



文章详细介绍了五种AI Agent核心设计模式:ReAct模式通过推理-行动循环处理外部信息任务;CodeAct模式通过生成代码解决复杂计算;计划模式提供结构化执行路径,支持动态调整;反思模式通过迭代优化提升输出质量;人机协作模式在关键节点引入人工判断。每种模式均包含核心理念、工作流程、实战案例、适用场景和注意事项,帮助开发者构建高效可靠的Agent系统。
前言
随着大语言模型(LLM)能力的快速提升,AI Agent 已经从概念走向实践。然而,如何让 Agent 更可靠、更高效地完成复杂任务,成为开发者面临的关键挑战。
就像软件工程中的设计模式为常见问题提供了经过验证的解决方案,Agent 开发同样需要成熟的设计模式来指导实践。本文介绍五种核心模式:ReAct 通过推理与行动的交替循环处理需要外部信息的任务,CodeAct 通过生成代码应对复杂计算,计划模式为结构化任务提供清晰执行路径,反思模式通过迭代改进提升输出质量,人机协作模式在关键节点引入人工判断。
本文将深入介绍这五种核心 Agent 设计模式,通过理论讲解与实战案例,帮助你快速掌握每种模式的工作原理、适用场景和实现要点。
一、ReAct 模式
1.1 什么是 ReAct
ReAct(Reasoning + Acting)是一种将推理(Reasoning)和行动(Acting)相结合的 Agent 设计模式。它的核心思想是让 LLM 在解决问题时,不是一次性给出答案,而是模拟人类的思维过程:边思考、边行动、边观察结果,然后继续思考。
这种模式特别适合处理需要外部信息或工具支持的任务。通过将复杂问题分解为多个"思考-行动-观察"的小步骤,Agent 能够逐步逼近最终答案,整个过程更加透明、可控。
1.2 工作流程
ReAct 的核心流程可以概括为一个循环:Thought → Action → Observation → Thought。在每次循环中,Agent 首先进行思考阶段,分析当前问题和已有信息,决定下一步需要采取什么行动。例如,当需要查询股票价格时,Agent 会思考"我需要查询青岛啤酒的股票收盘价"。
接着进入行动阶段,Agent 选择合适的工具并指定参数,如 Action: get_closing_price 和 Action Input: {"name": "青岛啤酒"}。工具执行后进入观察阶段,将执行结果反馈给 Agent,例如 Observation: 67.92。Agent 收到观察结果后,会判断问题是否已经解决。如果未解决,则继续下一轮思考-行动-观察循环;如果已解决,则输出最终答案。
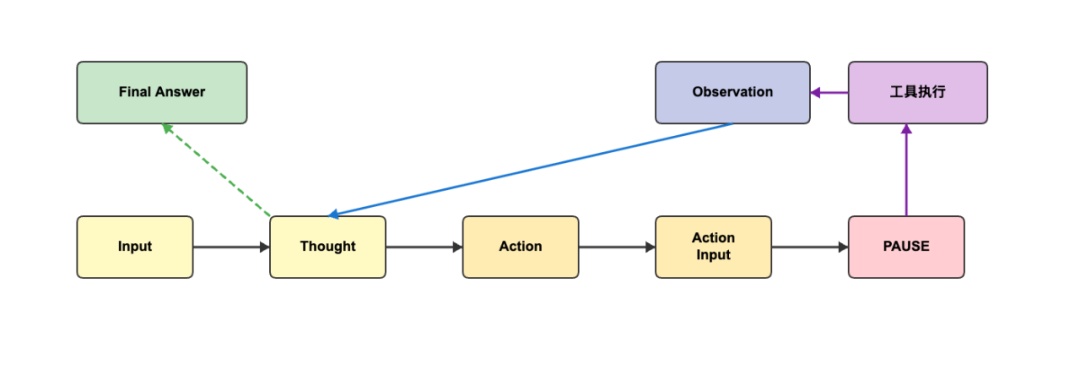
流程图展示了 ReAct 的完整执行过程。在底部的主流程中,Input 经过 LLM 推理后依次生成 Thought、Action、Action Input 和 PAUSE 标记。PAUSE 触发工具执行,执行结果形成 Observation 并返回给 LLM,由此形成一个闭环。当 LLM 判断已获得足够信息时,会从 Thought 节点输出 Final Answer,结束整个流程。
1.3 实战案例
案例:比较两个股票的收盘价
任务: 请比较青岛啤酒和贵州茅台的股票收盘价谁高?
核心代码实现
1. 工具定义与注册
// 工具定义(JSON Schema 格式)const tools = [ { name: 'get_closing_price', description: '使用该工具获取指定股票的收盘价', parameters: { type: 'object', properties: { name: {type: 'string', description: '股票名称'}, }, required: ['name'], }, },]// 工具注册表(工具名 -> 实现函数)const toolRegistry = { get_closing_price: (params) => getClosingPrice(params.name),}
2. Prompt 模板(关键部分)
const REACT_PROMPT = `You run in a loop of Thought, Action, Action Input, PAUSE, Observation.At the end of the loop you output an Answer.Your available actions are: {tools}Example:Question: 今天北京天气怎么样?Thought: 我需要调用 get_weather 工具获取天气Action: get_weatherAction Input: {"city": "BeiJing"}PAUSEObservation: 北京的气温是0度.Final Answer: 北京的气温是0度.New input: {input}`
3. Agent 主循环(核心逻辑)
async function reactAgent(query: string) {// 构建初始提示词const prompt = REACT_PROMPT.replace('{tools}', JSON.stringify(tools)).replace( '{input}', query )const messages = [{role: 'user', content: prompt}]while (true) { // 1. 调用 LLM const response = await llm.chat(messages) const text = response.content // 2. 检查是否有最终答案 if (text.includes('Final Answer:')) { return text.match(/Final Answer:\s*(.*)/)[1] } // 3. 解析 Action 和 Action Input const action = text.match(/Action:\s*(\w+)/)?.[1] const input = text.match(/Action Input:\s*({.*})/s)?.[1] if (!action || !input) break // 4. 执行工具 const params = JSON.parse(input) const observation = await toolRegistry[action](params) // 5. 将 LLM 响应和 Observation 加入历史 messages.push( {role: 'assistant', content: text}, {role: 'user', content: `Observation: ${observation}`} ) }}
Agent 的执行逻辑相对简单直接。首先用 Prompt 模板初始化消息,将工具列表和用户问题注入其中。然后进入主循环,不断调用 LLM 直到出现 Final Answer 标记。在每次循环中,解析 LLM 输出的 Action 和 Action Input,从工具注册表中找到对应的工具函数并执行,最后将执行结果作为 Observation 反馈给 LLM,开启下一轮循环。
运行结果示例
第一轮:Thought: 我需要获取青岛啤酒的股票收盘价Action: get_closing_priceAction Input: {"name": "青岛啤酒"}→ Observation: 67.92第二轮:Thought: 现在需要获取贵州茅台的收盘价Action: get_closing_priceAction Input: {"name": "贵州茅台"}→ Observation: 1488.21最终答案:贵州茅台的股票收盘价(1488.21)比青岛啤酒(67.92)高得多
1.4 使用 Function Call 来实现
前面展示的是经典的 ReAct 模式实现,需要通过 Prompt 让 LLM 输出特定格式(Thought/Action/Observation),然后手动解析这些文本。而现代 LLM API 都支持 Function Calling(函数调用),这让 ReAct 的实现变得更简单、更可靠。
核心代码实现
1. 工具定义(标准 OpenAI 格式)
import {ChatCompletionTool} from'openai/resources/chat/completions'exportconst tools: ChatCompletionTool[] = [ { type: 'function', function: { name: 'get_closing_price', description: '使用该工具获取指定股票的收盘价', parameters: { type: 'object', properties: { name: { type: 'string', description: '股票名称', }, }, required: ['name'], }, }, },]// 工具注册表exportconst toolRegistry: Record<string, (params: any) =>string> = { get_closing_price: (params) => getClosingPrice(params.name),}
