










25年2月来自 CMU 和匹兹堡大学的论文“LAMS: LLM-Driven Automatic Mode Switching for Assistive Teleoperation”。
通过低自由度控制器(如操纵杆)遥操作高自由度 (DoF) 机器人操纵器,通常需要在控制模式之间频繁切换,其中每种模式将控制器运动映射到特定的机器人动作。手动执行这种频繁切换会使遥操作变得繁琐且效率低下。另一方面,现有的自动模式切换解决方案(例如基于启发式或基于学习的方法)通常是针对特定任务的,缺乏通用性。本文介绍 LLM 驱动的自动模式切换 (LAMS),这是一种利用大语言模型 (LLM) 根据任务上下文自动切换控制模式的方法。与现有方法不同,LAMS 不需要事先进行任务演示,并通过集成用户生成的模式切换示例来逐步改进。
机器人遥操作系统面临的一个关键挑战,是将控制器的有限自由度 (DoF) 映射到机器人的更高自由度,尤其是对于高自由度机器人操纵器。这一挑战在辅助应用中尤为突出,运动障碍用户,依靠低自由度辅助设备(如基于舌头的操纵杆 [1]、[2]、头部定位系统 [3]、[4]、眼神注视控制 [5]、[6] 和吸气和吹气系统 [7]、[8])来执行日常任务。
简单的控制器(例如 2-DoF 操纵杆)通常要求用户在不同的控制模式之间切换,其中每种模式都定义操纵杆的四个运动方向(上、下、左、右)到特定机器人动作(例如平移、旋转或夹持器控制)的特定映射。当用户必须频繁切换模式来完成长期、多阶段任务时,这个过程变得繁琐,导致效率低下和认知压力。例如,在遥控机械臂将书本放到书架上时(如图右侧两个子图所示),用户必须针对每个子任务在不同模式之间切换:平移和旋转机器人末端执行器以与书本对齐,闭合夹持器以抓住书本,再次平移和旋转以将书本与书架对齐,最后放置书本。这些频繁的模式切换会中断工作流程,迫使用户反复回忆并选择正确的模式,这会增加挫败感和认知负荷,并降低任务效率 [9]–[11]。
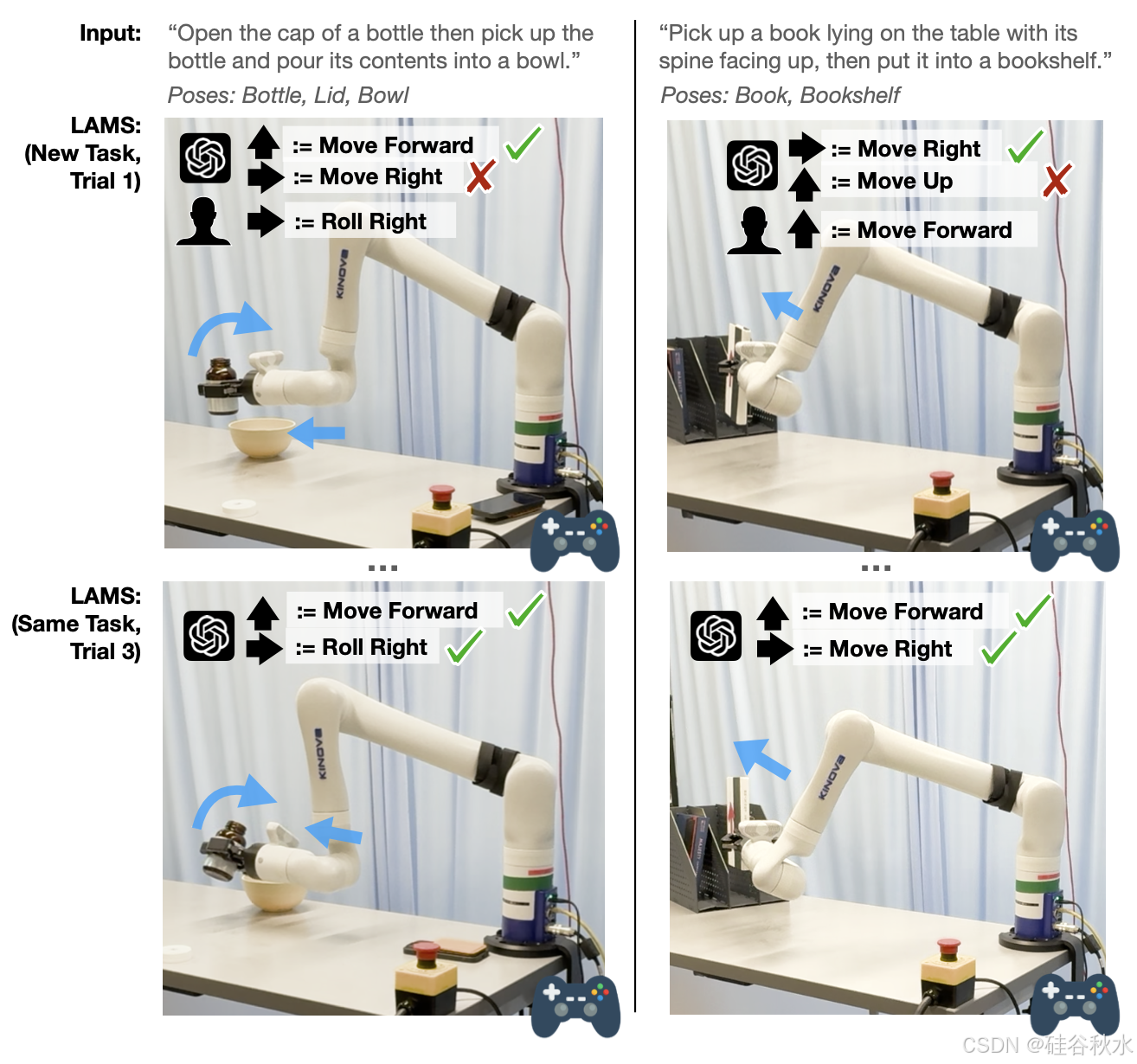
