







 本文详细介绍了生成对抗网络(GAN)的不同变体,从基础的GAN到DCGAN、InfoGAN、WGAN等,涵盖各种应用场景,如图像生成、图像到图像转换、超分辨率等。每种变体都强调了解决GAN训练中的问题,如稳定性、多样性、无监督学习和对抗性训练。
本文详细介绍了生成对抗网络(GAN)的不同变体,从基础的GAN到DCGAN、InfoGAN、WGAN等,涵盖各种应用场景,如图像生成、图像到图像转换、超分辨率等。每种变体都强调了解决GAN训练中的问题,如稳定性、多样性、无监督学习和对抗性训练。
1. GAN
我们提出了一个通过对抗过程来估计生成模型的新框架,其中我们同时训练两个模型:捕获数据分布的生成模型G和估计样本来自训练数据而不是生成模型概率的判别模型D。对G的训练过程是最大化D出错的概率。这个框架对应于一个极小型双人游戏。在任意函数G和D的空间中,存在唯一的解决方案,其中G恢复训练数据分布并且D等于1/2处。 在G和D由多层感知器定义的情况下,整个系统可以通过传播进行训练。在训练或生成样本期间,不需要任何马尔可夫链或展开的近似推理网络。实验通过定性和定量评估生成的样本来证明框架的潜力。
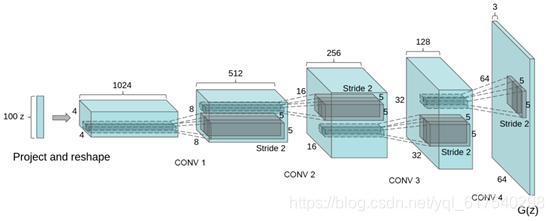
2. DCGAN
近年来,卷积神经网络(CNN)的监督式学习在计算机视觉应用中得到了广泛的应用。相比之下,无监督的CNN学习受到的关注较少。在这项工作中,我们希望能够帮助弥合有监督学习的CNN成功与无视学习之间的差距。我们引入了CNN级别的深度卷积生成对抗网络(DCGAN),它具有一定的架构约束,并且证明它们是非监督学习的有力候选。对各种图像数据集进行训练,我们展示出令人信服的证据,证明我们深层卷积对抗对从发生器和鉴别器中的对象部分到场景学习了表示层次。此外,我们使用学习的功能进行新颖的任务--证明其作为一般图像表示的适用性。
原始GAN训练较为困难、生成器和判别器的loss无法指示训练进程、生成样本缺乏多样性。DCGAN为解决这个问题,对判别器和生成器的架构进行实验枚举,最终找到一组比较好的网络架构设置。
在DCGAN中,比较新颖的实验效果是实现了人脸特征的加减运算:

微笑的女人-自然的女人+自然的男人=微笑的男人

戴眼镜的男人-不戴眼镜的男人+不戴眼镜的女人=戴眼镜的女人
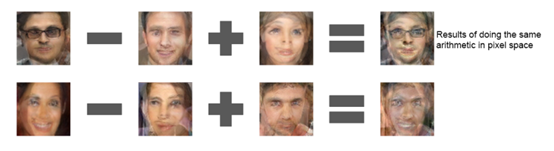
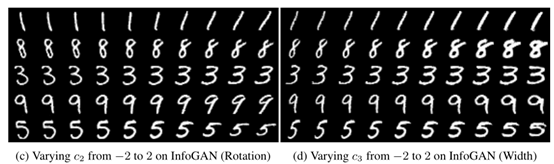
3. InfoGAN
本文描述了InfoGAN,它是对生成敌对网络的信息论扩展,能够以完全无监督的方式学习解耦表示。InfoGAN是一种生成性的对抗性网络,它可以最大化潜在变量的一小部分与观察之间的相互信息。我们推导出可以有效优化的互信息目标的下界。具体而言,InfoGAN成功解开了MNIST数据集中数字形状的书写风格,3D渲染图像的光照姿势以及SVHN数据集中央数字的背景数字。它还发现包括发型,眼镜的存在/不存在以及CelebA脸部数据集上的情绪等视觉概念。实验表明,InfoGAN学习可解释的表示,这些表示与现有监督方法学习的表示相比具有竞争性。
在实验中,InfoGAN实现了数据集的粗细、旋转:

4. WGAN
(and Improved Training of Wasserstein GANs)
WGAN彻底的解决GAN训练不稳定的问题,不需要再小心平衡生成器和判别器的训练程度,基本解决了collapse mode(崩溃模式)的问题,确保了生成样本的多样性。原始GAN问题的根源归结为两点:
①等价优化的距离衡量(KL散度、JS散度)不合理;
②生成器G随机初始化后的生成分布很难与真实分布有不可忽略的重叠。
WGAN与原始GAN相比,更改如下:
①判别器最后一层去掉sigmoid(真假二分类任务->回归任务)
②生成器和判别器的loss不取log
③每次更新判别器的参数之后把它们的值截断到不超过一个固定常数c
④不要用基于动量的优化算法(包括momentum和Adam,推荐RMSProp)
parser.add_argument('--adam', action='store_true', help='Whether to use adam (default is rmsprop)')
WGAN提出Wasserstein距离(Ear
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











