



 文章介绍了Doris数据库中数据分区的概念,包括RANGE和LIST两种分区方式,以及根据哈希值进行的分桶策略。RANGE分区常用于时间数据,便于区分冷热数据;LIST分区适合按枚举值如城市进行分区。建议选择区分度大的列做分桶以避免数据倾斜,同时注意控制单个bucket大小。合理的分区和分桶设计能提高查询效率。
文章介绍了Doris数据库中数据分区的概念,包括RANGE和LIST两种分区方式,以及根据哈希值进行的分桶策略。RANGE分区常用于时间数据,便于区分冷热数据;LIST分区适合按枚举值如城市进行分区。建议选择区分度大的列做分桶以避免数据倾斜,同时注意控制单个bucket大小。合理的分区和分桶设计能提高查询效率。

分区(partition)说明
分区是指将数据按照某个规则划分到不同的物理存储节点上,以实现数据的分布式存储和查询。在 Doris 中,可以通过指定分区键来进行数据的分区。分区键是指在表中用于划分数据的列或列组合。Doris 支持RANGE 分区和 LIST 分区两种方式。
逻辑上可以理解为将原始表划分成了多个子表。可以方便的按分区对数据进行管理,例如,删除数据时,更加迅速。
分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
Doris在建立分区时,可以不等分,比如:历史数据可以用年来分区,近年的数据可以用月来分区
RANGE分区
业务上,多数用户会选择采用按时间进行partition, 让时间进行partition有以下好处:
- 可区分冷热数据
- 可用上Doris分级存储(SSD + SATA)的功能
LIST分区
业务上,用户可以选择城市或者其他枚举值进行partition。
HASH分桶(bucket)说明
根据hash值将数据划分成不同的 bucket。
- 建议采用区分度大的列做分桶, 避免出现数据倾斜
- 为方便数据恢复, 建议单个 bucket 的 size 不要太大, 保持在 10GB 以内, 所以建表或增加 partition 时请合理考虑 bucket 数目, 其中不同 partition 可指定不同的 buckets 数。
示例
一、RANGE分区
哈希分区10个(其中两个分区时间范围是1年,剩余分区时间范围是1个月),哈希分桶5个
CREATE TABLE `table05` (
`order_id` varchar(64) NOT NULL COMMENT "",
`pay_date` date COMMENT "",
`trade_no` varchar(64) REPLACE_IF_NOT_NULL COMMENT "",
`ref_num` varchar(18) REPLACE_IF_NOT_NULL NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`order_id`,`pay_date`)
COMMENT "OLAP"
PARTITION BY RANGE(`pay_date`)
(PARTITION p2019 VALUES [('0000-01-01'), ('2020-01-01')),
PARTITION p2020 VALUES [('2020-01-01'), ('2021-01-01')),
PARTITION p202101 VALUES [('2021-01-01'), ('2022-01-01')),
PARTITION p202201 VALUES [('2022-01-01'), ('2023-01-01')),
PARTITION p202301 VALUES [('2023-01-01'), ('2023-02-01')),
PARTITION p202302 VALUES [('2023-02-01'), ('2023-03-01')),
PARTITION p202303 VALUES [('2023-03-01'), ('2023-04-01')),
PARTITION p202304 VALUES [('2023-04-01'), ('2023-05-01')),
PARTITION p202305 VALUES [('2023-05-01'), ('2023-06-01')),
PARTITION p202306 VALUES [('2023-06-01'), ('2023-07-01'))
DISTRIBUTED BY HASH(`order_id`) BUCKETS 5
PROPERTIES (
"replication_allocation" = "tag.location.default: 3",
"in_memory" = "false",
"storage_format" = "V2"
);
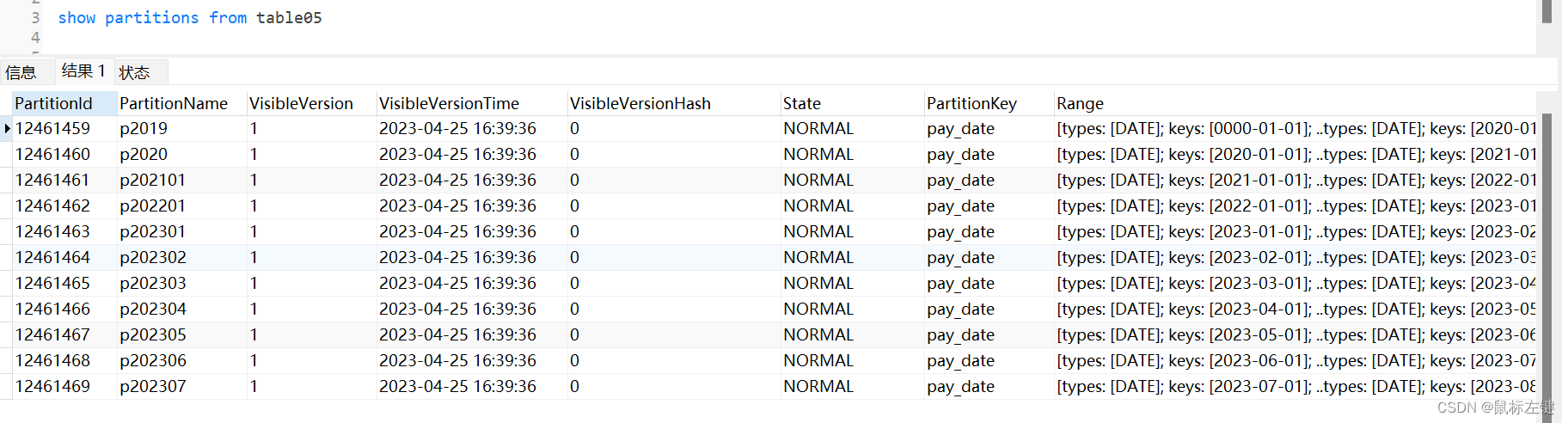
通过show partitions from table05可以查询分区详情
二、LIST分区
范围分区3个,哈希分桶5个
CREATE TABLE IF NOT EXISTS table06
(
`order_id` varchar(64) NOT NULL COMMENT "",
`city` varchar(64) NOT NULL COMMENT "",
`era` varchar(64) REPLACE_IF_NOT_NULL COMMENT ""
)ENGINE=OLAP
AGGREGATE KEY(`order_id`,`city`)
COMMENT "OLAP"
PARTITION BY List(`city`)
(
PARTITION up VALUES IN('北京','天津','河北'),
PARTITION centre VALUES IN('上海','湖北','湖南'),
PARTITION down VALUES IN('广州','香港','澳门')
)
DISTRIBUTED BY HASH(`order_id`) BUCKETS 5
PROPERTIES
(
"replication_allocation" = "tag.location.default: 3",
"in_memory" = "false",
"storage_format" = "V2"
);
通过show partitions from table06可以查询分区详情