2. Agent 主循环(Function Call 版本)
async function functionCallAgent(query: string) {const messages: ChatCompletionMessageParam[] = [ {role: 'user', content: query}, ]while (true) { // 1. 调用 LLM,传入 tools 配置 const response = await client.chat.completions.create({ model: 'gpt-4o', messages, tools, tool_choice: 'auto', // LLM 自动决定是否调用工具 }) const choice = response.choices[0] if (!choice?.message) break const toolCalls = choice.message.tool_calls // 2. 如果没有工具调用,说明已经得到最终答案 if (!toolCalls || toolCalls.length === 0) { console.log('最终答案:', choice.message.content) break } // 3. 执行工具调用 messages.push(choice.message) // 保存 LLM 的工具调用请求 for (const toolCall of toolCalls) { if (toolCall.type === 'function') { const toolName = toolCall.function.name const args = JSON.parse(toolCall.function.arguments) const toolFunc = toolRegistry[toolName] if (toolFunc) { const result = toolFunc(args) // 4. 将工具执行结果返回给 LLM messages.push({ role: 'tool', content: result, tool_call_id: toolCall.id, }) } } } }}
1.5 使用 LangGraph 实现
对于复杂的 Agent 场景(需要记忆、反思、人工介入等),LangGraph 提供了声明式的图结构定义,更易于维护和扩展。
LangGraph 将 Agent 建模为状态图,其中节点代表执行具体任务的函数,边定义节点之间的转换规则,而状态则是在各个节点之间传递的数据。这种抽象让 Agent 的执行流程更加清晰可控。
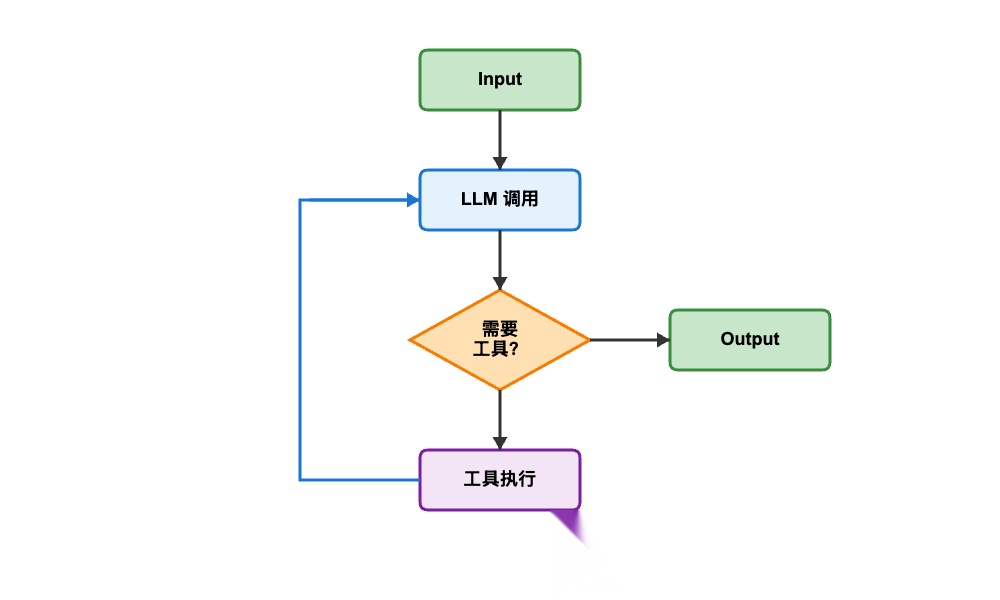
核心代码
构建图:
import {StateGraph, END} from'@langchain/langgraph'import {Annotation} from'@langchain/langgraph'// 1. 定义状态const GraphState = Annotation.Root({ messages: Annotation<BaseMessage[]>({ reducer: (x, y) => x.concat(y), default: () => [], }),})// 2. 定义节点const llm = new ChatOpenAI({model: 'gpt-4o'}).bindTools(tools)asyncfunction callModel(state: typeof GraphState.State) {const response = await llm.invoke(state.messages)return {messages: [response]}}asyncfunction callTools(state: typeof GraphState.State) {const lastMessage = state.messages[state.messages.length - 1]const toolMessages = awaitPromise.all( lastMessage.tool_calls.map(async (tc) => { const tool = tools.find((t) => t.name === tc.name) const result = await tool.invoke(tc.args) returnnew ToolMessage({content: String(result), tool_call_id: tc.id}) }) )return {messages: toolMessages}}// 3. 路由函数function shouldContinue(state: typeof GraphState.State) {const lastMessage = state.messages[state.messages.length - 1]return lastMessage.tool_calls?.length > 0 ? 'tools' : END}// 4. 构建图function buildGraph() {returnnew StateGraph(GraphState) .addNode('agent', callModel) .addNode('tools', callTools) .addEdge('__start__', 'agent') .addConditionalEdges('agent', shouldContinue) .addEdge('tools', 'agent') .compile()}// 5. 运行const app = buildGraph()await app.invoke({messages: [new HumanMessage('问题')]})
其实 @langchain/langgraph 提供了 createReactAgent,可以更加方便的实现类似功能:
import {createReactAgent} from'@langchain/langgraph/prebuilt'import {ChatOpenAI} from'@langchain/openai'import {tool} from'@langchain/core/tools'import {z} from'zod'// 定义工具const getClosingPriceTool = tool((input) => { const name = (input as {name: string}).name if (name === '青岛啤酒') return'67.92' if (name === '贵州茅台') return'1488.21' return'未搜到该股票' }, { name: 'get_closing_price', description: '获取指定股票的收盘价', schema: z.object({name: z.string().describe('股票名称')}), })// 创建 Agent(一行代码)const agent = createReactAgent({ llm: new ChatOpenAI({model: 'gpt-4o'}), tools: [getClosingPriceTool],})// 运行const result = await agent.invoke({ messages: [{role: 'user', content: '比较青岛啤酒和贵州茅台的收盘价'}],})
1.6 适用场景
ReAct 模式特别适合需要外部信息或工具支持的任务。当问题无法仅凭 LLM 内部知识解决时,比如查询实时数据、调用 API、执行计算等,ReAct 通过工具调用弥补了 LLM 的能力边界。这种模式对于多步骤推理任务也很有效,Agent 可以逐步收集信息、分析结果、调整策略,最终得出答案。同时,ReAct 的透明性让整个推理过程可观察可调试,便于理解 Agent 的决策逻辑。
1.7 注意事项
实现 ReAct 模式时需要注意几个关键点。Prompt 设计至关重要,需要清晰地定义 Thought、Action、Observation 的格式,并提供足够的示例帮助 LLM 理解预期输出。工具描述要准确明确,让 LLM 能够正确选择和使用工具。同时要设置合理的迭代次数上限,避免陷入无限循环。错误处理机制也不可忽视,当工具调用失败或 LLM 输出格式错误时,需要有恰当的降级策略。此外,要注意 Token 消耗,因为每次迭代都会增加消息历史的长度。
二、CodeAct 模式
2.1 核心理念
CodeAct(Code as Action)让 Agent 通过生成并执行代码来完成任务。与 ReAct 调用预定义工具不同,CodeAct 赋予 Agent 更大的灵活性,特别适合复杂计算、数据处理或需要组合多个操作的场景。核心流程是:Thought → Code Generation → Code Execution → Observation。
