




 SENet通过SE模块引入通道注意力,强化卷积神经网络的表达能力。Squeeze操作全局压缩特征信息,Excitation操作则自适应地重新校准特征,使网络能关注重要通道并抑制无效信息。
SENet通过SE模块引入通道注意力,强化卷积神经网络的表达能力。Squeeze操作全局压缩特征信息,Excitation操作则自适应地重新校准特征,使网络能关注重要通道并抑制无效信息。
SENet简介
\space\space\space\space\space\space
一般的卷积神经网络,卷积核会融合局部感受野中空间以及通道方向的信息来产生新特征。通过叠加一系列与非线性层和降采样层交织的卷积层,卷积神经网络能够捕获具有全局感受野的层次模式,作为图像的描述。
\space\space\space\space\space\space
近来一些方法通过强化对特征图空间相关性的学习来增强网络的表达能力,如Inception结构。这篇文章从不同的角度出发 ,通过SE模块对特征图通道之间的相互依赖关系建模来提高网络的表达能力。为了实现这一点,文章提出了一种允许网络对特征图在通道方向上进行自适应重新校准的机制,通过该机制,网络可以学习根据全局信息有选择地强化有用的特征并抑制不太有用的特征。
\space\space\space\space\space\space
SE(Squeeze-and-Excitation)模块如下图所示。