为了解决这个问题,自动模式切换旨在无缝处理这些转换,让用户专注于任务本身而不是控制机制。先前的研究已经探索使用启发式方法 [12]、[13]、强化学习 [14]、[15] 和优化技术 [9] 在遥控和辅助机器人中自动进行模式切换。然而,其中许多解决方案都是针对特定任务的,需要针对每个任务进行演示或手工设计规则,这限制了它们在新场景中的通用性。
自动模式切换。先前的几项研究已经探索自动模式切换,以减少与手动模式切换相关的认知负荷和低效率。例如,Herlant [9] 提出一个时间最优模型,该模型使用时间作为成本指标,利用 Dijkstra 算法预测机器人何时应自动更改模式。然而,像 Dijkstra 这样的算法,计算最佳行驶成本,会产生相对于搜索空间大小的组合计算成本,这使得它们不适用于现实世界应用中的高自由度机械臂等高维系统。最近,Gopinath [12] 提出一种方法,该方法通过将用户置于控制模式中来执行模式切换,从而最大限度地消除场景中各个目标之间的歧义。然而,这种方法依赖于有效的人类意图识别,这仍然是一个定义不明确且具有挑战性的问题。Quere [13] 采用不同的方法,将任务分为多个相位,每个相位都有不同的运动约束和输入映射。为此,这种方法需要大量的手工设计来定义任务相位、约束和映射,从而限制其在不同任务中的可扩展性和灵活性。此外,Pilarski [14] 和 Kizilkaya [15] 利用强化学习 (RL) 进行自动模式切换。然而,这些方法需要大量训练才能部署 RL 智体,这限制了它们在现实世界中的适用性。Kizilkaya [15] 还依赖现实世界的数据集进行训练,这进一步限制了它们对新环境或任务的通用性。除了这些限制之外,大多数现有的自动模式切换方法都是特定于任务的,需要量身定制的演示或手工设计的规则,这限制了它们对新任务的可扩展性和通用性。
学习的潜动作模型。另一项相关研究解决将控制器有限 DoF 映射到机器人更高 DoF 的挑战,该研究利用学习的潜动作模型 [22]–[26]。这些方法训练自动编码器来应对挑战:在训练期间,编码器将高维机器人动作压缩到与低 DoF 控制器匹配的潜空间中,而解码器则重建原始的高维动作。在部署期间,用户的控制输入被送到解码器中以生成相应的机器人动作。