







 本文提出了一种名为AGCNN的自适应图卷积神经网络,解决了现有图卷积网络在处理不同结构图数据时的局限性。AGCNN能够针对每个图数据学习任务驱动的自适应图拉普拉斯矩阵,同时通过距离度量学习优化图的更新。网络中包含了谱图卷积层、图最大池化层和图聚集层,以适应多样性的图结构。此外,通过残差图拉普拉斯来加速训练并提高稳定性。该方法适用于点云分类等任务,能够更好地捕获图的拓扑结构信息。
本文提出了一种名为AGCNN的自适应图卷积神经网络,解决了现有图卷积网络在处理不同结构图数据时的局限性。AGCNN能够针对每个图数据学习任务驱动的自适应图拉普拉斯矩阵,同时通过距离度量学习优化图的更新。网络中包含了谱图卷积层、图最大池化层和图聚集层,以适应多样性的图结构。此外,通过残差图拉普拉斯来加速训练并提高稳定性。该方法适用于点云分类等任务,能够更好地捕获图的拓扑结构信息。
AGCNN:Adaptive Graph Convolutional Neural Networks
在阅读本篇文章前,应当了解spectral graph convolution network
摘要
- 背景: Graph Convolutional Neural Networks (Graph CNNs)可以看作广义CNNs,能够有效地处理各种graph数据
- 问题: 当前,Graph CNNs中的filters都是建立在固定或是共享的graph结构上,对于实际的数据而言,graph结构在大小和连通性上都不相同
- 方法: 提出一个更具泛化性和灵活性的Graph CNNs,该网络可以将任意的graph结构作为输入。通过这种方式,在训练时为每个graph数据学习任务驱动的自适应graph;为了更高效的学习graph,还提出了一个distance metric learning
- 代码: TensorFlow版本
引言
- 在点云分类任务中,graph的拓扑结构要比点特征更具有信息
- 当前Graph CNNs的瓶颈有以下几点:
- graph degree约束
- 要求输入都要保持相同的graph结构
- 固定的 graph
- 无法学习拓扑结构的信息
- 本文提出一种新的spectral graph convolution network,以不同的graph结构原始数据作为输入。给batch中每个单独的样本都分配一个特定的graph Laplacian,客观地描述了其独特的拓扑结构。特定的graph Laplacian 将会导致特定的 spectral filter,根据graph Laplacian独特的graph Laplacian, spectral filter能够结合邻域的特征。
- residual graph 用于发掘更细的结构信息
- a supervised metric learning with Mahalanobis distance能够减少复杂度
- Contributions:
- Construct unique graph Laplacian
- Learn distance metric for graph update
- Feature embedding in convolution
- Accept flexible graph inputs
相关工作
本文所参考的方法将 one-hop local kernel 扩展到了
K
K
K-hop 连接的情况上。根据graph Fourier transform,如果
U
U
U是
L
L
L的graph Fourier basis集合,那么:
x
k
+
1
=
σ
(
g
θ
(
L
K
)
x
k
)
=
σ
(
U
g
θ
(
Λ
K
)
U
T
x
k
)
.
x_{k+1}=\sigma\left(g_{\theta}\left(L^{K}\right) x_{k}\right)=\sigma\left(U g_{\theta}\left(\Lambda^{K}\right) U^{T} x_{k}\right) .
xk+1=σ(gθ(LK)xk)=σ(Ugθ(ΛK)UTxk).