2.2 工作流程
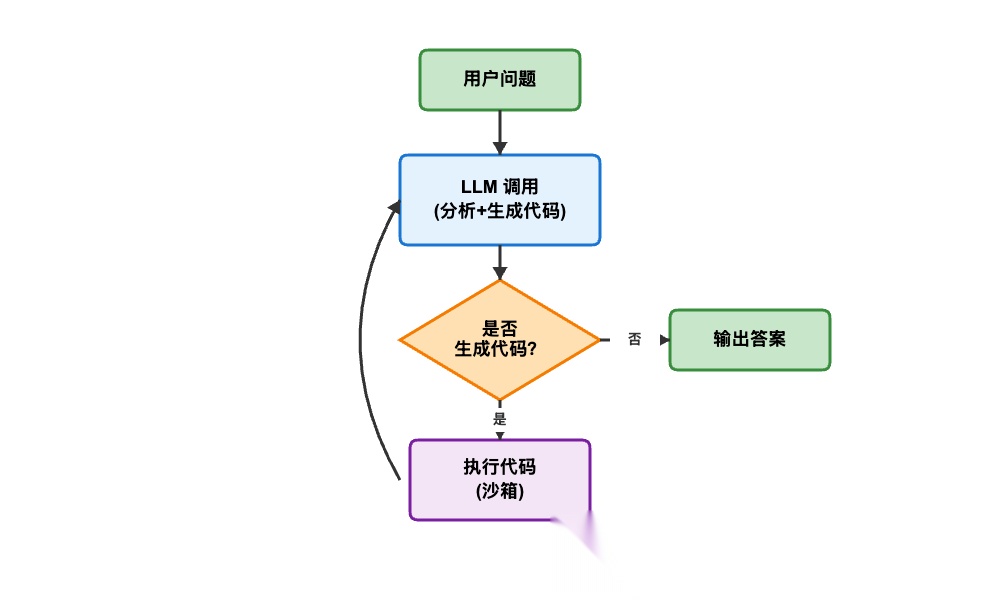
CodeAct 的执行流程从 LLM 分析用户问题开始,理解需要完成什么任务。接着 LLM 生成对应的代码(通常是 Python 或 JavaScript),这些代码会在沙箱环境中执行以保证安全性。执行结果作为 Observation 返回给 LLM,LLM 根据结果判断是继续生成新代码完善方案,还是已经得到满意答案可以结束流程。
2.3 实战案例
需求: 计算 1~100 的和
核心代码
1. 提示词(Prompt)
// prompts.tsexport const SYSTEM_PROMPT = `你是一个能够编写和执行代码的智能助手。当用户提出问题时,你需要:1. 分析问题并确定需要编写什么代码2. 编写能解决问题的 JavaScript 代码3. 代码必须将最终结果存储在 'result' 变量中4. 将代码包裹在 \`\`\`javascript 代码块中5. 分析执行结果,如果有错误则修改代码再次执行6. 最终给用户提供答案`
2. 工具(代码执行器)
// tools.tsimport {z} from'zod'import {tool} from'@langchain/core/tools'import vm from'vm'exportconst executePythonTool = tool((input) => { const code = (input as {code: string}).code try { console.log('执行代码:\n', code) // 使用 vm 创建沙箱环境 const context = {result: undefined, console} vm.createContext(context) vm.runInContext(code, context, {timeout: 5000}) const result = context.result ?? '执行成功' console.log('执行结果:\n', result) returnString(result) } catch (error: any) { return`代码执行错误: ${error.message}` } }, { name: 'execute_javascript', description: '执行 JavaScript 代码并返回结果', schema: z.object({ code: z.string().describe('要执行的 JavaScript 代码'), }), })
3. Agent 逻辑(LangGraph)
// graph.tsimport {StateGraph, END} from'@langchain/langgraph'import {Annotation} from'@langchain/langgraph'import {ChatOpenAI} from'@langchain/openai'import {AIMessage, HumanMessage, SystemMessage} from'@langchain/core/messages'import {SYSTEM_PROMPT} from'./prompts'import {executePythonTool} from'./tools'// 定义状态const CodeActState = Annotation.Root({ messages: Annotation<any[]>({ reducer: (x, y) => x.concat(y), default: () => [], }), output: Annotation<string>({default: () => ''}),userPrompt: Annotation<string>({default: () => ''}),})constllm = newChatOpenAI({model: 'gpt-4o'})// 提取代码functionextractCode(content: string) {if (content.includes('```javascript')) { constblocks = content.split('```javascript') constcode = blocks[1].split('```')[0].trim() returncode }returnnull}// LLM 节点asyncfunctionllmCall(state: typeof CodeActState.State) {constmessages = [ newSystemMessage(SYSTEM_PROMPT), newHumanMessage(state.userPrompt), ...state.messages, ]constresponse = awaitllm.invoke(messages)constcode = extractCode(response.content as string)if (code) { return { messages: [response], output: '', code, } }return { messages: [response], output: response.content, }}// 路由函数functionshouldExecute(state: typeof CodeActState.State) {returnstate.output ? END : 'executeNode'}// 执行节点asyncfunctionexecuteNode(state: typeof CodeActState.State) {constcode = (state as any).codeconstresult = awaitexecutePythonTool.invoke({code})return { messages: [newHumanMessage(`## 执行结果:\n${result}`)], }}// 构建图exportfunctionbuildCodeActGraph() {returnnewStateGraph(CodeActState) .addNode('llmCall', llmCall) .addNode('executeNode', executeNode) .addEdge('__start__', 'llmCall') .addConditionalEdges('llmCall', shouldExecute) .addEdge('executeNode', 'llmCall') .compile()}
4. 运行
const agent = buildCodeActGraph()const result = await agent.invoke({ userPrompt: '请计算 1~100 的和',})console.log(result.output)
运行效果
[启动 CodeAct Agent][用户问题] 请计算 1~100 的和[LLM 节点] 分析问题...[生成代码][执行节点] 运行代码...## 执行代码:let n = 100;let result = (n * (n + 1)) / 2;result;## 执行结果: 执行成功[LLM 节点] 分析问题...[直接给出答案][完成][最终答案] 很好!结果表明,1 到 100 的和是 5050。您是否还有其他数学问题或需要进一步的帮助?
从结果可以看到,大模型并没有使用循环,而是用等差数列求和公式来实现的,有点聪明的样子。
2.4 适用场景
CodeAct 模式特别适合需要灵活处理数据或进行复杂计算的场景。当任务涉及数学计算、数据转换、文本处理、算法实现等需要编程逻辑的操作时,生成代码往往比调用预定义工具更加高效和灵活。同时,对于需要组合多个操作或处理非标准化数据的任务,CodeAct 也展现出明显优势。这种模式让 Agent 不再局限于现有工具的能力边界,可以根据具体需求动态生成解决方案。
2.5 注意事项
使用 CodeAct 模式时必须高度重视安全性问题。代码执行必须在沙箱环境中进行,避免恶意代码对系统造成破坏。建议使用 vm 模块或 Docker 容器等隔离机制,并设置执行超时限制防止无限循环。此外,生成的代码质量依赖于 LLM 的能力,可能存在语法错误或逻辑错误,需要完善的错误处理机制。对于生产环境,还应该记录所有执行的代码以便审计和调试。
三、计划模式(Plan Mode)
3.1 核心理念
计划模式采用"先计划,后执行"的策略。ReAct 每步都需重新思考,适合探索性任务;计划模式则在开始时制定完整方案再逐步执行,更适合结构化程度高的任务。优势在于执行路径清晰、便于监控进度和预测资源消耗。但灵活性较低,初始计划不准确时可能需要人工调整。
3.2 工作流程
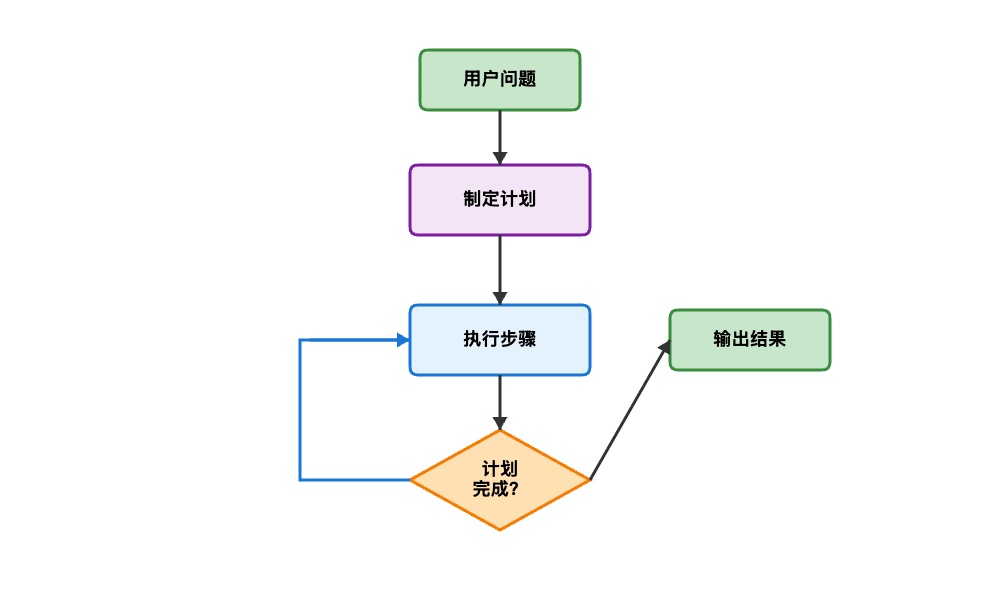
3.3 实战案例:简单计划模式
需求: 比较茅台和青岛啤酒哪个贵?