虽然这些方法为解决遥操作挑战提供一种模式切换的替代方案,但它们通常依赖于大量训练数据集和大量专家演示,在某些情况下,还需要用户注释过程来确保直观控制 [22]。这种数据收集成本高昂、难以扩展,并且难以适应新任务和环境。值得注意的是,其中一项工作试图最大限度地减少对人工演示的需求 [26],但他们的用户研究表明,“当无人监督的机器人学会意想不到的行为时,用户会感到困惑”。
大语言模型 (LLM) 在广泛的应用中表现出色 [16]– [20],它们凭借常识推理能力为这些挑战提供有希望的解决方案 [21]。
用于机器人规划和控制的 LLM。最近的研究在利用 LLM 生成机器人规划和控制信号方面取得巨大成功,例如将高级任务描述分解为中级规划 [27]–[30]、生成机器人代码 [31]–[34]、生成末端执行器姿势序列 [35] 以及选择运动基元 [36]。LLM 还被集成到与人类交互的机器人系统中。例如,Mahadevan [37] 使用 LLM 生成和修改富有表现力的机器人行为,例如点头与人类互动。Padmanabha [38] 将 LLM 集成到喂食机器人中。Pandya [39] 为外科医生引入一个支持 LLM 的界面来控制机器人工具。虽然这些方法代表使用 LLM 进行机器人规划和控制的重大进展,但探索使用 LLM 促进人类对机器人进行遥控的工作却很少。
本文利用 LLM 进行自动模式切换,假设 LLM 可以利用其丰富的上下文理解能力在新任务中做出有效的模式切换预测,而无需预先收集演示或手工设计规则。
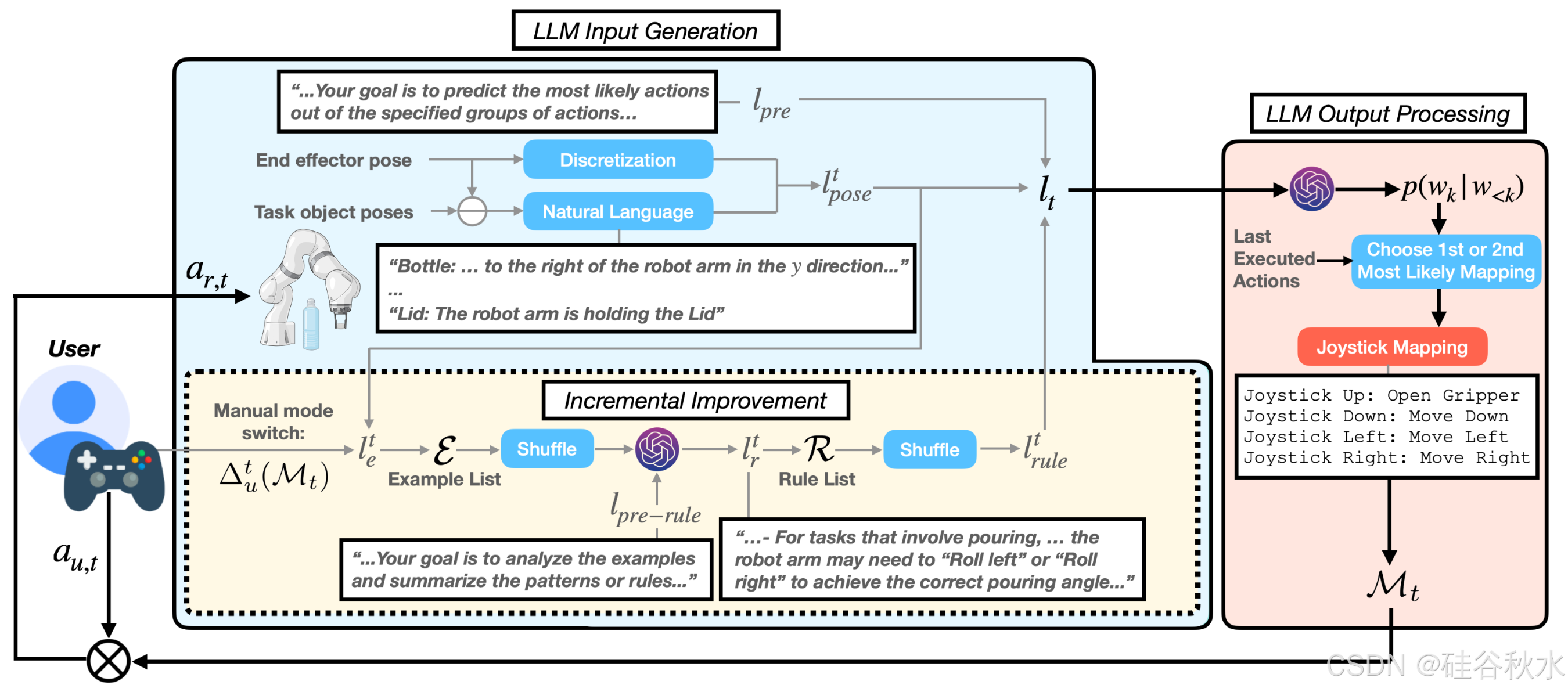
LAMS 框架如图所示:
考虑这样的场景:人类操作员遥操作高自由度机器人手臂,使用低自由度控制器执行操作任务。此任务被建模为一个顺序决策过程,由元组 (S , A_u , A_r, T ) 定义,其中 s_t 表示时间步骤 t 的任务状态,a_u,t (A_u)表示用户动作,a_r,t (A_r)表示机器人动作,m ≪ n,而 T: S × A_r → S 是不可观察的转换函数。
