LONG/ LONG RAW | LOB |
|---|---|---|
| 存储方式 | 数据存储在行内(行内存储) | 数据存储在表外或文件中(可选) |
| 数据大小 | 最大 2GB | 最大 4GB |
| 支持对象类型 | 不支持 | 支持(除 NCLOB 外) |
| 存储访问方式 | 顺序访问 | 随机访问 |
| 存储位置 | 所有数据在行内 | 数据可以存储在单独的段和表空间中,或外部文件(BFILE) |
| 支持的应用程序编程接口(API) | 不支持 LOB API | 支持 LOB API |
5. ROWID 和 UROWID 数据类型
ROWID 是一个内部数据类型,用于唯一标识数据库中的每一行。每一行都有一个 ROWID,该值是数据库中的物理地址指针,提供了最快的访问方式。ROWID 不存储为显式列,但可以查询并用于定位表中的行。
- UROWID(Universal ROWID)是
ROWID的扩展,能够支持更多类型的行标识符,包括外部表和索引组织表(IOT)中的 ROWID。它也可以支持非 Oracle 数据库中的 ROWID。
6. Oracle 用户定义数据类型
Oracle 还允许用户自定义数据类型(UDT),用户可以根据应用需求定义复杂的数据类型。例如,用户可以定义复合数据类型(如 OBJECT 类型)或其他自定义数据类型,并在应用中使用它们。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











