



在正式文章前,你也许会有疑问,为什么官方已经有了,还需要自己部署干嘛,直接用不好吗?原因有几点:一是有些公司或者个人可能会咨询一些涉及商业机密的东西,部署在本地;二是可以自定义开发内容,例如我想开发一个机器人,我就可以通过部署到服务器,自己训练调用接口了(官方当然也是有api的,但是需要一定的费用,而且爹有娘有不如自己有;三是自己部署的话,自定义私有程度比较高……)
部署方式一:
通过ollama来部署
官网: https://ollama.com/
(鉴于很多朋友无法下载ollama和anythingllm,这里给大家整理好了安装包,扫描领取即可↓↓↓↓)

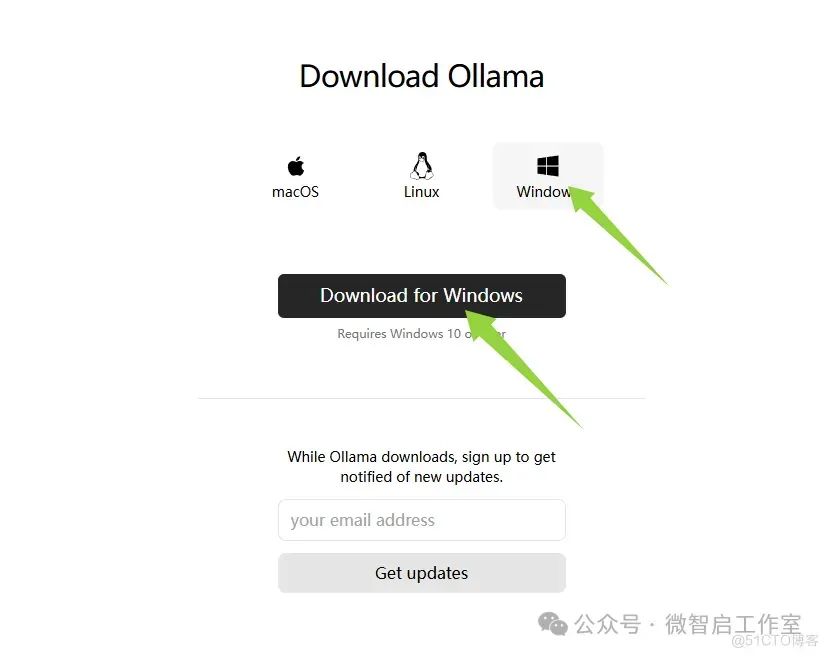
下载好ollama安装包,双击安装包开始安装;
然后点击install就可以自动安装了
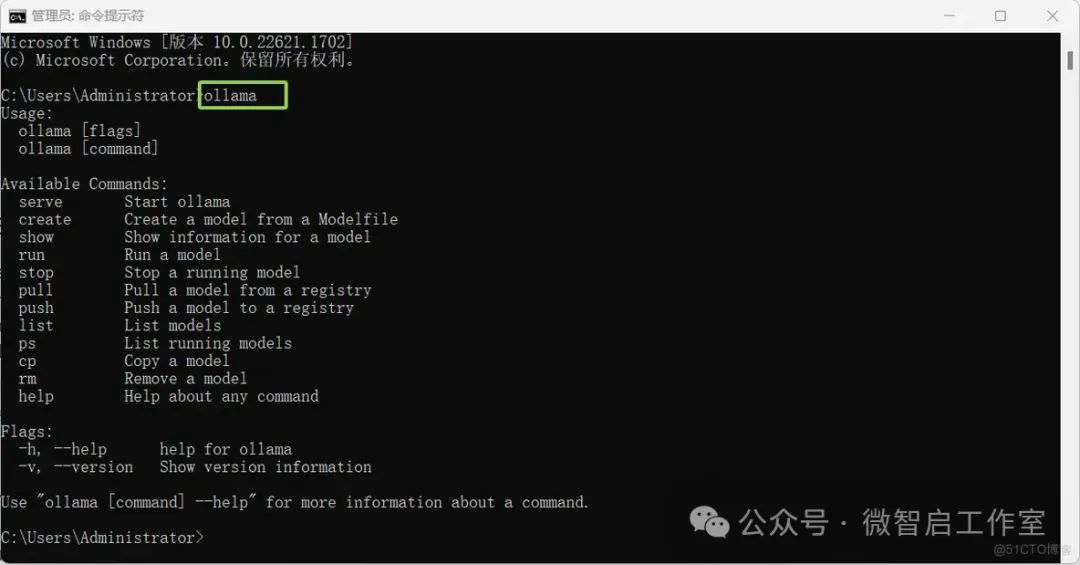
验证ollama是否安装成功:
在电脑打开cmd,输入:ollama
会出现下方一堆的文字输出,就说明已经安装好了。如果是其他的,则没有安装成功(例如ollama不是内部或外部命令,也不是可运行的程序)
继续在ollama官方,搜索关键词: deepseek-r1
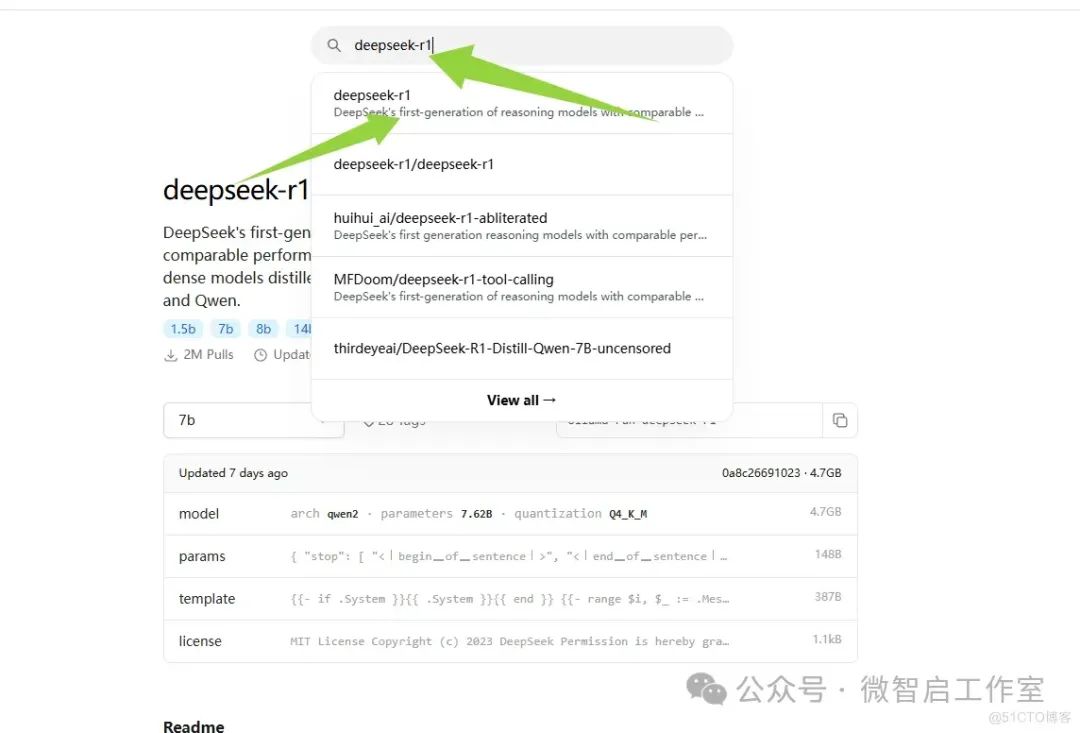
①是模型的名称 | 微智启软件工作室原创。
②写有部署模型需要的空间,一般容量越大,训练的效果越好,但是所需的电脑显存也就越大,学习推荐大家下载1.5b的尝鲜即可。
