




原文出自彼得攀的小站
本文是对论文“A Survey on Dialogue Systems: Recent Advances and New Frontiers”的阅读笔记,该文章是关于对话系统的综述,最后一次修改于2018年年初,主要对2018年之前对话系统相关技术做了一个概要性总结
论文地址
文中[45]这样的编号代表论文中参考文献的编号,可以查阅原始论文
引言
深度学习技术是现在对话系统采用的主流技术,其可以通过大规模数据来学习有意义的特征表示,并得到较好的文本生成策略,该过程仅需要很少、或者完全不需要人工特征。
对话系统可以被分为task-oriented(任务导向)和non-task-oriented (非任务导向)
Introduction
面向任务的系统旨在帮助用户完成某些任务(例如查找产品,预订住宿和餐馆)。广泛应用于面向任务的对话系统的方法是将对话回复作为一个流水线来处理。系统首先理解人类给出的信息,将其表示为一个内部状态,然后根据策略和对话状态选择一些动作,最后把动作转化为自然语言的表达形式。尽管语言理解是通过统计模型来处理的,但是大多数已部署的对话系统仍然使用人工特征或人工编写的规则来处理状态和动作空间的表示,意图检测和槽填充。这不仅使得部署真正的对话系统耗费大量时间,而且还限制了其在其他领域进行使用的能力。最近,许多基于深度学习的算法通过学习高维分布式特征表示来缓解这些问题,并在一些方面取得了显著的进步。此外,还有尝试建立端到端的面向任务的对话系统,这种对话系统可以扩展传统流水线系统中的状态空间表示,并有助于生成任务特定语料库以外的对话。
非面向任务的系统在与人类交互过程中提供合理的反应和娱乐。通常,非面向任务的系统致力于在开放域与人交谈。虽然非面向任务的系统似乎在进行闲聊,但是却在许多实际的应用程序中占有一席之地。 有研究表明,近80%在线购物场景中的对话都是闲聊消息,而处理这些信息与用户体验密切相关。一般而言,针对非面向任务的系统开发了两种主要方法:
- 生成方法,例如seq2seq模型,其在对话过程中产生适当的回复;
- 基于检索的方法,学习从数据库中选择当前对话的回复。
任务导向的对话系统
这里主要介绍流水线方法(Pipline methods)和端到端方法(end-to-end methods)
流水线方法
流水线方法的示意图如下所示:
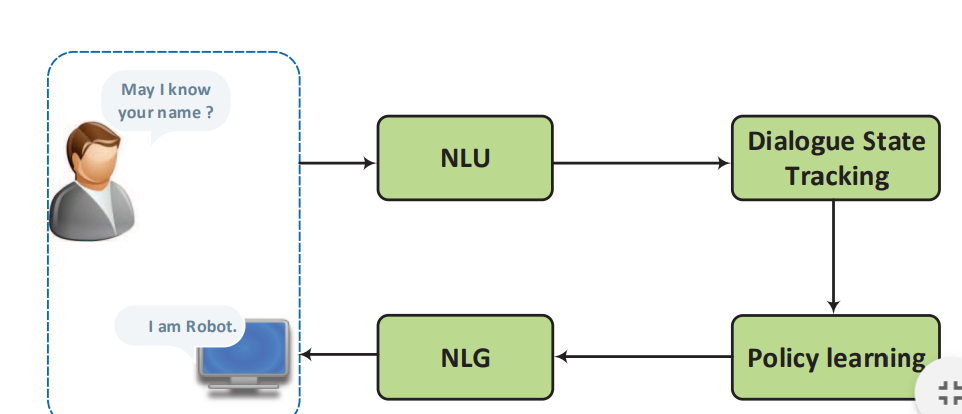
其包含四个部分:
- 语言理解:通常被认为是自然语言理解(NLU),它把用户意图解析成预定义的语义槽
- 对话状态追踪器(Dialogue State Tracking):其管理每轮对话的输入及历史状态,并输出当前的对话状态
- 对话策略学习(Dialogue policy learning):其根据当前的对话状态来学习下一步的动作
- 自然语言生成(NLG):其将学习到的动作映射到表层,生成回复
语言理解(NLU)