diag
(
Λ
)
\operatorname{diag}(\Lambda)
diag(Λ)是
L
L
L的frequency components。
方法
SGC-LL
Spectral Graph Convolution layer + Graph Laplacian Learning = SGC-LL
Learning Graph Laplacian
给定一个graph
G
=
(
V
,
E
)
\mathcal{G}=(V, E)
G=(V,E),其邻接矩阵为
A
A
A,度矩阵为
D
D
D,归一化后的Graph Laplacian matrix
L
L
L表示为:
L
=
I
−
D
−
1
/
2
A
D
−
1
/
2
L=I-D^{-1 / 2} A D^{-1 / 2}
L=I−D−1/2AD−1/2
L
L
L表示了节点间的连通性和顶点的度,知道了
L
L
L就意味着知道了
G
\mathcal{G}
G的拓扑结构。
由于 L L L是对称正定矩阵,其特征分解后会得到一组完整的特征向量 { u s } s = 0 N − 1 \left\{u_{s}\right\}_{s=0}^{N-1} {us}s=0N−1构成的 U U U, N N N表示顶点的数量。使用 U U U作为graph Fourier basis,Graph Laplacian可以对角化为 L = U Λ U T L=U \Lambda U^{T} L=UΛUT。
Graph Fourier 变换被定义为
x
^
=
U
T
x
\hat{x}=U^{T} x
x^=UTx。由于graph拓扑结构的谱表示为
Λ
\Lambda
Λ,那么谱filter
g
θ
(
Λ
)
g_{\theta}(\Lambda)
gθ(Λ) 会在空间上生成特定的卷积kernel。由平滑的frequency components构成的spectrum将会形成局部的空间kernel。
g
θ
(
Λ
)
g_{\theta}(\Lambda)
gθ(Λ)可以表示为一个多项式:
g
θ
(
Λ
)
=
∑
k
=
0
K
−
1
θ
k
Λ
k
,
g_{\theta}(\Lambda)=\sum_{k=0}^{K-1} \theta_{k} \Lambda^{k},
gθ(Λ)=k=0∑K−1θkΛk,
这引出了一个
K
K
K-localized kernel,它允许任何一对最短路径距离
d
G
<
K
d_{\mathcal{G}}<K
dG<K的顶点squeeze in。
此外,更远的连接意味着较少的相似性,并将被分配由 θ k \theta_{k} θk控制的较少的贡献。多项式滤波器平滑了spectrum,而通过 θ k \theta_{k} θk进行的参数化也强制实现了最终kernel从中心顶点到最远的 K K K-hop顶点的圆形权重分布。这就限制了kernel的灵活性。更重要的是,两个顶点之间的相似性本质上是由选定的距离度量和特征域决定的。对于非欧几里得域的数据,欧几里得距离不再被保证是度量相似度的最佳指标。因此,由于图是次优的,所以连通节点之间的相似性可能低于不连通节点之间的相似性。同时也有两个可能的原因:
- Graph是在特征提取和变换前的原始特征域中构造的
- 图的拓扑结构是内在的,它仅仅表示物理连接,例如分子中的化学键
为了打破上述限制,我们提出一种新的spectral filter,对 Laplacian L L L进行参数化。
给定原始的 Laplacian
L
L
L,特征
X
X
X 和 参数
Γ
\Gamma
Γ,函数
F
(
L
,
X
,
Γ
)
\mathcal{F}(L, X, \Gamma)
F(L,X,Γ)输出的是更新后Laplacian
L
~
\tilde{L}
L~的spectrum,那么filter将会变成:
g
θ
(
Λ
)
=
∑
k
=
0
K
−
1
(
F
(
L
,
X
,
Γ
)
)
k
g_{\theta}(\Lambda)=\sum_{k=0}^{K-1}(\mathcal{F}(L, X, \Gamma))^{k}
gθ(Λ)=k=0∑K−1(F(L,X,Γ))k
最终,SGC-LL层可以表示为:
Y
=
U
g
θ
(
Λ
)
U
T
X
=
U
∑
k
=
0
K
−
1
(
F
(
L
,
X
,
Γ
)
)
k
U
T
X
.
Y=U g_{\theta}(\Lambda) U^{T} X=U \sum_{k=0}^{K-1}(\mathcal{F}(L, X, \Gamma))^{k} U^{T} X .
Y=Ugθ(Λ)UTX=Uk=0∑K−1(F(L,X,Γ))kUTX.
由于是稠密的矩阵乘法
U
T
X
U^{T} X
UTX,所以上式中的复杂度为
O
(
N
2
)
\mathcal{O}\left(N^{2}\right)
O(N2)。如果
g
θ
(
L
~
)
g_{\theta}(\tilde{L})
gθ(L~)是通过
L
~
\tilde{L}
L~的多项式函数递归估计的,那么复杂度就会降至
O
(
K
)
\mathcal{O}(K)
O(K),这是因为Laplacian
L
~
\tilde{L}
L~是稀疏矩阵。我们选择Chebychev展开计算
k
k
k阶多项式
T
k
(
L
~
)
X
T_{k}(\tilde{L}) X
Tk(L~)X。
Training Metric for Graph Update
对于graph结构数据,欧式距离已经不是顶点相似度的最好度量,因此本文使用
x
i
x_{i}
xi 和
x
j
x_{j}
xj间的Generalized Mahalanobis distance作为度量:
D
(
x
i
,
x
j
)
=
(
x
i
−
x
j
)
T
M
(
x
i
−
x
j
)
.
