






本节内容包含:大模型部署背景、大模型部署方法、LMDeploy简介、动手实践环节,共四部分。
模型部署
- 定义
在软件工程中,部署通常指的是将开发完毕的软件投入使用的过程。
在人工智能领域,模型部署是实现深度学习算法落地应用的关键步骤。简单来说,模型部署就是将训练好的深度学习模型在特定环境中运行的过程。 - 场景
服务器端:CPU部署,单GPU/TPU/NPU部署,多卡/集群部署…
移动端/边缘端:移动机器人,手机…
大模型部署面临的挑战
- 计算量巨大
大模型参数量巨大,前向推理时需要进行大量计算。
根据InternLM2技术报告提供的模型参数数据,以及OpenAI团队提供的计算量估算方法,20B模型每生成1个token,就要进行约406亿次浮点运算;照此计算,若生成128个token,就要进行5.2万亿次运算。
20B算是大模型里的“小”模型了,若模型参数规模达到175B(GPT-3),Batch-Size(8S)再大一点,每次推理计算量将达到千万亿量级。
以NVIDIA A100为例,单张理论FP16运算性能为每秒77.97 TFLOPS3I(77万亿),性能捉紧。 - 访存瓶颈
大模型推理是“访存密集”型任务。目前硬件计算速度“远快于”显存带宽,存在严重的访存性能瓶颈。