语言理解的任务是:给定一句话,NLU将其映射到语义槽中,这些语义槽都是根据不同的对话场景预定义的。
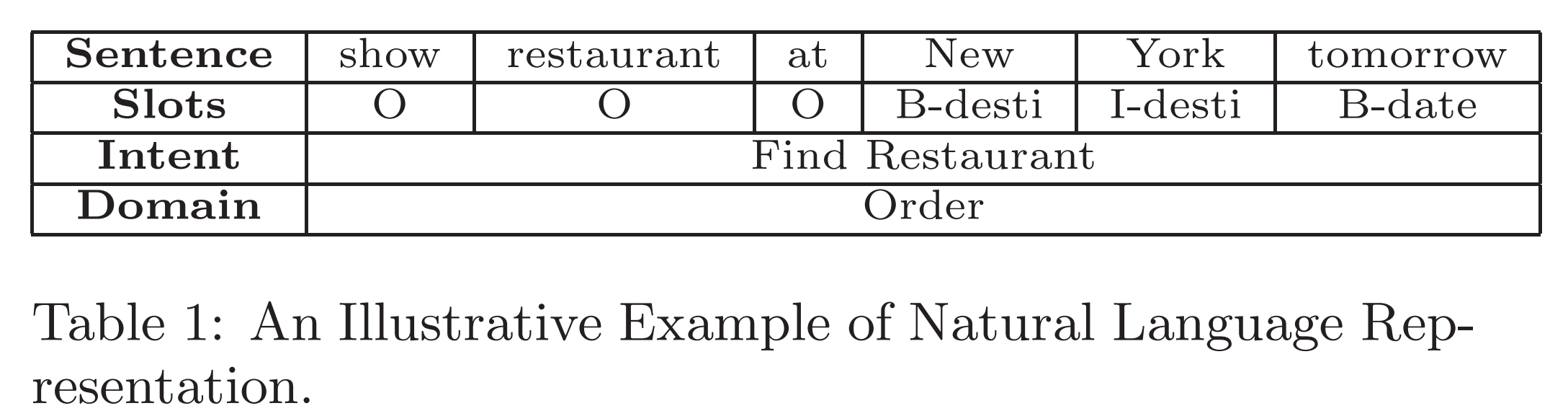
上图是一个自然语言表示的例子,"New York"被映射到了desti这一个语义槽,在映射过程中同时确定了该对话的领域:order和对话意图:预定餐馆。
通常来说, 有两种不同类型的语言表示:
- 对话级别(utterance-level):某种程度上可以理解成句子级别的表示,可以表示如用户意图、对话类别
- 词级别(word-level):即词级别的信息抽取,如命名实体识别、语义槽填充
整个NLU主要包含两个部分:
- 意图检测是用来检测用户意图的,它可以把对话分类为预定义的意图。在其中,深度学习也有着广泛应用,例如利用CNN提取查询的向量表示作为特征,从而对查询做分类。类似的方法也应用于语言主题、领域分类
- 槽填充(Slot filling)是口语语言理解中另一个具有挑战性的问题。与意图检测不同,槽填充通常被定义为序列标注问题,句子中的词被赋予语义标签。输入是由一系列单词组成的句子,输出是一个槽/概念的索引序列,每个单词一个。现有的方法使用深度信念网络(DBN),与CRF方法相比取得了优异的结果。同样也有使用RNN做槽填充。
由NLU生成的语义表示将有对话管理模型进一步处理,典型的对话管理模包括两个部分:对话状态追踪(Dialogue State Tracking)和策略学习(Policy learning)
对话状态跟踪(Dialogue State Tracking)
对话状态追踪是保证对话系统鲁棒性的核心组成部分。它会估计每轮对话中用户的意图。对话状态 H t H_t Ht表示到时刻t时,整个对话历史的表示。
这种经典的状态结构通常被称为槽填充(slot filling)和语义框架(semantic frame)。传统方法(也是迄今为止大多数商业系统选择的方法)通常采用手工制订的规则来选择最有可能的结果。然而这样的基于规则的系统很容易出现错误,其得出的最有可能的结果往往不是理想的结果。
基于统计的对话系统在有噪声的条件和不确定的情况下,维护了对真实对话状态的多重假设的分布。在对话状态跟踪中,生成结果的形式是每轮对话中每个语义槽的值的概率分布。各种统计方法,包括复杂的手工制定规则、条件随机场、最大熵模型、网络风格排名(web-style ranking)都被应用在了对话状态跟踪的共享任务中。
当前,结合了深度学习的信念追踪表现出了更好的效果。 它使用一个滑动窗口输出任意数量的可能值的一系列概率分布。虽然它是在某一个领域的训练出来的,但它可以很容易地转移到新的领域。[48]开发了多领域RNN对话状态跟踪模型。它首先使用所有可用的数据来训练一个泛化的信念跟踪模型,然后对每一个特定领域利用这个泛化模型进行领域化,从而学习领域特定的行为。[49]提出了一个神经信念跟踪器(NBT)来检测槽-值对。它将用户输入之前的系统对话行为、用户说话本身和一个候选slot-value对作为输入,然后遍历所有候选slot-value对,以确定用户刚刚表达了哪些slot-value对