\mathbb{D}\left(x_{i}, x_{j}\right)=\sqrt{\left(x_{i}-x_{j}\right)^{T} M\left(x_{i}-x_{j}\right)} .
D(xi,xj)=(xi−xj)TM(xi−xj).
如果
M
=
I
M=I
M=I,那么上式就会退化成欧式距离。在本文的模型中,半正定矩阵
M
=
M=
M=
W
d
W
d
T
W_{d} W_{d}^{T}
WdWdT,其中
W
d
W_{d}
Wd是SGCLL层的其中一个训练权重。接着,使用该距离计算高斯kernel:
G
x
i
,
x
j
=
exp
(
−
D
(
x
i
,
x
j
)
/
(
2
σ
2
)
)
.
\mathbb{G}_{x_{i}, x_{j}}=\exp \left(-\mathbb{D}\left(x_{i}, x_{j}\right) /\left(2 \sigma^{2}\right)\right) .
Gxi,xj=exp(−D(xi,xj)/(2σ2)).
在对
G
\mathbb{G}
G归一化后,得到稠密的邻接矩阵
A
^
\hat{A}
A^。
Re-parameterization on feature transform
在经典CNNs中,卷积层的输出特征是通过所有特征图的相加得到的,这些特征图都是通过不同的filter独立计算得到的。这就意味着新的特征不仅取决于临近顶点,还会收到其他intra-vertex特征的影响。
但是,在graph convolution上,在同一graph上为不同的顶点特征创建和训练单独的拓扑结构是无法解释的。为了构造intra-vertex和inter-vertex 特征的映射,我们在SGC-LL层引入了一个变换矩阵和偏置向量:
Y
=
(
U
g
θ
(
Λ
)
U
T
X
)
W
+
b
Y=\left(U g_{\theta}(\Lambda) U^{T} X\right) W+b
Y=(Ugθ(Λ)UTX)W+b
在第
i
i
i层,变换矩阵
W
i
∈
R
d
i
−
1
×
d
i
W_{i} \in \mathbb{R}^{d_{i-1} \times d_{i}}
Wi∈Rdi−1×di和偏置
b
i
∈
R
d
i
×
1
b_{i} \in \mathbb{R}^{d_{i} \times 1}
bi∈Rdi×1与度量
M
i
M_{i}
Mi一起训练,其中
d
i
d_{i}
di是特征维度。
在SGC-LL层中,需要训练的参数为 { M i , W i , b i } \left\{M_{i}, W_{i}, b_{i}\right\} {Mi,Wi,bi},学习复杂度为 O ( d i d i − 1 ) \mathcal{O}\left(d_{i} d_{i-1}\right) O(didi−1),不受输入graph大小和度的影响,在下一层SGC-LL中,spectral filter将会嵌入到其他的特征域,该特征域中的度量与其他域不同。
Residual Graph Laplacian
在分子任务中,由于没有关于距离度量的先验知识,度量
M
M
M被随机初始化,所以可能需要很长时间才能收敛。为了加速训练和提高学习图拓扑结构的稳定性,我们提出了一个合理的假设,即最优图Laplacian
L
^
\hat{L}
L^与原始Laplacian
L
L
L之间有着较小的变化:
L
^
=
L
+
α
L
r
e
s
\hat{L}=L+\alpha L_{res}
L^=L+αLres
换句话说,就是原始Laplacian
L
L
L已经包含了一定数量的graph结构信息,还有一些次结构信息没有包括进来,其中有无法在intrinsic graph上直接学习的虚拟顶点连接。因此,我们不直接学习
L
^
\hat{L}