核心代码
1. 计划生成提示词
// prompts.tsexport const PLAN_PROMPT = `你是一个金融分析师,擅长对股票的收盘价进行比较。请为用户提出的问题创建分析方案步骤:可调用工具列表:get_closing_price: 根据股票名称获取收盘价要求:1. 用中文列出清晰步骤2. 每个步骤标记序号3. 明确说明需要分析和执行的内容4. 只需输出计划内容,不要做任何额外的解释和说明`export const PLAN_EXECUTE_PROMPT = `你是一个思路清晰,有条理的金融分析师,必须严格按照以下计划执行:当前计划:{plan}如果你认为计划已经执行到最后一步了,请在内容的末尾加上 Final Answer 字样`
2. 状态定义
// types.tsexport const PlanState = Annotation.Root({ messages: Annotation<BaseMessage[]>({ reducer: (x, y) => x.concat(y), default: () => [], }), plan: Annotation<string>({ reducer: (x, y) => y ?? x, default: () => '', }),})
3. 工作流构建
// graph.ts// 计划节点:生成执行计划asyncfunction planNode(state: typeof PlanState.State) {const response = await llm.invoke([ new SystemMessage(PLAN_PROMPT), state.messages[0], ])const plan = response.content asstringconsole.log('[计划内容]\n', plan)return {plan}}// 执行节点:按计划执行并调用工具asyncfunction executeNode(state: typeof PlanState.State) {const messages = [ new SystemMessage(PLAN_EXECUTE_PROMPT.replace('{plan}', state.plan)), ...state.messages, ]const response = await llmWithTools.invoke(messages)return {messages: [response]}}// 工具节点:执行工具调用asyncfunction toolNode(state: typeof PlanState.State) {const lastMessage = state.messages[state.messages.length - 1]const toolCalls = lastMessage.tool_calls || []const toolMessages = awaitPromise.all( toolCalls.map(async (tc) => { const tool = toolsByName[tc.name] const result = await tool.invoke(tc.args) returnnew ToolMessage({ content: String(result), tool_call_id: tc.id, }) }) )return {messages: toolMessages}}// 路由函数function shouldContinue(state: typeof PlanState.State): string {const content = state.messages[state.messages.length - 1].contentreturn content.includes('Final Answer') ? END : 'toolNode'}// 构建图exportfunction buildPlanGraph() {returnnew StateGraph(PlanState) .addNode('planNode', planNode) .addNode('executeNode', executeNode) .addNode('toolNode', toolNode) .addEdge('__start__', 'planNode') .addEdge('planNode', 'executeNode') .addConditionalEdges('executeNode', shouldContinue) .addEdge('toolNode', 'executeNode') .compile()}
运行效果
[启动计划模式 Agent][用户问题] 茅台和青岛啤酒哪个贵?[计划节点] 生成执行计划...[计划内容]1. 获取贵州茅台的股票收盘价2. 获取青岛啤酒的股票收盘价3. 比较两者的收盘价,确定哪个更贵[执行节点] 按计划执行...[工具节点] 执行工具... 执行: get_closing_price({"name":"贵州茅台"}) 结果: 1488.21[执行节点] 按计划执行...[工具节点] 执行工具... 执行: get_closing_price({"name":"青岛啤酒"}) 结果: 67.92[执行节点] 按计划执行...[完成][最终答案]根据收盘价比较:- 贵州茅台:1488.21 元- 青岛啤酒:67.92 元结论:贵州茅台更贵Final Answer
3.4 高级计划模式:动态调整
简单计划模式的局限是计划一旦生成就固定不变。高级计划模式引入了动态重新规划能力,可以根据执行结果调整剩余步骤,下面我们来改进一下。
工作流程
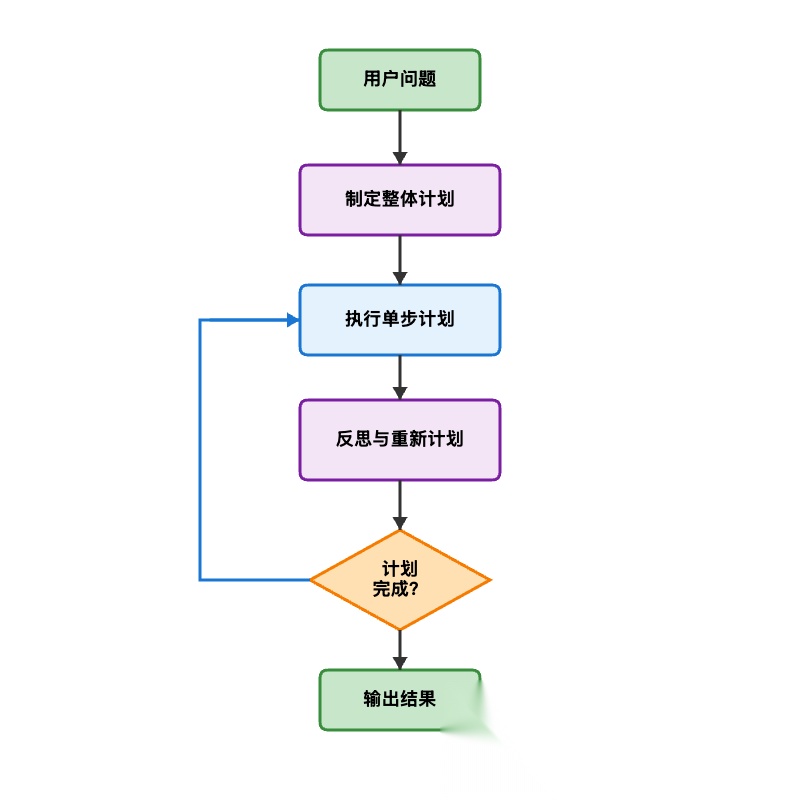
代码示例
1. Prompt 设计
// 执行助手 Prompt(用于 ReAct Agent)export const SYSTEM_PROMPT = `你是一个任务执行助手`// 计划评估 Prompt(核心:引导 LLM 动态调整计划)export const PLAN_PROMPT = `你是一个计划评估助手,负责根据已完成的步骤评估任务进度,并动态调整后续计划。你的目标:{input}原始计划:{plan}已完成的步骤及结果:{past_steps}核心规则:1. 仔细分析已完成步骤的结果2. 根据实际情况调整后续计划: - 如果发现需要补充新步骤,添加到计划中 - 如果发现某些步骤不再需要,从计划中移除 - 如果发现步骤顺序不合理,调整执行顺序输出格式(必须严格遵守):- 如果任务已完成:直接输出答案,不要使用列表格式- 如果还需继续:只输出步骤列表(每行一个,使用 "- " 开头)注意:不要在步骤列表中混入解释性文字,只输出纯粹的步骤列表`
2. 执行节点(使用 ReAct Agent)
import {createReactAgent} from'@langchain/langgraph/prebuilt'import {ChatOpenAI} from'@langchain/openai'// 创建 LLM 实例const llm = new ChatOpenAI({ modelName: 'gpt-4o', apiKey: process.env.API_KEY || '',})// 创建 ReAct Agent 作为执行器const executeAgent = createReactAgent({ llm, tools, // 工具列表:getClosingPriceTool, calculatorTool 等 messageModifier: SYSTEM_PROMPT,})// 执行节点:执行当前计划的第一步asyncfunction executeStep(state: typeof PlanExecuteState.State) {const plan = state.planif (!plan || plan.length === 0) { return {pastSteps: []} }// 格式化任务描述const planStr = plan.map((step, i) =>`${i + 1}. ${step}`).join('\n')const task = plan[0]const taskFormatted = `计划有以下几个步骤:\n${planStr}\n\n你需要执行 步骤1. ${task}.`// 使用 ReAct Agent 执行const agentResponse = await executeAgent.invoke({ messages: [['user', taskFormatted]], })// 提取执行结果const lastMessage = agentResponse.messages[agentResponse.messages.length - 1]const result = lastMessage?.content asstring// 记录到执行历史return { pastSteps: [[task, result]] asArray<[string, string]>, }}
3. 规划评估节点(核心:动态调整)
