










25年2月来自上海AI实验室、清华大学、哈工大和北邮的论文“Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling”。
测试-时间规模化 (TTS) 是通过在推理阶段使用额外计算来提升大语言模型 (LLM) 性能的重要方法。然而,当前的研究并没有系统地分析策略模型、过程奖励模型 (PRM) 和问题难度如何影响 TTS。这种分析的缺乏限制对 TTS 方法的理解和实际使用。本文关注两个核心问题:(1)在不同的策略模型、PRM 和问题难度级别之间规模化测试-时间计算的最佳方法是什么?(2)规模化计算可以在多大程度上提高 LLM 在复杂任务上的性能,较小的语言模型是否可以通过这种方法胜过较大的语言模型?通过对 MATH-500 和具有挑战性的 AIME24 任务进行全面实验,得到以下结果:(1)计算最优的 TTS 策略高度依赖于策略模型、PRM 和问题难度的选择。(2)通过计算最优的 TTS 策略,极小的策略模型可以胜过较大的模型。例如,在 MATH-500 上,1B LLM 可以超过 405B LLM。此外,在 MATH-500 和 AIME24 上,0.5B LLM 的表现优于 GPT-4o,3B LLM 超过 405B LLM,7B LLM 击败 o1 和 DeepSeek-R1,同时推理效率更高。这些发现表明,根据每个任务和模型的具体特点调整 TTS 策略非常重要,并表明 TTS 是一种有前途的增强 LLM 推理能力方法。
大语言模型 (LLM) 已在多个领域表现出显著的改进 (OpenAI, 2023;Hurst,2024;Anthropic,2023;OpenAI,2024;DeepSeek-AI,2025)。最近,OpenAI o1 (OpenAI, 2024) 证明,测试-时间规模化 (TTS) 可以通过在推理时分配额外的计算来增强 LLM 的推理能力,使其成为提高 LLM 性能的有效方法 (Qwen Team, 2024;Kimi Team,2025;DeepSeek-AI,2025)。
TTS 方法可分为两大类:(1)内部 TTS,使用长思维链 (CoT) 训练 LLM 缓慢“思考”(OpenAI,2024;DeepSeek-AI,2025);(2)外部 TTS,使用固定 LLM 通过采样或基于搜索的方法来提高推理性能(Wu,2024;Snell,2024)。外部 TTS 的关键挑战是如何以最佳方式规模化计算,即为每个问题分配最佳计算(Snell,2024)。当前的 TTS 方法使用过程奖励模型 (PRM) 来指导生成过程并选择最终答案,从而有效地规模化测试-时间计算(Wu,2024;Snell,2024;Beeching,2024)。这些 TTS 方法涉及几个重要因素,例如策略模型、PRM 和问题难度级别。然而,对于策略模型、PRM 和问题难度如何影响这些 TTS 策略的系统分析有限。这一限制阻碍社区充分了解此方法的有效性并开发计算最优 TTS 策略的见解。
LLM 测试-时间规模化。规模化 LLM 测试-时间计算,是提高性能的有效方法 (OpenAI, 2024)。先前的研究探索多数投票 (Wang et al., 2023)、基于搜索的方法 (Yao et al., 2023; Xie et al., 2023; Khanov et al., 2024; Wan et al., 2024) 和细化 (Qu et al., 2024) 来提高性能。对于验证引导的测试-时间计算,Brown (2024) 探索使用重复采样和域验证器的推理计算,而 Kang (2024);Wu (2024);Snell (2024) 进一步探索具有过程奖励指导的基于搜索方法,Wang (2024c) 将此设置扩展到 VLM。为了消除对外部奖励模型和大量样本生成的需求,Manvi (2024) 提出一种自适应高效测试-时计算的自我评估方法。最近的一项工作 (Beeching,2024) 通过具有多样性的搜索方法探索 TTS。然而,这些工作缺乏对强验证器或具有不同大小/能力的策略的评估。