③选择好对应的模型后,会给出对应的运行指令,把指令复制到cmd窗口运行
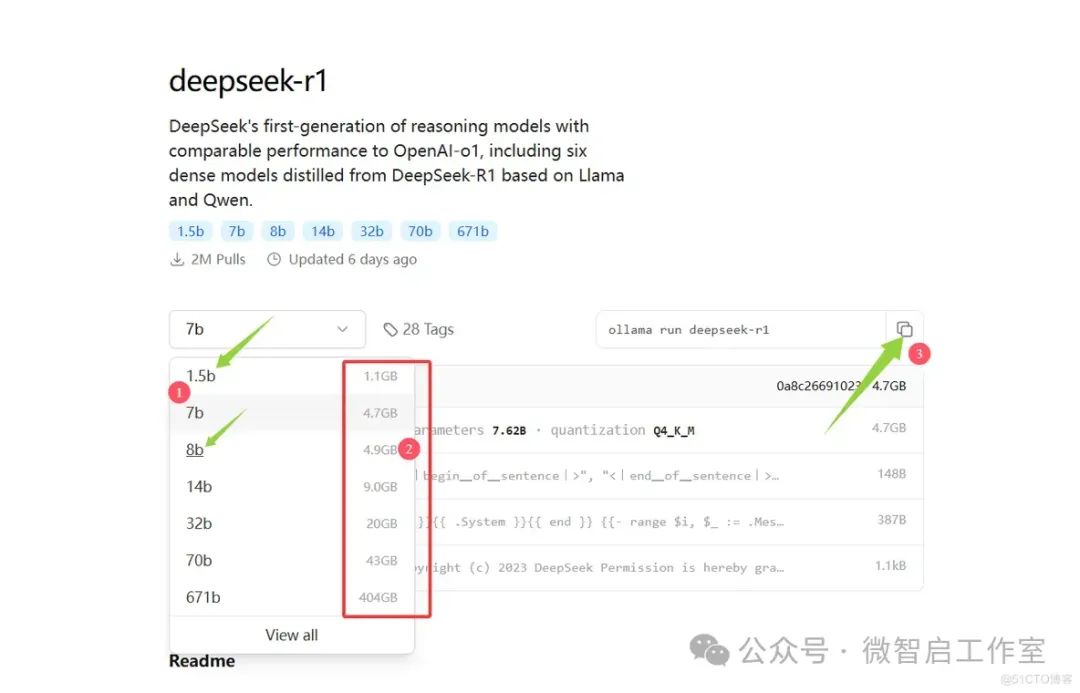
运行好指令后,初次会下载对应的模型,例如我的是:ollama run deepseek-r1:1.5b
下载完毕,会出现success字样。并且可以在>>>处直接输入你的问题,并回车执行,它就会回复了。

如上图,就成功部署啦……
更多内容,年后再更新啦,持续更新中……
删除指定的模型:
1、查看已经部署的模型:

2、删除指定的模型:ollama rm deepseek-r1:14b
注意上方红色字体需要替换成你自己实际的模型名称
部署方式二:
通过Page Assist浏览器插件来部署(这个过几天再更新了,过年不加班啦……更多后续更新内容,可以先点个关注哈)
常见报错解决方案:
Error: llama runner process has terminated: error loading model: unable to allocate CUDA_Host buffer
解决方案:这个是因为电脑的显存不够,换个小一点的模型;或者部署的时候,指定用CPU来运行,不过速度会比较慢:ollama run deepseek-r1:7b --cpu
(鉴于很多朋友无法下载ollama和anythingllm,这里给大家整理好了安装包,扫描领取即可↓↓↓↓)

















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









