




 本文深入讲解了KMP算法的核心思想及其实现过程,通过对比BF算法指出KMP算法的优势所在,即通过避免不必要的回溯提高了模式匹配的速度。
本文深入讲解了KMP算法的核心思想及其实现过程,通过对比BF算法指出KMP算法的优势所在,即通过避免不必要的回溯提高了模式匹配的速度。
上节我们讲了BF算法,我们很明显的发现虽然他能实现模式匹配,但明显他的速度太
慢,每次匹配失败后i和j都要回到0号位置,继续匹配,时间复杂度是O(mn),所以
KMP算法就来解决这个问题。
KMP的核心是匹配失败后i不变,而j要回到他的“k”值位置,继续比较。
于是问题来了,“k”值是什么,为什么要回到“k”值?
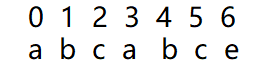
以这个为例,我们规定 0号位置的“k”值是-1,1号位置的“k”值是0,从2号位置
看,如图
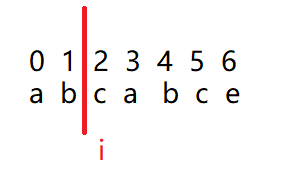
此时i指的是2号位置,要求2号位置的k值,就是要看以0号位置为首的字符串和以i-1
号为尾的字符串最大相等的长度是多少。很显然a与b不相等,所以2号位置的“k”值
等于0。然后依次写出,用next数组存放,那我们该如何用代码实现
public static void getNext(int next[],String str1){
next[0] = -1;
next[1] = 0;
int j = 2;//下一项
int k = 0 ; //前一项的k值
while(j<str1.length()){
if(k==-1||str1.charAt(k) == str1.charAt(j-1)){
next[j] = k+1;
j++;
k++;
}else{
k = next[k];
}
}
}可以看出当k号位置与j-1号位置存放的不相等时,我们的k会返回到next[K],可为什么
要返回到next[k]那?

以如图举例,i-1号位置和next[k]也就是next[2],d与b不相等,于是k = next[k]=2,
为什么要跳到2号位置那?仔细看就会发现2号位置前面的刚好与i-1前面的相等,所以
就判断b与d是否相等,结果是不相等,然后继续跳转到1号位置,而为什么跳到1,因
为i-1前面也是a与k-1相等,所以我们的k位置都是已经前端匹配成功的字符,跳转到k
就是节省匹配的次数。因此我们KMP算法的时间复杂度是O(m+n)。
看一下算法的的实现:
public static int kmp(String str,String str1,int pos){
int i = pos;
int j = 0;
int [] next = new int [str1.length()];
getNext(next,str1);
while(i<str.length()&&j<str1.length()){
if(j==-1||str.charAt(i) == str1.charAt(j)){
i++;
j++;
}else{
j = next[j];
}
}
if(j>=str1.length()){
return i-j;
}else{
return -1;
}
}以上是我简单总结的,如有不足请多多指教

















 4081
4081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