// 规划评估节点asyncfunction planStep(state: typeof PlanExecuteState.State) {// 格式化当前状态const planStr = state.plan.map((step, i) =>`${i + 1}. ${step}`).join('\n')const pastStepsStr = state.pastSteps .map(([task, result]) =>`- ${task}\n 结果: ${result}`) .join('\n')// 构建评估提示词const prompt = PLAN_PROMPT.replace('{input}', state.input) .replace('{plan}', planStr) .replace('{past_steps}', pastStepsStr || '无')// 获取 LLM 评估结果const response = await llm.invoke(prompt)const content = response.content asstring// 先尝试提取步骤列表const newPlan = extractPlanFromResponse(content)// 如果提取到步骤,说明需要继续执行if (newPlan.length > 0) { // 对比原计划,检测是否有调整 const originalRemaining = state.plan.slice(1) if (JSON.stringify(newPlan) !== JSON.stringify(originalRemaining)) { console.log('[计划调整] 检测到计划变更') console.log('[原计划]', originalRemaining) console.log('[调整后]', newPlan) } return {plan: newPlan} }// 没有步骤列表,说明任务完成return {response: content}}// 辅助函数:从 LLM 响应中提取步骤列表function extractPlanFromResponse(response: string): string[] {const lines = response.split('\n')const steps: string[] = []for (const line of lines) { const trimmed = line.trim() // 匹配 "- 步骤" 或 "1. 步骤" 格式 if (trimmed.match(/^[-*]\s+(.+)$/)) { const step = trimmed.replace(/^[-*]\s+/, '').trim() if (step) steps.push(step) } elseif (trimmed.match(/^\d+[\.)]\s+(.+)$/)) { const step = trimmed.replace(/^\d+[\.)]\s+/, '').trim() if (step) steps.push(step) } }return steps}
4. 构建 LangGraph 工作流
import {StateGraph, END} from'@langchain/langgraph'// 路由函数:决定继续还是结束function shouldEnd(state: typeof PlanExecuteState.State): string {return state.response ? END : 'execute'}// 构建工作流const workflow = new StateGraph(PlanExecuteState) .addNode('execute', executeStep) // 执行节点 .addNode('planstep', planStep) // 规划节点 .addEdge('__start__', 'execute') // 开始 → 执行 .addEdge('execute', 'planstep') // 执行 → 规划 .addConditionalEdges('planstep', shouldEnd, { execute: 'execute', // 继续执行 [END]: END, // 结束 })const app = workflow.compile()
运行示例(体现动态调整)
故意给一个不完整的初始计划,让 Agent 根据中间结果动态补充步骤。
[启动高级计划模式 Agent][目标] 仅根据收盘价帮我分析一下青岛啤酒和贵州茅台的投资价值对比,低的更有价值[初始计划] 1. 获取青岛啤酒的股票收盘价[执行节点] 执行当前步骤...[任务]计划有以下几个步骤:1. 获取青岛啤酒的股票收盘价你需要执行 步骤1. 获取青岛啤酒的股票收盘价.[执行结果] 青岛啤酒的股票收盘价是67.92元。[规划节点] 评估并调整计划...[LLM 评估]- 获取贵州茅台的股票收盘价- 比较青岛啤酒和贵州茅台的股票收盘价- 分析投资价值并确定哪一个更有价值[计划调整] 检测到计划变更[原计划剩余步骤][调整后的计划] 1. 获取贵州茅台的股票收盘价 2. 比较青岛啤酒和贵州茅台的股票收盘价 3. 分析投资价值并确定哪一个更有价值[执行节点] 执行当前步骤...[任务]计划有以下几个步骤:1. 获取贵州茅台的股票收盘价2. 比较青岛啤酒和贵州茅台的股票收盘价3. 分析投资价值并确定哪一个更有价值你需要执行 步骤1. 获取贵州茅台的股票收盘价.[执行结果] 贵州茅台的股票收盘价是1488.21。接下来需要进行比较和分析投资价值的步骤。[规划节点] 评估并调整计划...[LLM 评估]青岛啤酒的投资价值更高。[决策] 无后续步骤,任务完成[完成][最终答案] 青岛啤酒的投资价值更高。
3.5 适用场景
计划模式最适合需求明确、步骤可预测的结构化任务。当任务目标清晰、可分解为多个具体步骤时,先制定计划再执行能够提供更好的可控性和可预测性。这种模式特别适合数据分析、报告生成、多步骤查询等场景。对于需要监控执行进度或预估完成时间的任务,计划模式的优势更加明显。同时,当需要优化执行顺序或并行处理某些步骤时,有了明确的计划更容易进行调度优化。
3.6 注意事项
使用计划模式需要权衡灵活性和可控性。如果任务的不确定性较高,初始计划可能不够准确,需要考虑引入动态调整机制(如高级计划模式)。计划生成的质量直接影响最终效果,需要精心设计计划生成的 Prompt,提供清晰的指导和示例。执行过程中可能遇到计划中未预见的情况,需要有合适的异常处理策略。此外,过于详细的计划可能限制 Agent 的灵活性,而过于粗略的计划又可能起不到指导作用,需要根据具体任务找到平衡点。
四、反思模式(Reflection Mode)
4.1 核心理念
反思模式模拟人类"先写初稿,再反复修改"的创作过程,通过自我评估和迭代改进来提升输出质量。这种模式特别适合对输出质量要求较高的场景,通过引入一个独立的反思环节来审视当前方案的不足之处。
4.2 工作流程
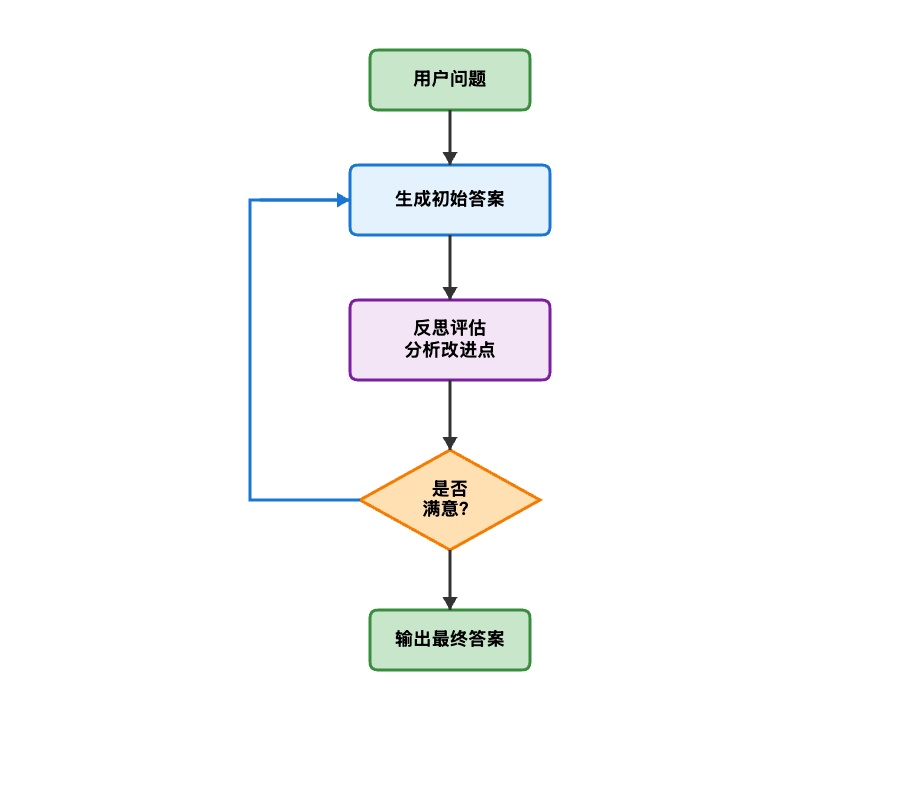
反思模式包含三个阶段的循环:生成阶段根据需求和反思建议生成方案,反思阶段多维度检查方案并提出改进建议,决策阶段判断是否继续优化。循环持续进行直到达到质量标准或迭代次数上限。
4.3 核心代码
反思模式的实现包含状态定义、Prompt 设计、生成节点、反思节点和决策函数几个关键部分。
状态定义:
export const ReflectionState = Annotation.Root({ userQuery: Annotation<string>(), // 用户需求 bestCommand: Annotation<string>(), // 当前最优方案 reflection: Annotation<string>(), // 反思记录 iterations: Annotation<number>(), // 迭代次数})
Prompt 设计:
反思模式的核心在于两个高质量的 Prompt。生成 Prompt 用于根据需求和反思建议生成或改进方案:
export const COMMAND_PROMPT = `你是一个资深Linux运维专家,请根据用户需求生成最合适的Linux命令。要求:1. 只输出可直接执行的命令2. 优先使用性能最好的方案用户需求:{user_query}当前方案:{best_command}改进建议:{reflection}请按以下格式输出:命令:<生成的命令>`
反思 Prompt 用于检查方案的合理性并提出改进建议:
export const REFLECTION_PROMPT = `请严格检查以下Linux命令的合理性:{command}检查维度:1. 是否符合POSIX标准2. 是否有更高效的替代方案3. 是否完全解决用户需求4. 是否好维护用户原始需求:{user_query}请返回结构化的检查结果:- needsImprovement: 是否需要改进(true/false)- suggestions: 改进建议(包含发现的问题和具体优化方向,如果无需改进则说明"已达最优")`
结构化输出格式:
import {z} from 'zod'// 反思结果的结构化输出const ReflectionResultSchema = z.object({ needsImprovement: z.boolean().describe('是否需要改进'), suggestions: z.string().describe('改进建议,包含发现的问题和优化方向'),})
生成节点:
async function generateCommand(state: ReflectionStateType) {const iter = state.iterationsconsole.log(`[生成] 第 ${iter + 1} 次命令生成`)let prompt: stringif (iter === 0) { // 第一次生成 prompt = COMMAND_PROMPT.replace('{user_query}', state.userQuery) .replace('{best_command}', '无') .replace('{reflection}', '无') } else { // 根据反思结果改进 prompt = COMMAND_PROMPT.replace('{user_query}', state.userQuery) .replace('{best_command}', state.bestCommand) .replace('{reflection}', state.reflection) }const response = await llm.invoke(prompt)const content = response.content asstring// 提取命令(处理"命令:"前缀)const commandParts = content.split('命令:')const command = commandParts.length > 1 ? commandParts[1]?.trim() || content.trim() : content.trim()console.log(`[命令] ${command}`)return { bestCommand: command, iterations: iter + 1, }}
反思节点:
async function reflectAndOptimize(state: ReflectionStateType) {console.log('[反思] 执行检查...')const prompt = REFLECTION_PROMPT.replace( '{command}', state.bestCommand ).replace('{user_query}', state.userQuery)try { // 使用结构化输出 const structuredLlm = llm.withStructuredOutput(ReflectionResultSchema) const result = await structuredLlm.invoke(prompt) // 检查是否需要改进 if (!result.needsImprovement) { console.log('[评估] 已经最优,无需改进') return {reflection: '已经最优,无需优化'} } console.log(`[建议] ${result.suggestions}`) return {reflection: result.suggestions} } catch (error) { console.error('[反思失败]', error) return {reflection: '反思检查失败'} }}
决策函数:
// 停止标志:发现这些关键词时立即停止const STOP_SIGNS = ['安全隐患', '木马', '攻击']function checkReflection(state: ReflectionStateType): string {// 1. 检查是否已最优if ( state.reflection.includes('无建议') || state.reflection.includes('无需优化') ) { console.log('\n[结束] 已达到最优方案') return END }// 2. 检查停止标志(安全问题等)for (const stopSign of STOP_SIGNS) { if (state.reflection.includes(stopSign)) { console.log(`\n[结束] 检测到停止标志: ${stopSign}`) return END } }// 3. 检查迭代次数上限if (state.iterations >= 3) { console.log('\n[结束] 达到最大迭代次数 (3次)') return END }// 4. 继续优化console.log('[决策] 继续优化...')return'generate'}
构建工作流:
const workflow = new StateGraph(ReflectionState) .addNode('generate', generateCommand) .addNode('reflect', reflectAndOptimize) .addEdge('__start__', 'generate') .addEdge('generate', 'reflect') .addConditionalEdges('reflect', checkReflection, { generate: 'generate', [END]: END, })const app = workflow.compile()
4.4 运行示例
场景:生成 Docker 命令
[启动反思模式 Agent][需求] 使用docker创建nginx容器,端口映射8080:80[生成] 第 1 次命令生成[命令] docker run -d -p 8080:80 nginx[反思] 执行检查...[建议] ### 检查结果:1. **是否符合POSIX标准** - Docker命令本身不在POSIX标准的范围内。POSIX主要用于异类系统的兼容性与命令行工具,而Docker作为一个应用层次的技术,自成一套工具集。因此,此项不适用。2. **是否有更高效的替代方案** - **问题**:缺少对容器生命周期管理的基础设置。 - **建议**: - 使用容器名:便于管理和识别。 ```bash docker run -d --name my_nginx -p 8080:80 nginx ```3. **是否完全解决用户需求** - **问题**:基本需求虽然实现,但缺少扩展性设置。 - **建议**: - 定义具体的版本和配置映射:确保相同环境的一致性。 ```bash docker run -d --name my_nginx -p 8080:80 -v /my/local/nginx.conf:/etc/nginx/nginx.conf nginx:1.21.6 ```- 添加自动重启设置,提高容器的可用性。 ```bash docker run -d --name my_nginx --restart unless-stopped -p 8080:80 nginx ```4. **是否好维护** - **问题**:需要通过容器ID执行维护命令,不利于日常操作。 - **建议**: - 使用可识别的容器名称:简化运维。 ```bash docker run -d --name my_nginx -p 8080:80 nginx ```- 考虑使用 Docker Compose 管理复杂项目,提升可维护性。### 综合结论:- **需要改进**:True- **改进建议**:通过增加容器名称、版本控制和配置映射等方式提高管理效率,增强容器运行的稳定性和可扩展性。同时,建议考虑使用 Docker Compose 简化多容器环境的管理。[决策] 继续优化...[生成] 第 2 次命令生成[命令] docker run -d --name my_nginx -p 8080:80 -v /my/local/nginx.conf:/etc/nginx/nginx.conf nginx:1.21.6[反思] 执行检查...[评估] 已经最优,无需改进[结束] 已达到最优方案[完成]最终命令: docker run -d --name my_nginx -p 8080:80 -v /my/local/nginx.conf:/etc/nginx/nginx.conf nginx:1.21.6
4.5 适用场景
反思模式最适合对输出质量有较高要求的场景。当需要生成文档、代码、配置文件、命令等关键输出时,通过反思机制可以显著提升方案的完整性和可靠性。这种模式特别适合技术方案设计、代码审查、内容创作等需要经过多次打磨才能达到专业标准的任务。同时,对于那些有明确质量评估标准的任务,反思模式能够系统性地检查各个维度是否达标。
4.6 注意事项
使用反思模式时需要注意控制迭代次数,避免过度优化导致效率低下或陷入无限循环。建议设置合理的迭代上限(通常 2-3 次即可),并定义清晰的停止条件。反思 Prompt 的设计至关重要,需要明确具体的检查维度和评估标准,避免模糊的评价导致反思效果不佳。此外,反思模式会增加 LLM 调用次数和 Token 消耗,需要在质量和成本之间做好平衡。对于某些已经足够好的初始方案,过度的反思可能反而引入不必要的修改。