在实验中,机器人的动作空间是 7 维(即 n = 7),即 a_r,t = (∆x_t, ∆y_t, ∆z_t, ∆roll_t, ∆pitch_t, ∆yaw, ∆gripper_t)。用具有两个自由度(m = 2)的操纵杆作为人机控制界面,用户动作 a_u,t 表示操纵杆移动,一个二维向量。
目标是定义一个函数 F(s_t, a_u,t): S × A_u → A_r,将任务状态和用户输入转换为最适合该任务的机器人动作。由于专注于模式切换,旨在生成一个有效的映射 M,将每个操纵杆移动方向与相应的机器人动作方向对齐,如图所示。具体来说,在设置中,操纵杆移动方向映射到以下机器人动作方向,具体取决于当前的控制模式:
D_up:{向前移动、向上移动、向上俯仰、打开夹持器},
D_down:{向后移动、向下移动、向下俯仰、关闭夹持器},
D_left:{向左移动、向左偏航、向左滚动},
D_right:{向右移动、向右偏航、向右滚动}。
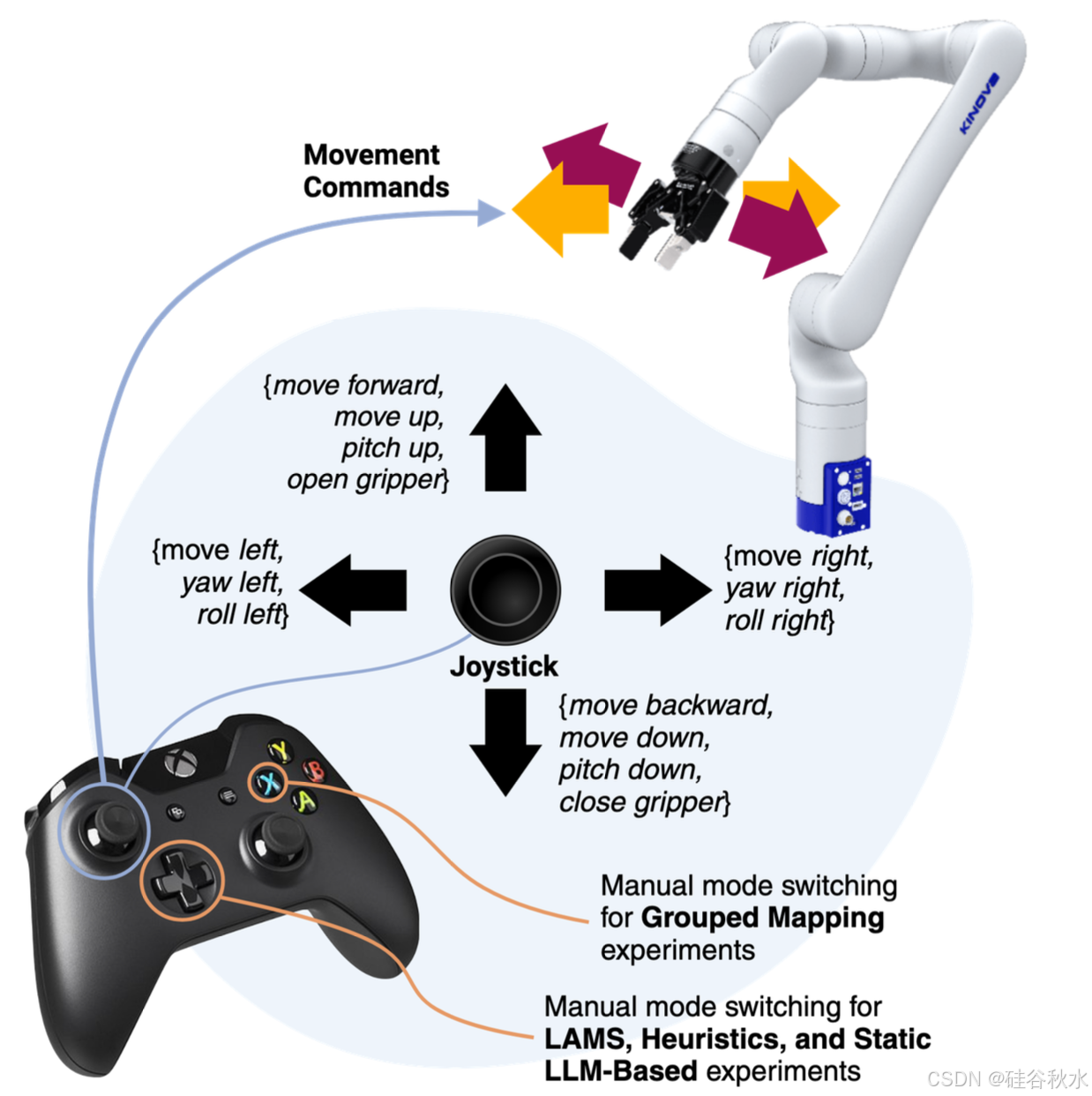
机器人速度与用户动作 a_u,t 的大小成正比:a_u,t 的每个元素都通过一个常数标量因子 v_m 缩放,以根据控制模式控制相应机器人动作方向的速度。索引 m ∈ {tr, ro, gr} 指定动作维度是否对应于平移、旋转或夹持器打开/关闭。
在这项工作中,利用 LLM 来执行函数 F(s_t, a_u,t)。具体来说,将该函数分解为三个阶段:F(s_t, a_u,t) = O(LLM(L(s_t)), a_u,t), 其中 L (s_t) 表示将任务状态落地为语言指令 l_t,然后将其输入到 LLM 中。L 定义为自然语言集。LLM 的输出由 O(·, a_u,t) 处理以产生机器人动作 a_r,t。LAMS 开始时没有特定于任务的演示,这意味着没有预定义的输入输出示例。目标是随着用户与系统的交互逐步完善此功能。本工作中使用的所有 LLM 均由 GPT-4o 提供支持。
在每个时间步骤 t,当需要模式切换时,LLM 的输入是语言指令 l_t = [l_pre, l_rulet, l_pose^t],其结构由三个主要组件组成。
l_pre 是一个提示前缀,它为 LLM 提供目标和输出格式等上下文。
l_rulet 包含指导 LLM 模式切换预测的规则。这些规则源自用户生成的模式切换示例。l_rule^t 最初为空,随着用户与 LAMS 交互而逐渐增大。