策略学习(policy learning)
记忆状态跟踪器获得的状态表示,策略学习(policy learning)将产生下个可用的系统动作。无论是监督学习还是强化学习都可以被用于优化策略学习。通常,基于规则的智能体将被用于热启动系统[86],然后利用规则生成的动作进行监督学习。在在线购物场景中,如果对话状态是“推荐”,那么“推荐”动作将被触发,系统将会从产品数据库中检索产品。如果状态是“比较”,系统则会比较目标产品/品牌[98]。对话策略可以通过进一步端到端的强化学习进行训练,以引导系统朝着最终性能做出决策。[9]在对话策略中利用深度强化学习,同时学习特征表示和对话策略。该系统超过了包括随机、基于规则和基于监督学习的baseline方法。
自然语言生成(NLG)
自然语言生成将通过policy learning得到的抽象的对话动作转化为自然语言的浅层对话,在[78]中,提到一个好的生成器通常满足4个条件:
- 充分性(adequacy)
- 流利性(fluency)
- 可靠性(readability)
- 变化性(variation)
传统的NLG通常采用句子规划(sentence planning),其将输入的语义符号映射成表示对话的树状结构或模板结构等中间形式,然后通过表层实现(surface realization)将中间结构转换成最终结果。
[94]和[95]引入了基于神经网络的NLG方法,该方法采用了一个类似于RNNLM的LSTM-based 结构。其将对话动作类型和slot-value pair转化为一个one-hot词向量作为额外输入,来确保生成的对话能够准备表达我们所要表达的意图。[94]时使用了一个前向RNN生成器、一个CNN重排器、一个后向RNN重排器,所有的子模块共同作用,基于需要的对话动作来生成对话。为了解决在表层实现(surface realization)中槽信息缺失和重复的问题,[95]使用了额外的控制单元来门控对话动作。[83]通过利用对话动作来选择LSTM的输入向量,扩展了这一方法。这个问题后来通过多步调整扩展到多领域场景[96]。[123]采用基于encoder-decoder的LSTM-based的结构,结合问题信息,语义槽值和对话动作类型来生成正确答案。它使用注意力机制来关注解码器当前解码状态的关键信息。通过编码对话动作类型嵌入,基于神经网络的模型可以生成许多不同动作类型的回复答案。[20]还提出了一种基于seq2seq的自然语言生成器,可以被训练用于利用对话动作输入来产生自然语言和深度语法树。这种方法后来
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3206
3206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









