






Pandas
pandas强力支持着当前各种领域的数据统计分析工作。
pandas提供两种数据结构:一维数组Series(系列)和二维数组Dataframe(数据帧)
提供的方法:增、查、改、删、合并、重塑、分组、统计分析
提供I/O工具:用于读取文本、excel文件,数据库等不同来源的数据。
pandas以及对excel的操作
1、df = pd.read_excel(in_file, sheet_name='测试集')
读取in_file为excel格式的数据,指定sheet_name名称,数据放到DataFame中。
2、df.iterrows()
for index, row in df.iterrows():返回:第一次循环,index为0, row为Series,包含df的“列名” 、“第一行的所有数据”

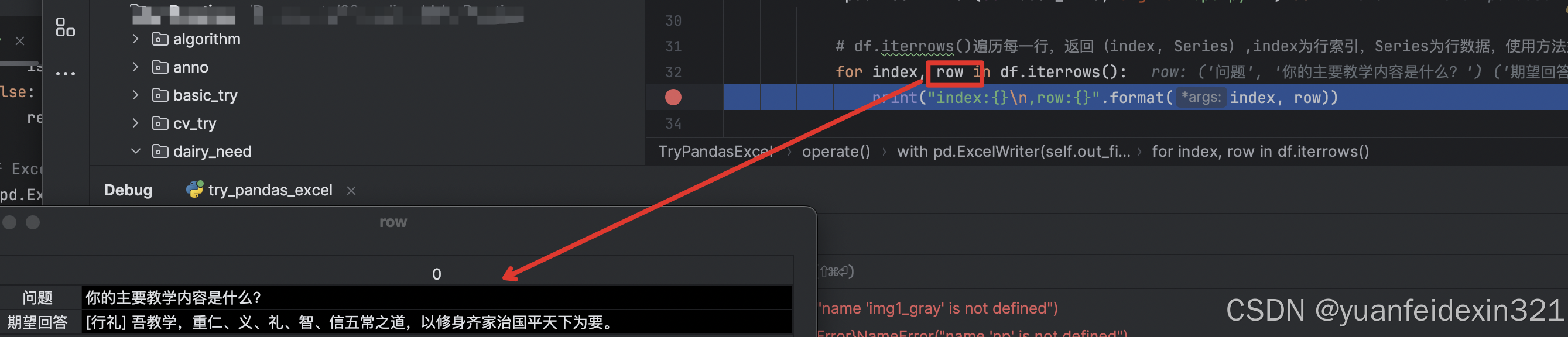
3、query = row['问题']
即可获取第一行,列为'问题'的内容
4、pd.Series({
'问题': str(index) + '问题',
'实际答案': str(index) + '实际答案',
})
创建一个Series对象,包换了一系列的键值对。
5、Series数组变成DateFrame对象
results.append(pd.Series({
'问题': str(index) + '问题',
'实际答案': str(index) + '实际答案',
}))
df_result = pd.DataFrame(results)

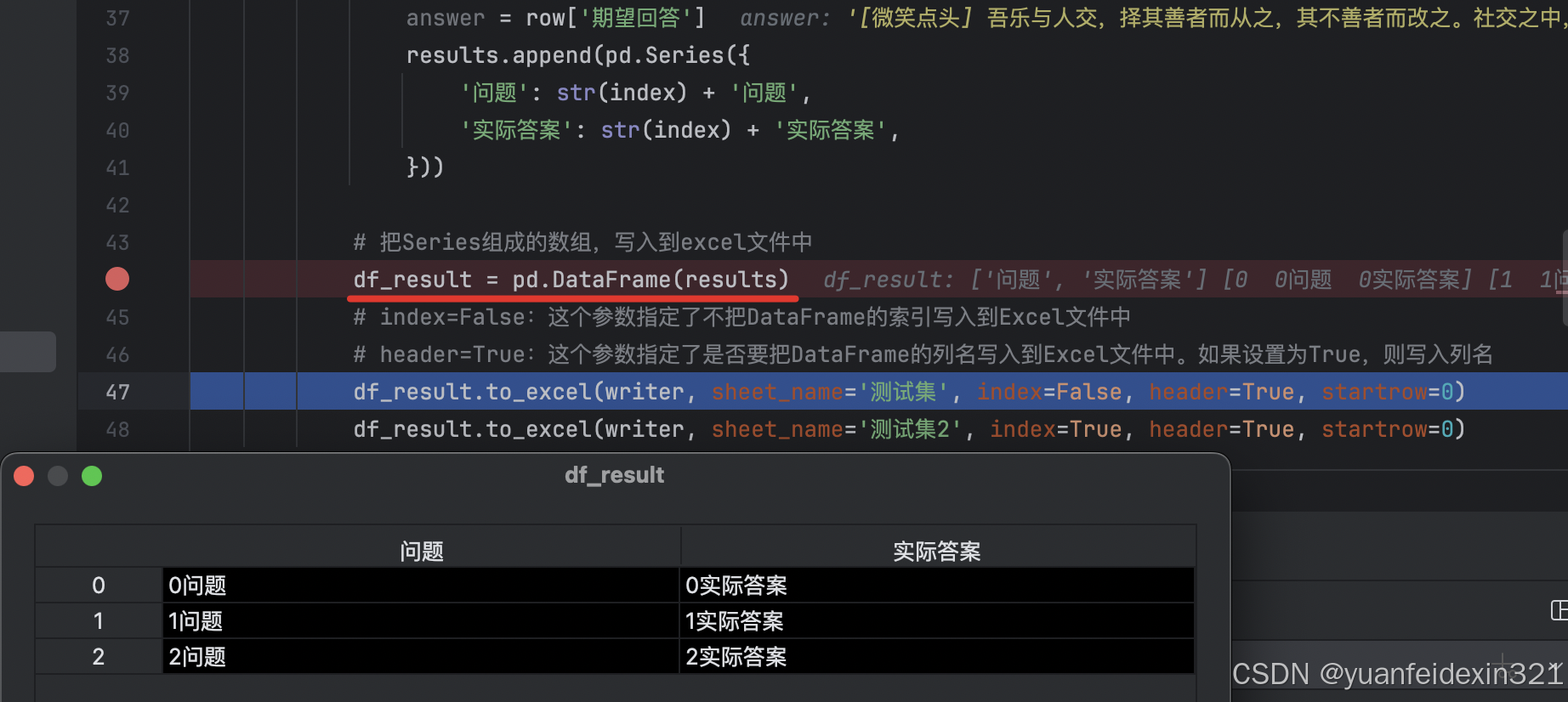
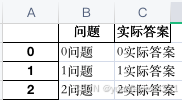
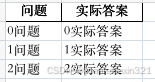
6、按照dataFrames写入到excel中 df_result.to_excel(writer, sheet_name='测试集', index=False, header=True, startrow=0) df_result.to_excel(writer, sheet_name='测试集2', index=True, header=True, startrow=0) # index=False:这个参数指定了不把DataFrame的索引写入到Excel文件中 # header=True:这个参数指定了是否要把DataFrame的列名写入到Excel文件中。如果设置为True,则写入列名

















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