最后一个组件 l_pose^t,提供对机器人手臂当前姿势和任务相关目标的描述。对于机器人手臂,将其姿势编码为一个字典,其中包含末端执行器的笛卡尔坐标和欧拉角以及夹持器状态。对于任务目标,用自然语言语句描述每个目标相对于机器人手臂末端执行器六个维度的相对位置。
当需要模式切换时(在实验中,这种情况发生在任务开始时或用户暂停 1.5 秒以发出模式切换信号时),LLM 会被提示从每个动作方向组中预测最可能的动作方向:D_up、D_down、D_left、D_right,从而得到四个预测的动作方向。
一种简单的模式切换方法是,将操纵杆的四个移动方向直接映射到 LLM 的自然语言响应。但是,在任务的某些阶段,用户可能同样需要多个动作。如果用户已经从 D_i 执行一个动作,并期望系统将模式切换到不同的动作映射,则在这种情况下 LLM 的响应可能对用户来说无效。
为了解决这个问题,利用 LLM 的一个基本机制:LLM 不会直接生成单个响应,而是生成可能的下一个单词概率分布,表示为 p(w_k |w_<k ),其中 w_k 是响应中第 k 个位置生成的单词。利用这个概率分布,可以评估 D_i 中每个机器人动作的可能性。正式来说,对于组 D_i 中具有自然语言表示 d_i,j 的每个机器人动作,其中 j 表示 D_i 中动作的索引,计算 p(d_i,j |o_i),其中 o_i 表示 d_i,j 之前的 LLM 响应。
对于每个组,如果在当前模式切换调用之前刚刚执行具有最大 p(d_i,j |o_i) 的机器人动作,即 d_i∗ = argmax_d_i,j p(d_i,j |o_i),将检查第二大可能动作的概率 d∗_i∗ = arg max_d_i,j̸= d_i^∗ p(d_i,j|o_i) 是否超过预定义阈值(经验上设置为 0.2)。如果是,使用 d∗_i∗;否则,使用 d∗_i。
通过这个过程,得到 d_up、d_down、d_left、d_right,分别对应于操纵杆的四个运动方向。最终的机器人动作 a_r,t 是从 A_x 和 A_y 中选择的动作组合,取决于 d_up、d_down、d_left、d_right 和用户的动作 a_u,t。