L^,而是学习residual graph Laplacian
L
r
e
s
(
i
)
=
L
(
M
i
,
X
)
L_{res}(i)=\mathcal{L}(M_i,X)
Lres(i)=L(Mi,X)。
L
r
e
s
(
i
)
L_{res}(i)
Lres(i)对于最终graph拓扑结构的影响由
α
\alpha
α控制,SGC-LL具体的操作如算法1所示。

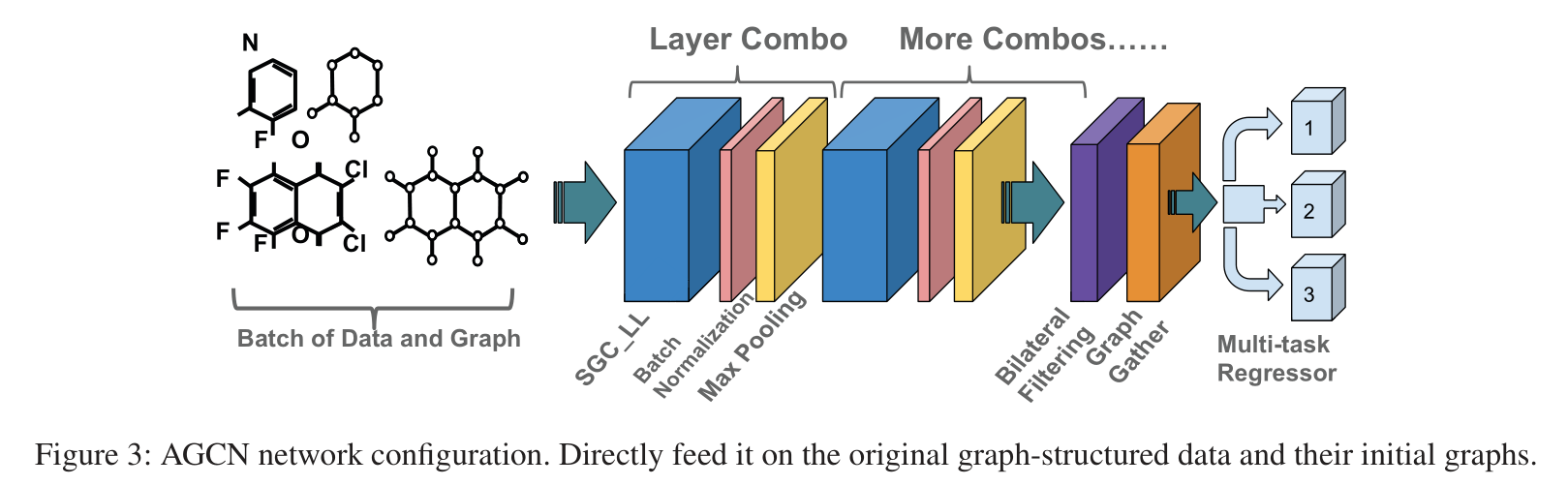
AGCN Network
AGCN Network = SGC-LL layer + graph max pooling layer + graph gather layer
Graph Max Pooling
Graph max pooling在特征间进行。对于graph的第
v
v
v个顶点的特征
x
v
x_v
xv, pooling操作会将第
j
j
j个特征
x
v
(
j
)
x_v(j)
xv(j),替换为第
j
j
j个特征中最大的那一个,这些特征包括相邻顶点和自身。如果
N
(
v
)
N(v)
N(v)是
v
v
v的一组相邻相邻顶点,那么在顶点
v
v
v处的新特征为:
x
^
v
(
j
)
=
max
(
{
x
v
(
j
)
,
x
i
(
j
)
,
∀
i
∈
N
(
v
)
}
)
\hat{x}_{v}(j)=\max \left(\left\{x_{v}(j), x_{i}(j), \forall i \in N(v)\right\}\right)
x^v(j)=max({xv(j),xi(j),∀i∈N(v)})
Graph Gather
在graph gather层,将所有的顶点特征向量进行相加,作为graph数据的表示。Gather layer的输出被向量用于预测。若不使用graph gather层,那么网络可以被用于顶点的预测任务。以顶点为单位的预测包括graph补全和社交媒体上的预测。
Bilateral Filter
Bilateral filter layer的作用是用于防止过拟合,residual graph Laplacian肯定会适应模型以更好地拟合训练任务,但存在过拟合的风险。为了避免过拟合现象,我们引入修改后的bilateral filtering layer,通过增大 L L L的空间局部性来对SGC-LL的激活结果进行正则化。除了这些,还用了Batch normalization。
Network Configuration
layer combo = one SGC-LL layer + one batch normalization layer + one graph max pooling layer
在经过一个combo layer后,batch中的graph结构得到更新,同时grap大小保持不变。
Batch Training of Diverse Graphs
在graph结构数据上进行卷积时最大的挑战就是难以匹配训练样本不同的局部拓扑结构。
本文中的SGC-LL layer训练单独的Laplacian,保留了数据结构的所有的局部拓扑结构。我们发现,在构造graph结构时,feature space 和 distance metrics非常重要,SGC-LL layer仅仅需要batch中所有的样本都共享相同的特征变换矩阵和distance metrics。在训练前,需要构造初始的graph Laplacians并根据这些初始Laplacians更新kernel,这就需要额外的内存,但是这是可以接受的,因为graph Laplacians通常都是稀疏的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