以RTX 4090推理175B大模型为例,BS为1时计算量为6.83TFLOPs,远低于82.58 TFLOPs的FP16计算能力:但访存量为32.62 TB,是显存带宽每秒处理能力的30倍, - 动态请求
请求量不确定;
请求时间不确定;
Token逐个生成,生成数量不确定。



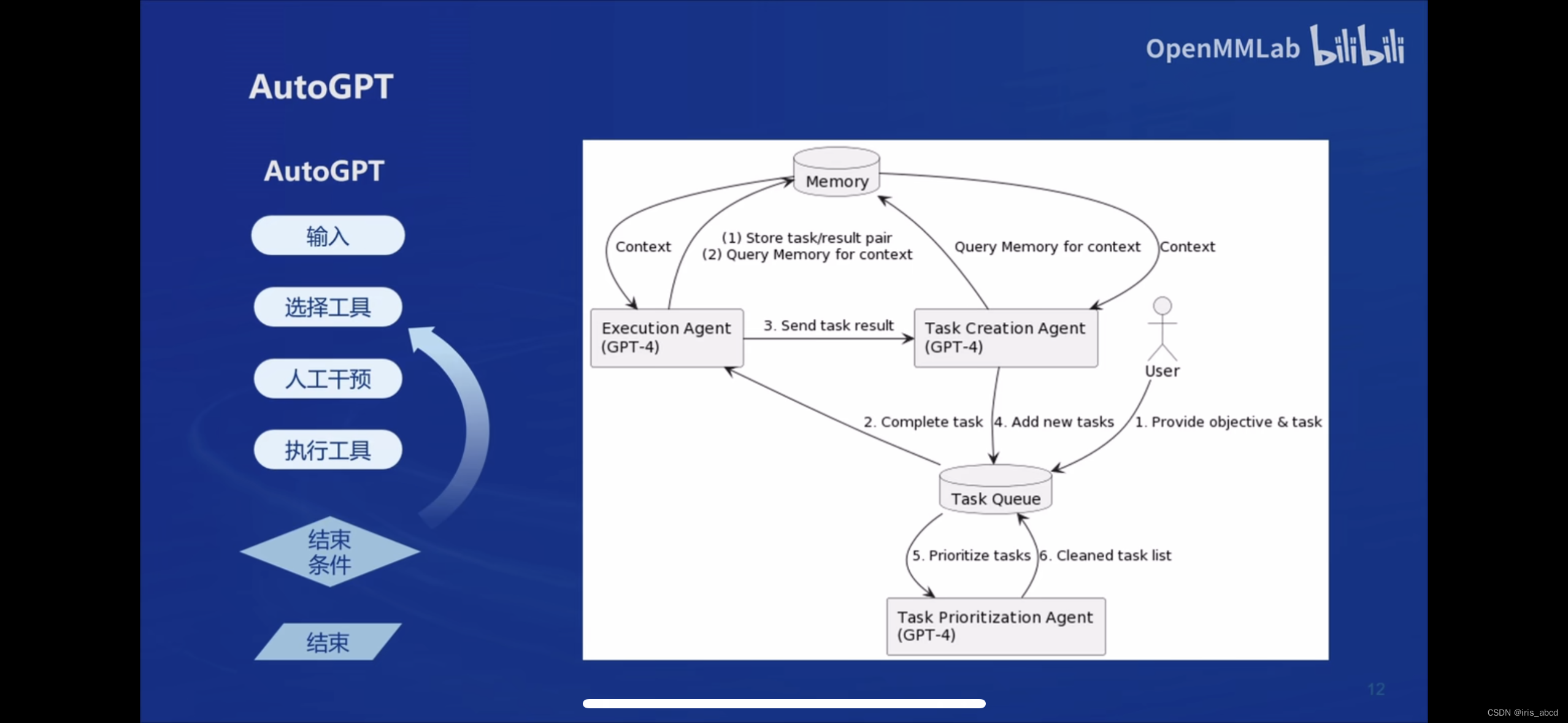
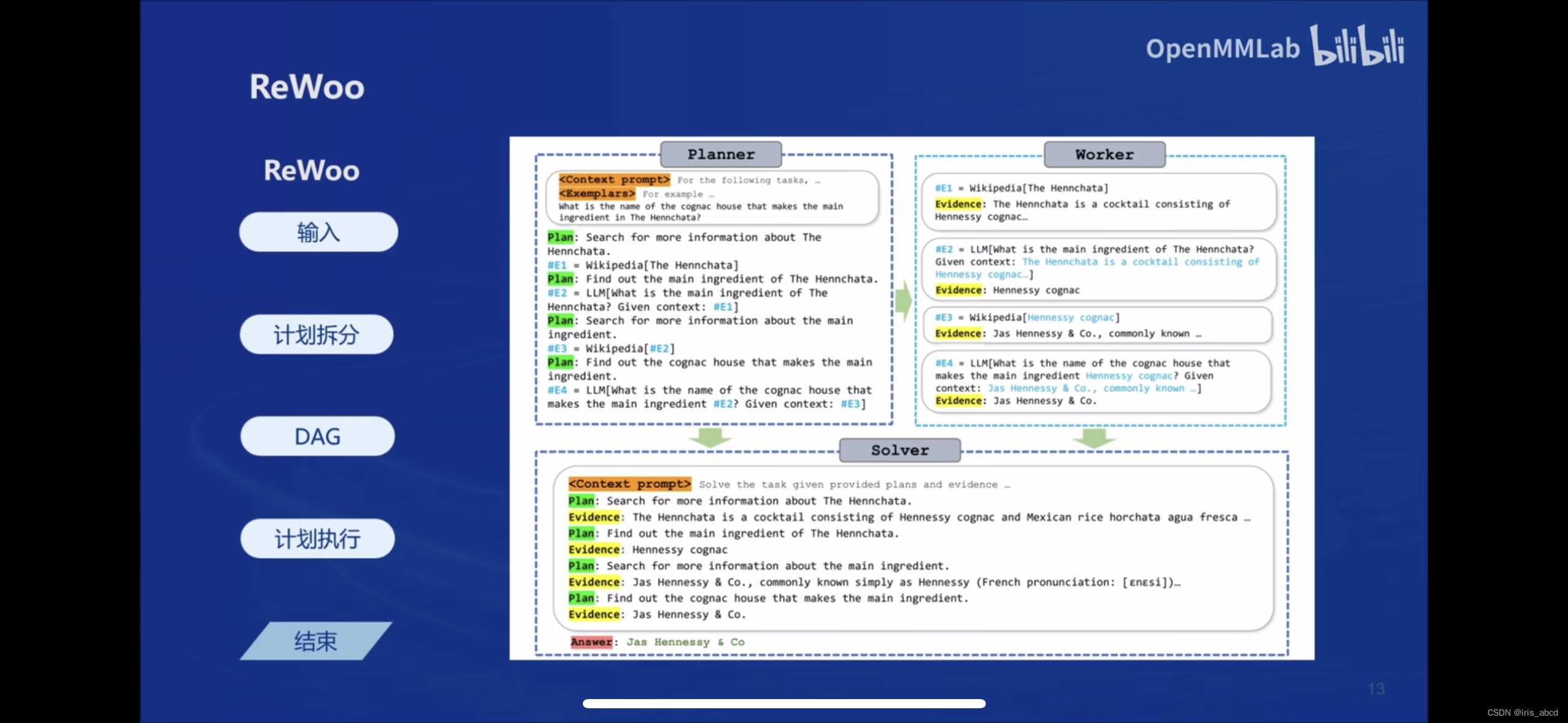
LMDeploy简介
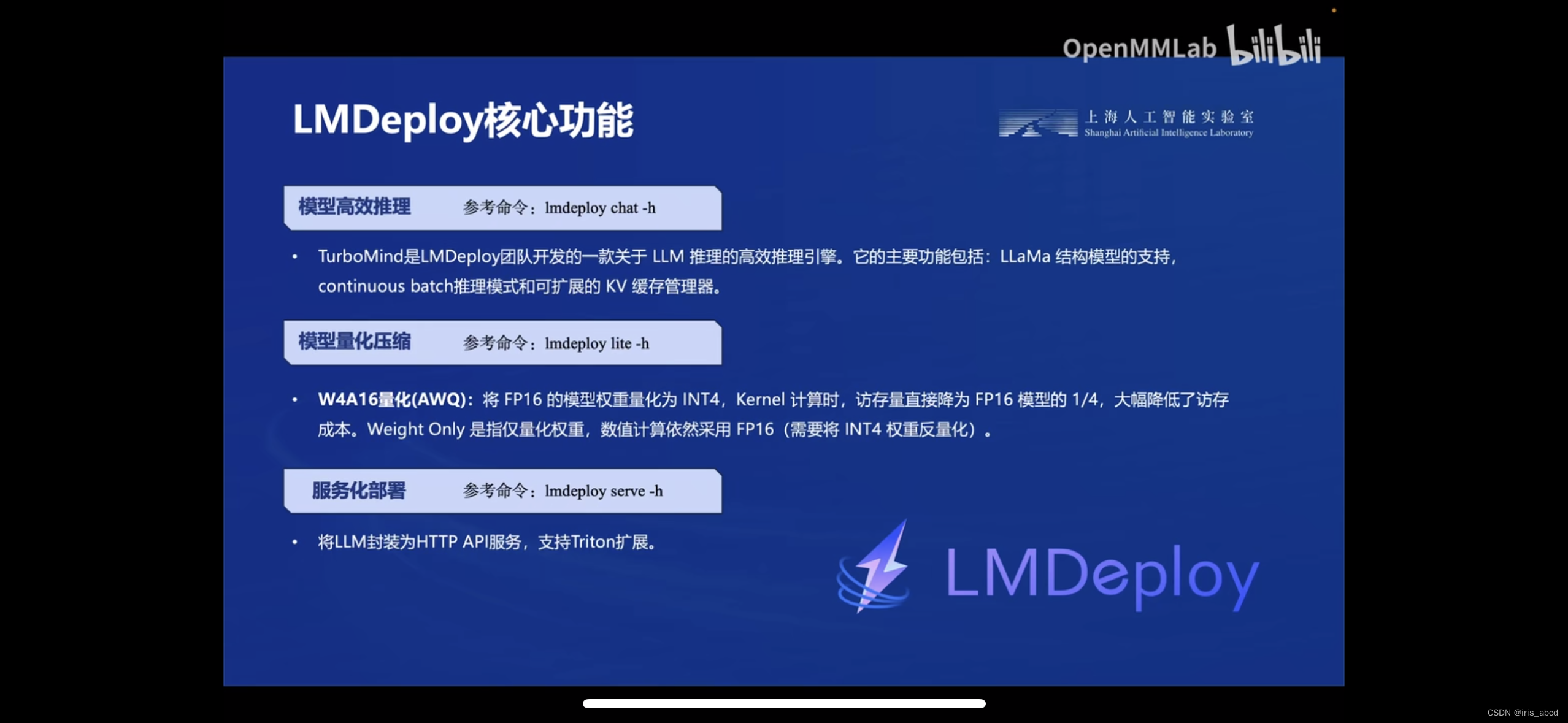
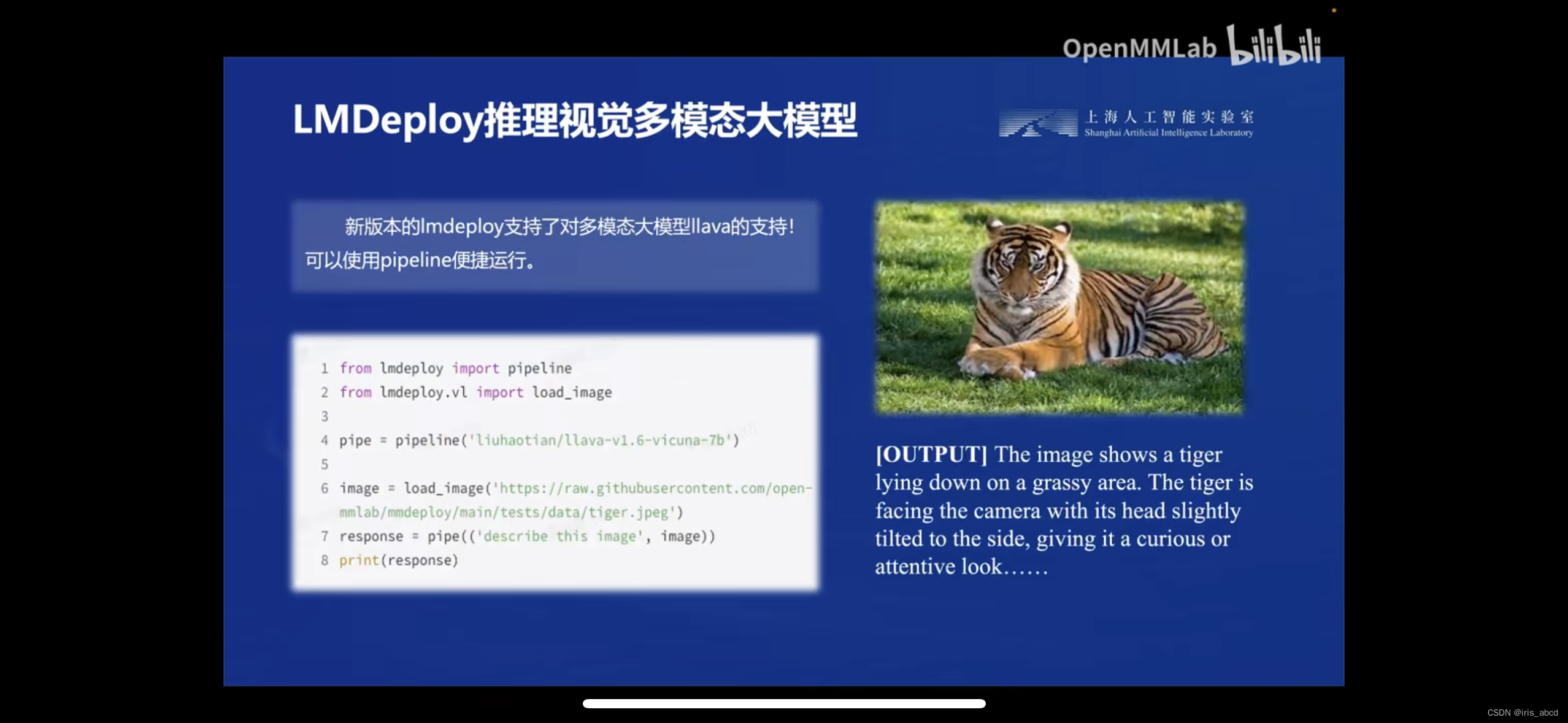
LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。核心功能包括高效推理、可靠量化、便捷服务和有状态推理。
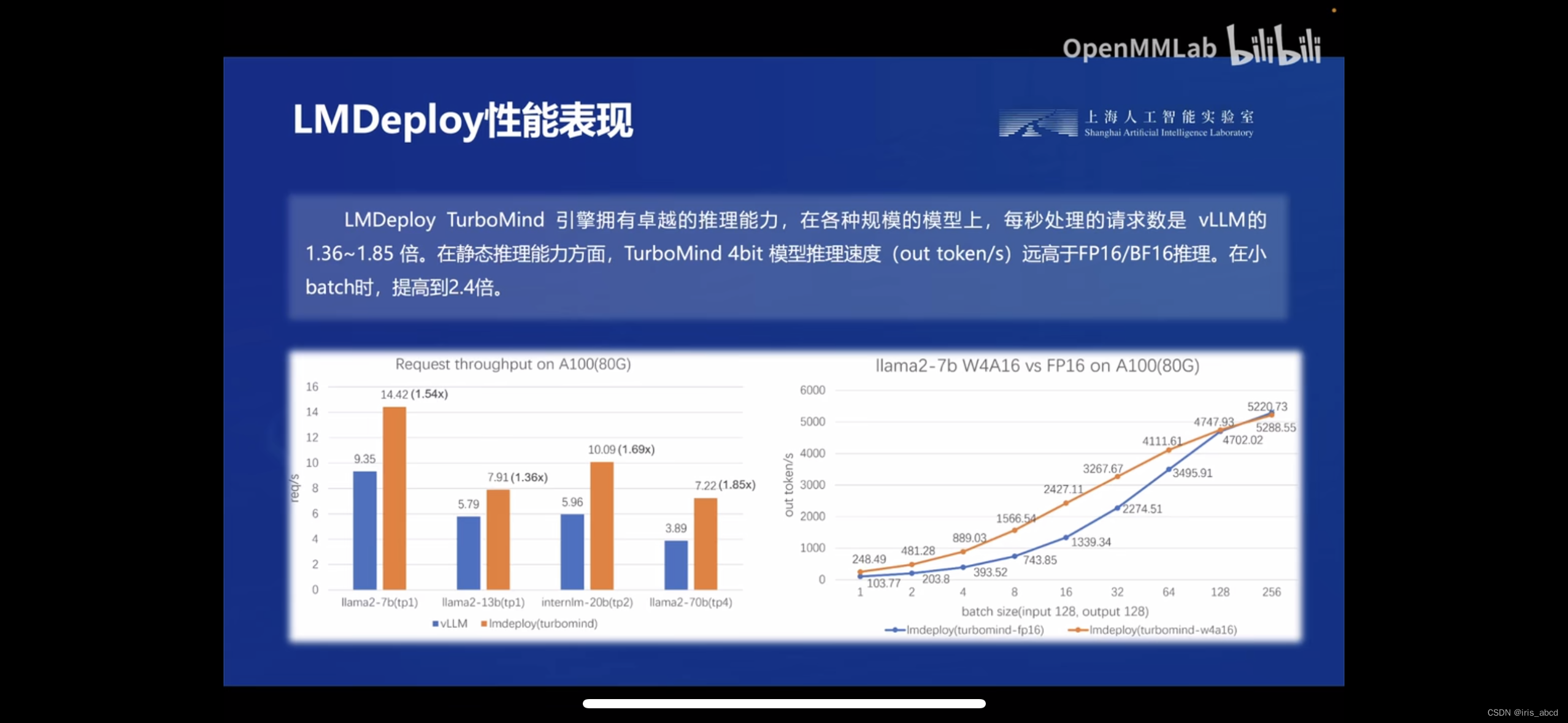
- 高效的推理:LMDeploy开发了Continuous Batch,Blocked K/ Cache,动态拆分和融合,张量并行,高效的计算kernel等重要特性。InternLM2推理性能是vLLM的 1.8倍.
- 可靠的量化:LMDeploy支持权重量化和k/v量化。4bit模型推理效率是FP16下的2.4倍。量化模型的可靠性已通过OpenCompass评测得到充分验证。
- 便捷的服务:通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
- 有状态推理:通过缓存多轮对话过程中Attention的k/,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。



















 2201
2201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