虽然 LAMS 即使在第一次交互中也能够对未见过的任务执行有用的自动模式切换,但由于任务知识有限,它可能会遇到错误。为了解决这个问题,将 LAMS 设计为在用户与系统交互时逐步改进。这是通过合并用户生成的模式切换示例增强提示 l_rule^t 来实现的。
具体来说,在任务执行期间,图形用户界面 (GUI) 会持续显示当前模式 M_t,该模式显示映射到每个操纵杆运动的四个机器人动作方向。如果用户对 M_t 不满意,可以手动切换到另一个模式 M′_t。此手动模式切换可以表示为 M′_t = ∆_u^t (M_t),然后将其转换为自然语言格式 l_∆_u^t (M_t)。例如,在实验中,用户发起的 l_∆_u^t (M_t) 的一个实例是:{“Joystick Up”:“Pitch up”}。这意味着用户将“Joystick Up”的映射从不太喜欢的动作切换为“Pitch Up”。
为了促进 LAMS 的逐步改进,为每个任务维护一个例子列表 E。每次进行 ∆_ut(M) 时,l_poset和 ∆_ut(M) 都会以自然语言格式形成一个示例 l_e^t,并将其添加到 E。
将这些示例总结为模式切换指导规则,可以为 LAMS 带来更有效、更稳健的改进,而不是直接将它们合并到 LLM 的输入中。为了实现这一点,除了例子列表 E,还为每个任务维护一个规则列表 R,该列表从空开始,随着用户执行任务而增长。使用 E 和 R,每次将新示例添加到 E 时,所有示例都会被打乱并连同提示前缀 l_pre-rule 一起输入到一个单独的 LLM(不同于用于自动模式切换的 LLM),生成指导未来模式切换预测的规则。
这个 LLM 自主地生成可变数量的规则 l_rt = {l_r,k^t},k = 1,2,…,N,其中 N 是生成规则的数量。例如,在实验中生成的规则之一是:
- 对于涉及倾倒的任务,例如将瓶子中的内容物倒入碗中,机械臂可能需要“向左滚动”或“向右滚动”才能达到正确的倾倒角度,尤其是在瓶子已经被握住的情况下。
l_r^t 附加到 R。
