



什么是 Stable Video
Sora 虽然是造势很大,但是个人猜测想要公开使用大概率是卡在了算力方面,所以迟迟没有动静,网上申请了红客应用的人们也没有收到邀请内测,奥特曼也在靠几个 demo 想拉 7 万亿美元的投资实属有点异想天开了,种种不正常的表现引人遐想。
而就在这个是时候 Stability.ai 最新发布了 stable video 的官网,它是一个 AI 视频生成平台,用户可以通过文本或图像,将自己的想象转化为精美的视频片段。
这个工具作为一款正式公布的免费文生视频或者图生视频的工具,效果也是相当惊艳。
基本原理
Stable Video 使用的是 Stable Video Diffusion 1.1 模型,在原本用于 2D 图像生成的潜在扩散模型的基础上,加入时间层,并且使用小型、高品质的影片资料集加以训练,试图将其改造成影片生成模型。 Stability AI 最新研究进一步定义出训练影片的三个阶段:
- STEP1-图像预训练: 2D text-to-image 预训练模型,也就是改变了大模型底模的参数。
- STEP2-视频预训练: 基于大规模视频训练集,进行视频训练,由于没有现成的视频质量审核模型来过滤所需要训练视频,所以这边引入了人工过滤规则。
- STEP3-高质量视频微调: 进一步提升模型生成的视频分辨率和质量,在整体训练步骤中还是借鉴了图像 diffusion model 的训练模式。
使用方式
使用方法有两种:
-
文生视频:通过输入一段预先构思好的Prompt文本即可生成想要的视频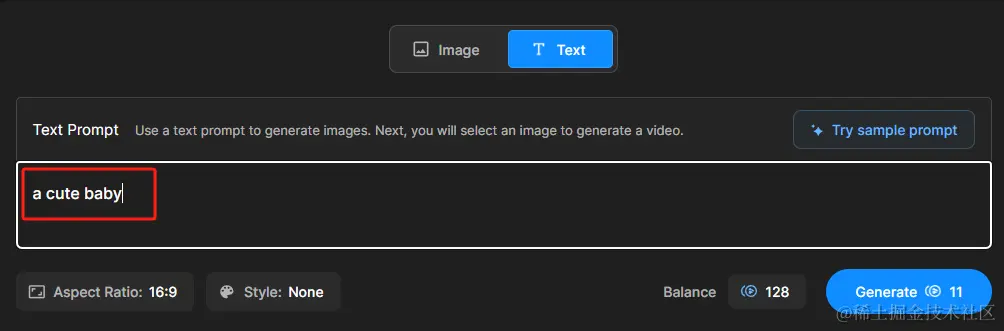