一个特征图
X
∈
R
H
′
×
W
′
×
C
′
X\in\R^{H'\times W'\times C'}
X∈RH′×W′×C′,经过一系列卷积操作
F
t
r
F_{tr}
Ftr,得到特征图
U
∈
R
H
×
W
×
C
U\in\R^{H\times W\times C}
U∈RH×W×C,然后
U
U
U进入SE模块:
1、S(Squeeze)操作:对特征图
U
U
U在空间维度上进行压缩,生成
1
×
1
×
C
1\times1\times C
1×1×C的特征向量。即对特征图每个通道
H
×
W
H\times W
H×W的空间信息整合为一个实数,这个实数蕴含了对应通道的
H
×
W
H\times W
H×W特征图的全局分布信息。这样使得网络浅层也可以利用全局感受野的信息。
2、E(Excitation)操作:根据通道的依赖关系,基于门机制为每个通道学习特定的权重。
3、reweight操作:将E操作生成的每个通道的权重赋予原输出特征图
U
U
U,作为SE模块的输出。
SENet细节
SE(Squeeze-and-Excitation)模块
\space\space\space\space\space\space
F
t
r
F_{tr}
Ftr记为一次卷积操作,将输入特征图
X
∈
R
H
′
×
W
′
×
C
′
X\in\R^{H'\times W'\times C'}
X∈RH′×W′×C′转换为输出特征图
U
∈
R
H
×
W
×
C
U\in\R^{H\times W\times C}
U∈RH×W×C。
V
=
[
v
1
,
v
2
,
.
.
.
,
v
C
]
V=[v_1,v_2,...,v_C]
V=[v1,v2,...,vC]表示一共有
C
C
C个卷积核。输出特征图有
C
C
C个通道即
U
=
[
u
1
,
u
2
,
.
.
.
,
u
C
]
U=[u_1,u_2,...,u_C]
U=[u1,u2,...,uC]。输入特征图有
C
′
C'
C′个通道即
X
=
[
x
1
,
x
2
,
.
.
.
,
x
C
′
]
X=[x^1,x^2,...,x^{C'}]
X=[x1,x2,...,xC′]。
C
C
C个卷积核中第
c
c
c个卷积核可以表示为
v
c
=
[
v
c
1
,
v
c
2
,
.
.
.
,
v
c
C
′
]
v_c=[v_c^1,v_c^2,...,v_c^{C'}]
vc=[vc1,vc2,...,vcC′]。那么输出中第
c
c
c个通道的特征图
u
c
u_c
uc可以表示为(其中“
∗
*
∗”为卷积操作)
u
c
=
v
c
∗
X
=
∑
s
=
1
C
′
v
c
s
∗
x
s
u_c=v_c*X=\sum\limits_{s=1}^{C'}v_c^s*x^s
uc=vc∗X=s=1∑C′vcs∗xs
卷积操作是将卷积核与特征图在空间维度方向和通道维度方向上的对应元素相乘再求和,那么学习得到的卷积核是隐含有该特征图通道之间的依赖信息的,但这一信息是与特征图空间相关性信息混在一起的。文章的目标是突出特征图通道之间的关系,因为每个通道的特征图含有不同的信息,文章想要使网络对于含有有用信息的那些通道中的特征图更加敏感,而抑制没有包含多少有价值信息的特征图。文章用SE模块来实现这一目标,通过重新校准不同通道的特征图,使网络对于不同通道有不同的响应。
Squeeze操作(全局信息融合)
\space\space\space\space\space\space
为了判断每个通道中的特征图哪一个含有有用信息,哪一个不包含什么有用的信息,我们希望通过每个通道特征图的整体信息综合判断。然而输出特征图
U
U
U每个像素只包含局部感受野的信息,无法探索更多的上下文信息,这一问题对于浅层更严重,因为浅层特征图每个像素对应的感受野更小。
\space\space\space\space\space\space
为了得到全局特征信息,文章使用global average pooling,将每个通道的特征图压缩为一个实数,融合了这一通道特征图的全局信息,并将这个实数作为该通道的“标识符”。global average pooling产生一个向量
z
∈
R
C
z\in\R^C
z∈RC,对于第
c
c
c个元素,计算如下:
z
c
=
F
s
q
(
u
c
)
=
1
H
×
W
∑
i
=
1
H
∑
j
=
1
W
u
c
(
i
,
j
)
z_c=F_{sq}(u_c)=\dfrac{1}{H\times W}\sum\limits_{i=1}^{H}\sum\limits_{j=1}^{W}u_c(i,j)
zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
融合全局信息的方式有很多,文章为了简化问题选择了global average pooling。
Excitation操作(自适应重新校准)
\space\space\space\space\space\space
Excitation操作利用Squeeze操作整合的各通道信息,提取特征图通道之间的依赖关系。为了实现这一目标,Excitation操作必须满足两个特性:1、Excitation操作必须很灵活(特别是,它必须能够学习通道之间的非线性相互作用)2、它必须学习一种非互斥关系,因为通道之间是有相互依赖关系的,所以我们希望确保多个通道能够同时被激活,而不是一次只激活一个通道。为了实现这些特性,文章选择使用带有sigmoid函数的门机制:
s
=
F
e
x
(
z
,
W
)
=
σ
(
g
(
z
,
W
)
)
=
σ
(
W
2
δ
(
W
1
z
)
)
s=F_{ex}(z,W)=\sigma(g(z,W))=\sigma(W_2\delta(W_1z))
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
其中
δ
\delta
δ表示ReLU激活函数,
W
1
∈
R
C
r
×
C
W_1\in\R^{\frac{C}{r}\times C}
W1∈RrC×C和
W
2
∈
R
C
×
C
r
W_2\in\R^{C\times \frac{C}{r}}
W2∈RC×rC表示两个全连接层中的权值,这两层全连接层构成了瓶颈结构:
W
1
W_1
W1作为维度缩减层,将
z
z
z(Squeeze操作产生的特征向量)的维度从
C
C
C减小到了
C
r
\dfrac{C}{r}
rC,然后用ReLU激活,再通过维度增加层
W
2
W_2
W2,将
z
z
z的维度从
C
r
\dfrac{C}{r}
rC恢复为
C
C
C,最后再用sigmoid函数激活。
\space\space\space\space\space\space
Excitation操作产生的
C
C
C维向量与原输出特征图
U
U
U对应通道中的元素逐个相乘,得到的最终特征图作为SE模块的输出。最终输出的第
c
c
c个通道的特征图表示如下:
x
~
c
=
F
s
c
a
l
e
(
u
c
,
s
c
)
=
s
c
⋅
u
c
\tilde{x}_c=F_{scale}(u_c,s_c)=s_c\cdot u_c
x~c=Fscale(uc,sc)=sc⋅uc
其中
X
~
=
[
x
~
1
,
x
~
2
,
.
.
.
,
x
~
C
]
\tilde{X}=[\tilde{x}_1,\tilde{x}_2,...,\tilde{x}_C]
X~=[x~1,x~2,...,x~C]表示SE模块最终输出的特征图。
F
s
c
a
l
e
(
u
c
,
s
c
)
F_{scale}(u_c,s_c)
Fscale(uc,sc)表示第
c
c
c个通道的特征图
u
c
∈
R
H
×
W
u_c\in\R^{H\times W}
uc∈RH×W与Excitation操作产生的
C
C
C维向量的第
c
c
c个元素
s
c
s_c
sc相乘的结果。
SE模块的应用
\space\space\space\space\space\space
SE模块很灵活,可以“即插即用”到各种网络中。如下图给出了SE模块嵌入到Inception结构中以及嵌入到ResNet中。
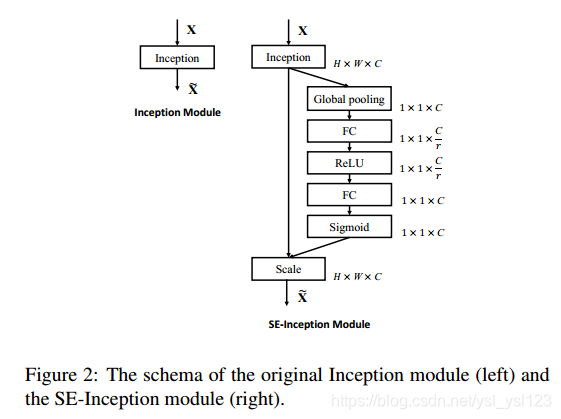
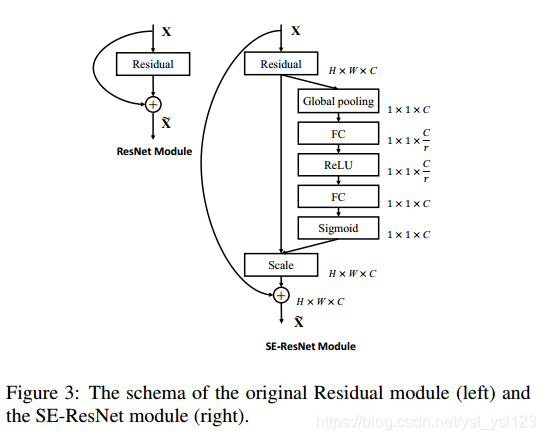
论文地址:Squeeze-and-Excitation Networks

















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









