



当前大模型技术生态中,智能体(Agent)无疑是最受关注的主流应用方向,其自主决策、多工具协同的能力正在重塑复杂任务的解决范式。但必须明确的是,RAG 并非边缘技术,反而在 Agent 体系中扮演着 “信息基座” 的核心角色 ——Agent 的决策需要实时、准确的外部信息支撑,而 RAG 正是连接大模型与专业知识库的关键桥梁。正因如此,RAG 在企业级应用场景中应用广泛,从客服领域的知识库问答,到金融行业的政策文档解读,再到制造业的设备手册查询,都能看到其身影。
不过,RAG 的 “易用性” 与 “高质量” 之间存在显著鸿沟。搭建一个基础的 RAG 流程并不复杂:将文档转成向量、存入数据库、检索后喂给大模型,几步操作即可实现初步功能;但要让 RAG 系统在实际业务中稳定输出高准确率、高相关性的结果,却需要攻克多个技术难点。结合实际项目经验,我们可从 RAG 的三大核心阶段 —— 文档处理、数据召回、增强生成 —— 入手,拆解各环节的典型问题与针对性优化方案。
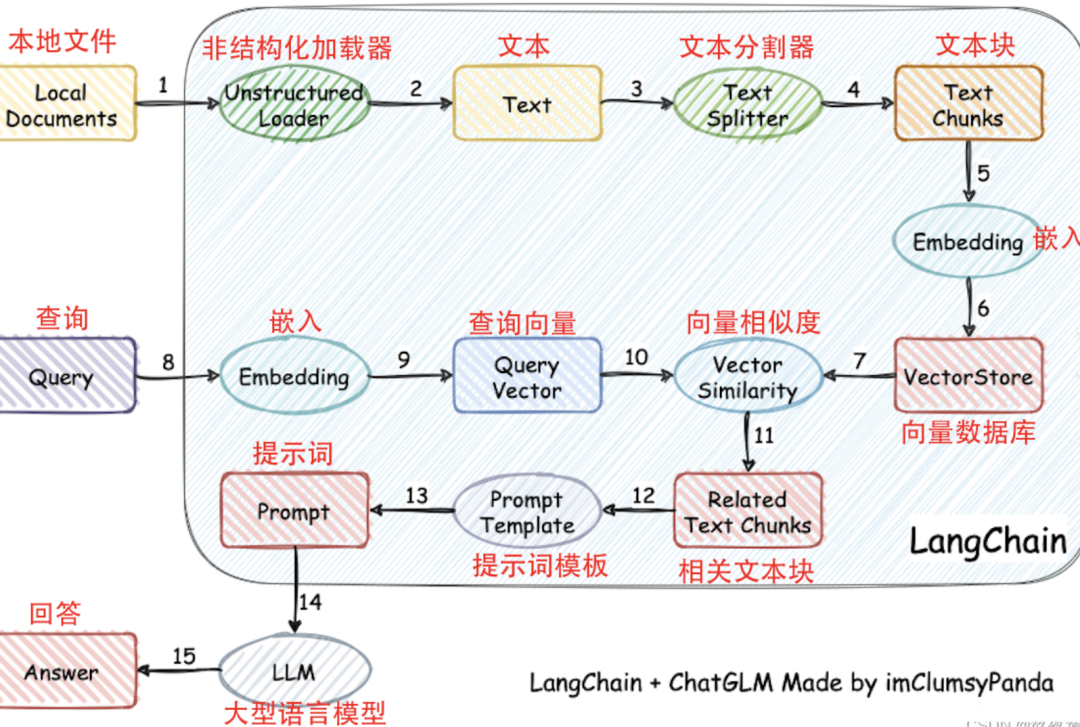
一、RAG中场景的问题和解决方案
1、 文档处理
所谓的文档处理本质上就是把外部文档处理成向量格式然后通过相似度计算的方式进行语义召回。
当然,RAG并没有限制必须把文档处理成向量格式,也没限制必须要进行相似度召回;RAG的目的是快速准确的找到和问题相关的内容,因此使用任何召回方式都可以,包括传统的字符匹配和现在的语义查询。只不过对于非格式化数据,以及基于自然语言对话的展示场景,使用相似度语义检索更符合业务场景。
文档处理之所以是一个难点,就在于其复杂的文档格式;如txt,word,pdf,markdown,excel,csv等等很多种格式,并且这些格式的数据没有一个统一的规范,虽然excel和csv是格式化数据,但在不同的业务场景中可能需要不同的处理,比如有些场景中只需要按列处理即可,而有些场景中可能需要解析表结构,然后拼接成markdown或合并部分列数据。

因此,文档处理中文档的类型,复杂的内容格式,对格式化的不同要求,以及文档的管理都是难点;毕竟如果文档处理的不好,会直接影响到第二步数据的召回质量。
所以,文档处理的难点其中之一,就是怎么根据不同的业务场景去规范文档的处理流程及格式;其次,就是类似于word,pdf这种复杂的文档类型,由于其没有固定的格式,以及其同时支持多种不同模态的数据(文字,图片,表格,架构图等等);导致其处理起来特别麻烦,很容易丢失内容原本的意义;如架构图和设计图等,很难在向量化之后还保持其原本的意义。
当然,虽然现在使用多模态模型能够从一定程度上解决这个问题,但从成本和复杂度来说,好像又不是很值得。但基于orc等技术处理的复杂文档会丢失大量的有用信息。
2、向量数据的保存
其次是向量化数据的保存,之前的数据大多使用关系型数据库进行保存,并且其表结构和数据可以随时调整和修改;但向量化数据库由于其特殊性,导致其并不能像传统数据库那样随便进行编辑和修改;因此,刚开始设计的向量数据库随着业务的发展很难适应新的业务变化,但其调整起来又特别复杂,特别是随着业务数据的增多,导致其维护其它特别麻烦。
3、数据召回
数据召回的目的是根据用户问题,从大量的知识库中找到与用户相似度最高的文档内容,然后交由模型进行增强生成;但是面对语义召回这种本身就不确定的召回方式会出现两种情况,一种是无法召回有效数据,另一种是召回大量不相关数据;而不论哪一种都会对下一步的增强检索造成严重的影响,毕竟模型无法判断你提供的文档质量。
因此,面对这种情况需要从多个维度来提升召回质量,一是在召回侧,通过完善用户问题,提出子问题,假设性文档召回(hyDE),标量召回等。其次,就是在文档处理端,对文档进行提炼总结,增加多个维度的相似度计算。
4、增强生成
虽然说增强生成比较简单,但其实也挺重要的;在上一步的数据召回时,有时为了提高数据的召回质量会添加很多无关字段,因此在正式把召回数据提交给模型之前,我们需要对文档数据进行清洗和格式化处理;比如删除一些无关字段,把文档转换成模型更好处理的格式等等。而不是直接把召回内容一股脑的全部丢给模型。
当然,以上只是传统的RAG处理流程,目前随着智能体技术的发展,智能体技术也逐渐被应用到RAG中;原理就是借助智能体的强大的工具使用能力,以及自主决策能力,让RAG系统能够动态获取外部数据的能力,而不是只是人工处理好的死数据,比如说使用浏览器进行网络搜索。
2、那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

3、为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


4、👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