总结:
在 Doris 中,为了提高查询效率,可以通过合理的分区和分桶设计来实现。以下是一些建议:
- 选择合适的分区键:
- 选择查询过滤条件中经常出现的列作为分区键,这样可以在查询时减少需要扫描的分区数量,从而提高查询效率。
- 如果查询中经常涉及到时间范围,可以考虑使用时间列作为分区键,并使用范围分区。这样可以根据时间范围快速定位到相关分区。
- 选择合适的分区方式:
- 哈希分区:适用于分区键的值分布较为均匀的场景,可以实现数据的均匀分布,提高查询效率。
- 范围分区:适用于分区键的值具有明显的范围特征,例如城市列。可以根据查询条件快速定位到相关分区,提高查询效率。
- 选择合适的分桶键:
选择查询中经常需要聚合或者过滤的列作为分桶键,这样可以在查询时减少需要扫描的分桶数量,从而提高查询效率。
- 选择合适的分桶方式:
- 哈希分桶:适用于分桶键的值分布较为均匀的场景,可以实现数据的均匀分布,提高查询效率。
- 随机分桶:适用于分桶键的值分布不均匀的场景,可以通过随机分桶来实现数据的均匀分布,提高查询效率。
如果分区和分桶还不能满足查询要求,那么还可以在基础表上建立物理视图,这个在另一篇详细介绍!
谢谢观看,欢迎补充和指正!

















 2080
2080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