五、人机协作模式(Human-in-the-Loop)
5.1 核心理念
人机协作模式将 Agent 的自动化能力与人类判断力相结合。适用于关键决策(高风险操作需人工确认)、信息补全(缺少参数时询问用户)和质量控制(重要输出需人工审核)等场景。通过在关键节点暂停执行、等待人工输入、然后恢复执行,实现效率与可控性的平衡。
5.2 工作流程
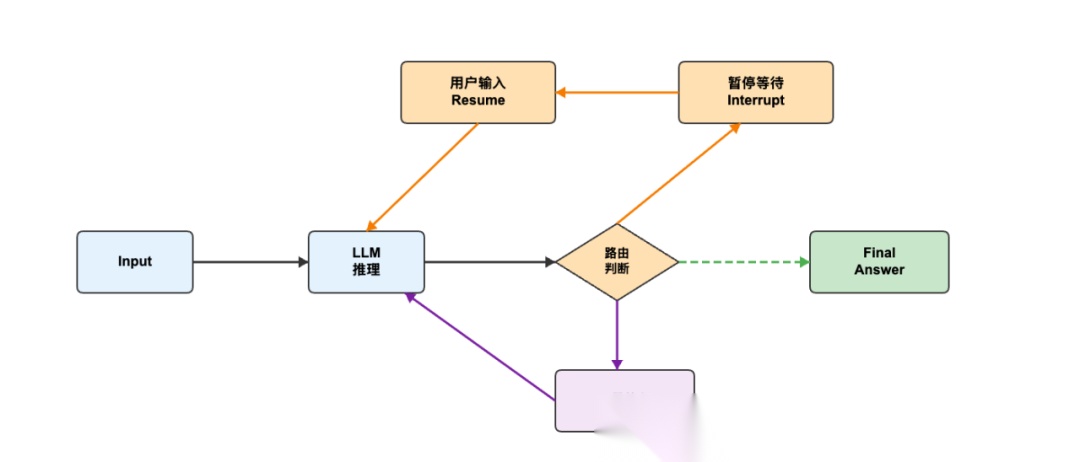
流程图展示了一个核心循环和三条分支路径:
核心循环:
Input → LLM 推理 → 路由判断
分支 1:人工交互路径(橙色)
路由判断 → 暂停等待 → 用户输入 → LLM 推理(循环)
- 触发条件:LLM 调用
ask_user工具 - 核心机制:
interrupt()暂停,等待用户输入,resume恢复 - 应用场景:缺少参数、需要用户确认、多选项决策
分支 2:工具执行路径(紫色)
路由判断 → 工具执行 → LLM 推理(循环)
- 触发条件:LLM 调用普通工具
- 核心机制:自动执行工具,结果反馈给 LLM
- 应用场景:查询数据、计算处理、API 调用
分支 3:完成路径(绿色虚线)
路由判断 → Final Answer(结束)
- 触发条件:LLM 判断已获得足够信息
- 核心机制:返回最终结果,结束执行
- 应用场景:问题解决、任务完成
实现依赖三个核心机制:中断机制通过 interrupt() 暂停执行并等待人工输入,状态保存机制使用 Checkpointer 保留所有上下文信息,恢复执行机制通过 Command({ resume: userInput }) 从暂停点继续执行。
5.3 实战案例:购物助手
场景: 用户询问购买商品的总价,但没有说明数量,需要询问用户。
核心代码实现
1. 工具定义
import {tool} from'@langchain/core/tools'import {z} from'zod'// 普通工具:获取商品价格exportconst getPriceTool = tool(async (input) => { const {product} = input as {product: string} const price = (Math.random() * 90 + 10).toFixed(2) return`商品${product}的价格为${price}元` }, { name: 'get_price', description: '获取商品价格', schema: z.object({ product: z.string().describe('商品名称'), }), })// 特殊工具:询问用户(触发人工介入)exportconst askUserTool = tool(async (input) => { const {question} = input as {question: string} console.log('[需要询问用户]', question) return question }, { name: 'ask_user', description: '询问用户进一步的需求,如用户要多少件商品、要什么商品等', schema: z.object({ question: z.string().describe('需要询问用户的问题'), }), })
关键点:
ask_user是一个特殊工具,用于触发人工介入- LLM 会在需要用户信息时自动调用这个工具
2. 人工节点(核心)
import {interrupt, Command} from'@langchain/langgraph'import {ToolMessage} from'@langchain/core/messages'asyncfunction humanNode(state: HumanLoopStateType) {const lastMessage = state.messages[state.messages.length - 1]const toolCall = lastMessage.tool_calls?.[0]// 使用 interrupt 暂停执行,等待用户输入const userInput = interrupt(toolCall.args)console.log('[用户输入]', userInput)// 将用户输入作为工具执行结果返回const toolMessage = new ToolMessage({ tool_call_id: toolCall.id, content: String(userInput), })return {messages: [toolMessage]}}
关键点:
interrupt()会暂停整个工作流的执行- 返回的值会在恢复执行时作为
resume参数传入 - 用户输入被封装成
ToolMessage返回给 LLM
3. 路由函数(识别触发时机)
function enterTools(state: HumanLoopStateType): string {const lastMessage = state.messages[state.messages.length - 1]const toolCalls = lastMessage.tool_callsif (!toolCalls || toolCalls.length === 0) { return END }const toolName = toolCalls[0].name// 如果是 ask_user,进入人工节点if (toolName === 'ask_user') { return'humanNode' }// 否则进入工具节点return'toolNode'}
4. 构建 LangGraph(必须使用 Checkpointer)
import {StateGraph, START, END} from'@langchain/langgraph'import {MemorySaver} from'@langchain/langgraph'function buildHumanLoopGraph() {const workflow = new StateGraph(HumanLoopState) .addNode('llmNode', llmNode) .addNode('humanNode', humanNode) .addNode('toolNode', toolNode) .addEdge(START, 'llmNode') .addConditionalEdges('llmNode', enterTools, { humanNode: 'humanNode', toolNode: 'toolNode', [END]: END, }) .addEdge('toolNode', 'llmNode') .addEdge('humanNode', 'llmNode')// 必须使用 checkpointer 来保存状态const memory = new MemorySaver()return workflow.compile({checkpointer: memory})}
关键点:
- 人机协作模式必须配置
checkpointer MemorySaver将状态保存在内存中(生产环境可用数据库)
5. 运行 Agent(两阶段执行)
export asyncfunction runHumanLoopAgent( query: string, getUserInput: () => Promise<string>): Promise<string> {const app = buildHumanLoopGraph()const threadConfig = {configurable: {thread_id: '123'}}// 第一次启动let result = await app.invoke({query, messages: []}, threadConfig)// 检查是否需要人工输入const lastMessage = result.messages[result.messages.length - 1]if (lastMessage.tool_calls?.[0]?.name === 'ask_user') { console.log('\n[等待用户输入...]') const userInput = await getUserInput() // 恢复执行(关键:使用 Command + resume) result = await app.invoke(new Command({resume: userInput}), threadConfig) }return result.messages[result.messages.length - 1].content}
关键点:
- 第一次
invoke会执行到interrupt处暂停 - 获取用户输入后,通过
Command({ resume: userInput })恢复 - 必须使用相同的
threadConfig才能恢复到正确的状态
运行效果