-
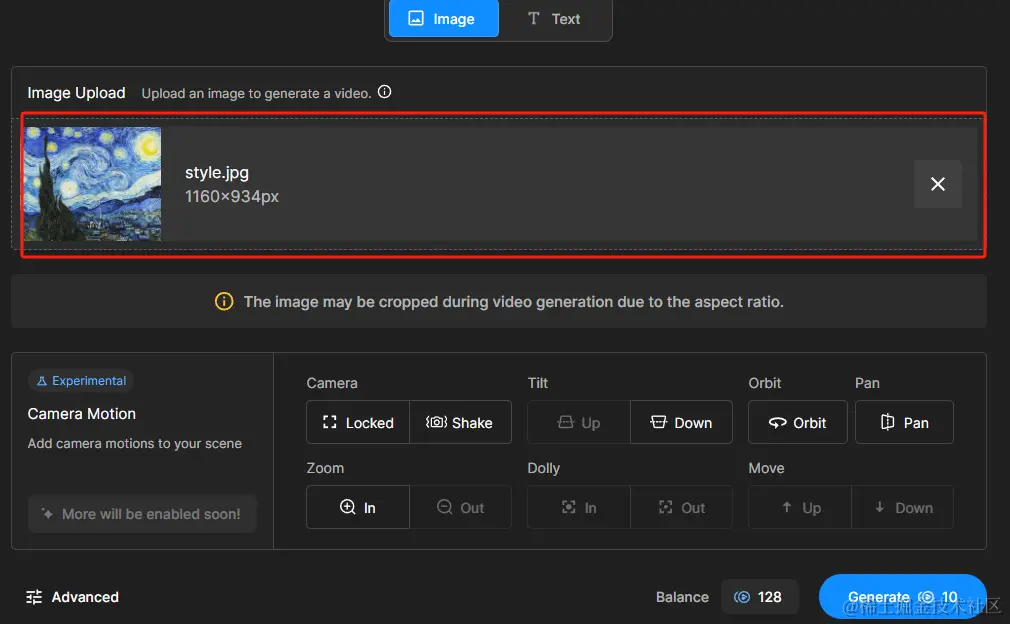
图生视频:通过上传一张预先准备好的图片即可生成想要的视频
特点
- 每天免费
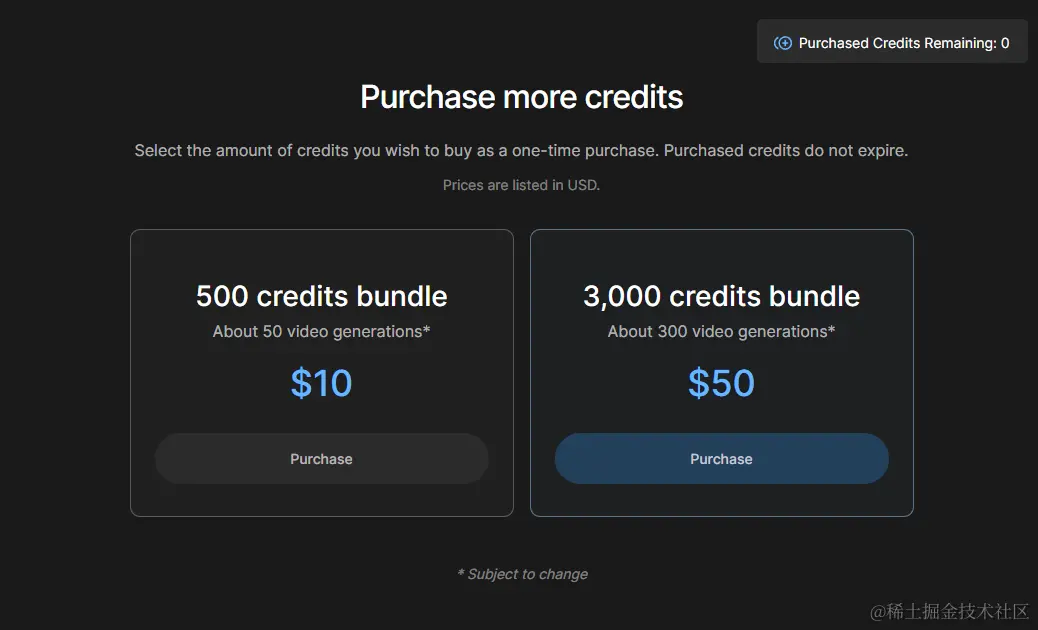
150 积分,平均可以生成 15 段视频,如果觉得积分不够用,有能力的同学还可以自行充值,10 美金500 各积分,或者50 美金3000 各积分,肯定是后者更加划算,这算下来能生成 200-300 个视频片段
网页在线使用,不需要自己在本地手动安装,上手容易,避免很多不必要的麻烦,同时降低了使用的门槛,让大部分普通用户也能投身于这一伟大的事业2-4 秒的 MP4 影片,效果惊艳,我觉得可以抵得上一般的电影画质了!- 支持
文生视频、图生视频,这是两种主流的方式! - 支持
相机运动,不同的相机运动会产生不同的影片风格,如镜头锁定,镜头环绕,镜头旋转等等,快去试试吧!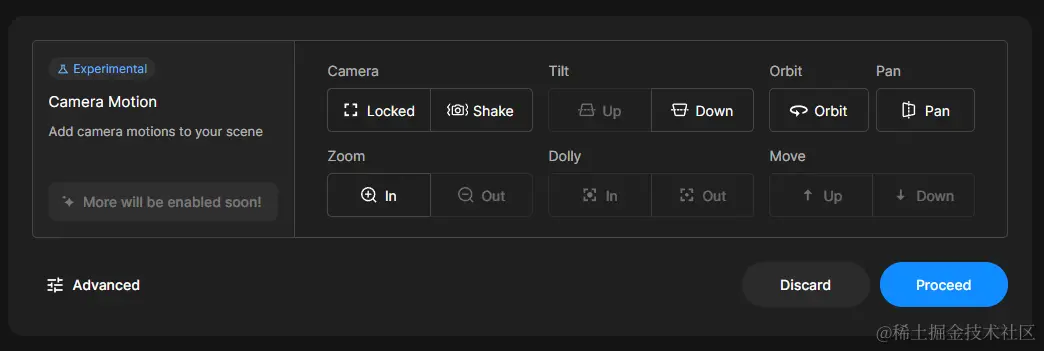
- 支持
不同的视频风格,比如动漫、艺术、3D 效果等等!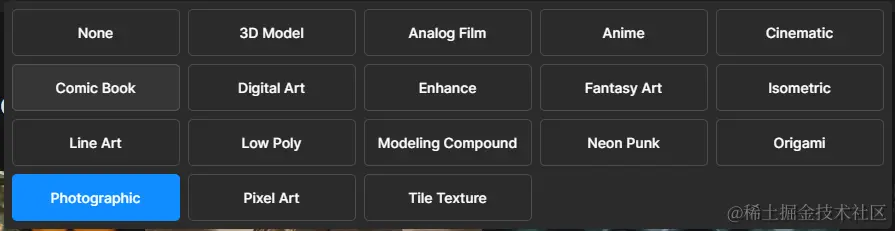
生成效果
下面就来欣赏一下精美画面吧!




适合什么人?
- 内容创作者,如最主要的就是电影、视频创作者、广告创作者等这一紧密相关的人群
- 普通用户,尤其是自己有丰富想象力并且想将其实现的人
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