此规则列表更新过程,发生在每次手动模式切换之后,而不仅仅是在任务结束时。这使得 LAMS 能够在任务执行过程中动态改进,即使在用户第一次尝试时也是如此。这种设计使 LAMS 即使在用户第一次与系统交互时也能胜过基于静态 LLM 的方法。
使用规则列表 R,当需要模式切换时,R 中的规则将被打乱以形成 l_rule^t ,它用作 LLM 输入提示的一部分。在当前的方法中,规则在任务之间重置以确保独立评估。然而,某些规则在各种操作任务中是可以通用的,例如伸手去抓取目标并对准目标。未来的工作可以探索一套共享的、可适应的规则集,利用用户在各种任务中的累积互动。
所有实验均使用 Kinova Gen3 机械臂进行,用户通过 Xbox 控制器控制机器人。具体来说,控制器上的左操纵杆用于生成用户动作 a_u,t。操纵杆移动方向和机器人动作方向之间的映射要么由自动模式切换方法(例如 LAMS)确定,要么由用户在对自动切换不满意时手动调整。
要在 LAMS 中执行手动模式切换 ∆_u^t(M),用户按下 Xbox 控制器 D-pad 上的一个方向按钮。此操作会更新相应操纵杆方向的映射,而不会影响其他方向。例如,按下 D-pad 上的“向上”会更改操纵杆向上推的映射,而其他方向的映射保持不变。此手动模式切换过程使用户能够纠正自动模式切换方法所造成的错误,以确保任务完成,同时还提供帮助 LAMS 随着时间推移逐步改进的示例。
主要评估指标是用户手动模式切换的次数,切换次数越少,表示自动模式切换越有效。
在两个复杂的多阶段任务上评估 LAMS:
- 倒水:打开瓶盖,然后拿起瓶子,将瓶子里的东西倒进碗里。
- 存放书籍:拿起放在桌子上书脊朝上的书,然后将其放入书架中。
对于每项任务,为了评估 LAMS 逐步改进的能力,一个完整的实验包含三个交互,用户每次使用不同的目标布局完成任务三次。这些交互称为“试验 1”、“试验 2”和“试验 3”。
如图所示用户研究的实验设置。参与者坐在机械臂后面。在整个研究过程中,用户可以持续看到显示当前控制模式的 GUI,其中显示映射到每个操纵杆运动的四个机器人动作方向。


















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