[启动人机协作模式 Agent][用户问题] 我想买一些苹果,总共需要多少钱[LLM 分析] 需要知道用户要买多少苹果[进入工具] ask_user[参数] {question: '您想购买多少个苹果?'}[需要询问用户] 您想购买多少个苹果?[等待用户输入...]请输入: 5个[用户输入] 5个[用户回答] 5个[调用工具] get_price {product: '苹果'}→ 商品苹果的价格为52.30元[LLM 计算] 5个 × 52.30元 = 261.50元[完成][最终答案] 您想购买5个苹果,总共需要261.50元
5.4 适用场景
人机协作模式在多种场景下都能发挥重要作用。对于敏感操作,比如删除数据、修改配置、执行系统命令等高风险动作,在执行前需要用户明确确认。可以通过定义 confirm_operation 工具,在执行前暂停并向用户展示即将执行的操作内容,等待用户审核通过后再继续。
在信息补全场景中,当 Agent 发现缺少必需参数、需要用户在多个选项中选择、或参数含义不明确时,可以暂停执行并向用户询问。这种交互式的信息收集方式比让 Agent 自行猜测要可靠得多。
质量控制是另一个重要应用场景。当 Agent 生成文档、代码、方案等内容后,可以暂停执行让用户审核输出质量。在关键决策点,人工判断往往比 LLM 的判断更可靠。此外,对于重要结果,在使用前进行人工验证可以避免潜在风险。
异常处理场景也很常见。当 Agent 遇到无法自动处理的情况时,与其直接失败不如暂停并请求人工帮助。用户可以提供额外信息、调整策略或从多个备选方案中选择,然后 Agent 继续执行。
5.5 高级用法
1. 支持多轮人工介入
async function runWithMultipleInterrupts(query: string) {const app = buildHumanLoopGraph()const config = {configurable: {thread_id: '123'}}let input: any = {query, messages: []}while (true) { const result = await app.invoke(input, config) // 检查是否完成 if (!needsHumanInput(result)) { return result.messages[result.messages.length - 1].content } // 获取用户输入 const userInput = await getUserInput() // 准备下一次调用 input = new Command({resume: userInput}) }}
2. 支持用户取消
const userInput = await getUserInput()if (userInput === 'cancel' || userInput === '取消') { return '操作已取消'}result = await app.invoke(new Command({resume: userInput}), config)
3. 添加超时处理
const timeout = (ms: number) =>newPromise((_, reject) => setTimeout(() => reject(newError('Timeout')), ms))try {const userInput = awaitPromise.race([ getUserInput(), timeout(60000), // 60秒超时 ]) result = await app.invoke(new Command({resume: userInput}), config)} catch (error) {return'等待超时,操作已取消'}
5.6 注意事项
实现人机协作模式时需要注意几个关键点。首先,必须配置 Checkpointer 来保存状态,这是整个模式的技术基础。可以选择 MemorySaver 用于开发和简单场景,或使用 SqliteSaver 等持久化方案用于生产环境。
Thread ID 的一致性至关重要。恢复执行时必须使用与暂停时相同的 thread_id,否则会导致状态丢失。在多用户场景下,务必为每个用户会话分配独立的 thread_id 以隔离状态,避免数据混淆。
输入验证不可忽视。用户可能输入无效内容、格式错误或超出预期范围的数据,需要实现完善的验证和错误处理机制。同时,应该设置合理的超时机制,避免 Agent 无限期等待用户输入。提供取消操作的选项也很重要,让用户可以随时中止流程。
六、总结
五种 Agent 设计模式各有侧重。ReAct 通过推理-行动循环适合处理需要外部工具的任务,CodeAct 通过代码生成解决复杂计算问题。计划模式提供结构化执行路径,简单版适合明确任务,高级版支持动态调整。反思模式通过迭代优化提升输出质量,人机协作模式在关键节点引入人工判断确保可控性。
实际应用中往往需要组合使用。建议从简单模式开始验证核心逻辑,逐步引入高级特性。根据任务特点权衡性能与准确性,同时做好日志监控和安全防护。通过理解这些模式的特点和适用场景,你可以构建高效可靠的 Agent 系统。
大模型未来如何发展?普通人如何抓住AI大模型的风口?
※领取方式在文末
为什么要学习大模型?——时代浪潮已至
随着AI技术飞速发展,大模型的应用已从理论走向大规模落地,渗透到社会经济的方方面面。
- 技术能力上:其强大的数据处理与模式识别能力,正在重塑自然语言处理、计算机视觉等领域。
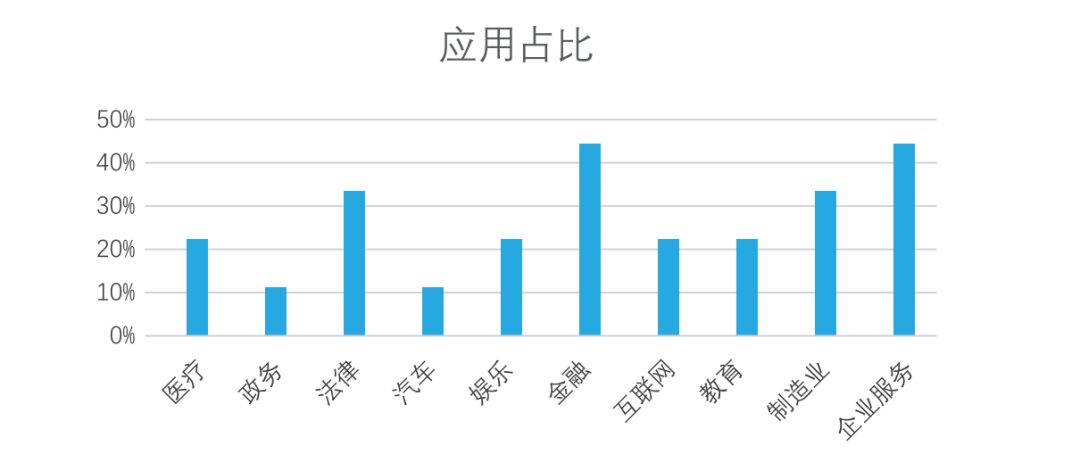
- 行业应用上:开源人工智能大模型已走出实验室,广泛落地于医疗、金融、制造等众多行业。尤其在金融、企业服务、制造和法律领域,应用占比已超过30%,正在创造实实在在的价值。
未来大模型行业竞争格局以及市场规模分析预测:
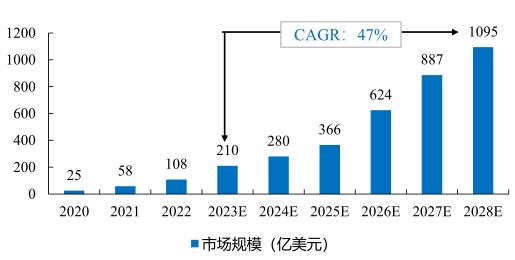
同时,AI大模型技术的爆发,直接催生了产业链上一批高薪新职业,相关岗位需求井喷:

AI浪潮已至,对技术人而言,学习大模型不再是选择,而是避免被淘汰的必然。这关乎你的未来,刻不容缓!
那么,我们如何学习AI大模型呢?
在一线互联网企业工作十余年里,我指导过不少同行后辈,经常会收到一些问题,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题,也不是三言两语啊就能讲明白的。
所以呢,这份精心整理的AI大模型学习资料,我整理好了,免费分享!只希望它能用在正道上,帮助真正想提升自己的朋友。让我们一起用技术做点酷事!
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!

适学人群
我们的课程体系专为以下三类人群精心设计:
-
AI领域起航的应届毕业生:提供系统化的学习路径与丰富的实战项目,助你从零开始,牢牢掌握大模型核心技术,为职业生涯奠定坚实基础。
-
跨界转型的零基础人群:聚焦于AI应用场景,通过低代码工具让你轻松实现“AI+行业”的融合创新,无需深奥的编程基础也能拥抱AI时代。
-
寻求突破瓶颈的传统开发者(如Java/前端等):将带你深入Transformer架构与LangChain框架,助你成功转型为备受市场青睐的AI全栈工程师,实现职业价值的跃升。

※大模型全套学习资料展示
通过与MoPaaS魔泊云的强强联合,我们的课程实现了质的飞跃。我们持续优化课程架构,并新增了多项贴合产业需求的前沿技术实践,确保你能获得更系统、更实战、更落地的大模型工程化能力,从容应对真实业务挑战。
 资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
01 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。希望这份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
👇微信扫描下方二维码即可~

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
02 大模型学习书籍&文档
新手必备的权威大模型学习PDF书单来了!全是一系列由领域内的顶尖专家撰写的大模型技术的书籍和学习文档(电子版),从基础理论到实战应用,硬核到不行!
※(真免费,真有用,错过这次拍大腿!)

03 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
04 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
05 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

06 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
由于篇幅有限
只展示部分资料
并且还在持续更新中…
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!
最后,祝大家学习顺利,抓住机遇,共创美好未来!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