提高 LLM 的数学推理能力。提高数学推理能力的现有方法,可分为训练-时方法和测试-时方法。对于训练时方法,先前的研究探索大规模数学语料库预训练(OpenAI,2023;Azerbayev,2024;Shao,2024)和监督微调(Luo,2023;Yu,2024;Gou,2024;Tang,2024;Tong,2024;Zeng,2024)以提高数学能力。另一系列研究探索自我训练和自我完善策略(Zelikman,2022;Gulcehre,2023;Trung,2024;Hosseini,2024;Zelikman,2024;Zhang,2024a;Setlur,2024a;Kumar,2024;Cui,2025),通过对自我生成的解决方案进行微调来提高推理能力。最近,许多工作提高具有长 CoT 的数学推理能力 (Qin et al., 2024; Huang et al., 2024; Kimi, 2024; DeepSeek-AI et al., 2025; Qwen Team, 2024; Skywork, 2024; Zhao et al., 2024),例如 OpenAI o1 (OpenAI, 2024) 表现出非常强大的长思考推理能力。
对于测试-时间方法,基于提示的方法已经得到广泛研究,以在不改变模型参数的情况下增强推理能力。诸如思维链 (CoT) (Wei et al., 2022) 及其变型 (Yao et al., 2023; Leang et al., 2024) 之类的技术指导模型将问题分解为可管理的子步骤,从而提高数学推理的准确性和连贯性。除了提示策略之外,自我改进技术 (Madaan,2023) 允许模型检查和更正其输出,而外部工具集成 (Gao,2023;Chen,2023) 利用程序解释器或符号操纵器执行精确的计算和验证。自我验证方法 (Weng,2023) 使模型能够评估其自身推理过程的正确性,从而进一步提高鲁棒性。这些测试-时间策略补充训练-时间增强,共同促进 LLM 数学推理能力的显着提高。
过程奖励模型。先前的研究表明,PRM 比 ORM 更有效 (Uesato,2022;Lightman,2024)。然而,收集高质量的 PRM 数据(例如 PRM800K(Lightman,2024))通常成本高昂。研究人员探索通过直接蒙特卡洛估计(Wang,2024b)自动收集 PRM 数据、检测 ORM 的相对分数(Lu,2024)和使用二分搜索的高效 MCTS(Luo,2024)进行自动收集 PRM 数据。最近,从优势建模(Setlur,2024b)、𝑄 -值排名(Li & Li,2024)、隐性奖励(Yuan,2024)和熵正则化(Zhang,2024b)的角度探索更先进的 PRM。此外,还有更多开源 PRM 发布(Xiong,2024;Skywork,2024;Zhang,2024b;Li & Li,2024;Yuan,2024;Zhang,2025),在数学任务上表现出色。随着 PRM 的快速发展,ProcessBench(Zheng,2024)和 PRMBench(Song,2025)被提出来对 PRM 进行全面评估。Zhang(2025)为 PRM 的实际开发提供指导方针,并发布最新的数学任务中最强大的 PRM。
以下分析 TTS 实验的影响因素。
设置
将推理问题表述为马尔可夫决策过程 (MDP) (Sutton & Barto, 2018),由多元组 (𝒮, 𝒜, 𝒫, R, 𝛾) 定义,其中 𝒮 是状态空间,𝒜 是动作空间,𝒫 是转换函数,R 是奖励函数,𝛾 ∈ [0, 1] 是折扣因子。给定提示 𝑥 ∼ 𝒳,具有参数 𝜃 的策略会生成初始动作 𝑎_1 ∼ 𝜋_𝜃(· | 𝑠_1),其中 𝑠1 = 𝑥 是初始状态。该策略获得奖励 R(𝑠_1, 𝑎_1),状态转换为 𝑠_2 = [𝑠_1, 𝑎_1],其中 [·, ·] 表示两个字符串的连接。此过程持续到episode终止,终止方式是达到最大步数或生成 token。长度为 𝐻 的轨迹表示为 𝜏 = {𝑎_1, 𝑎_2, · · · , 𝑎_𝐻}。
分析考虑三种 TTS 方法:Best-of-N (BoN) (Brown,2024)、波束搜索 (Snell,2024) 和多样化验证器树搜索 (DVTS) (Beeching,2024)。正如 Snell (2024) 指出的那样,由于多步采样,前瞻搜索效率低下,因此不评估它或其他涉及前瞻操作的方法,例如蒙特卡洛树搜索 (MCTS)。TTS 方法如图所示:
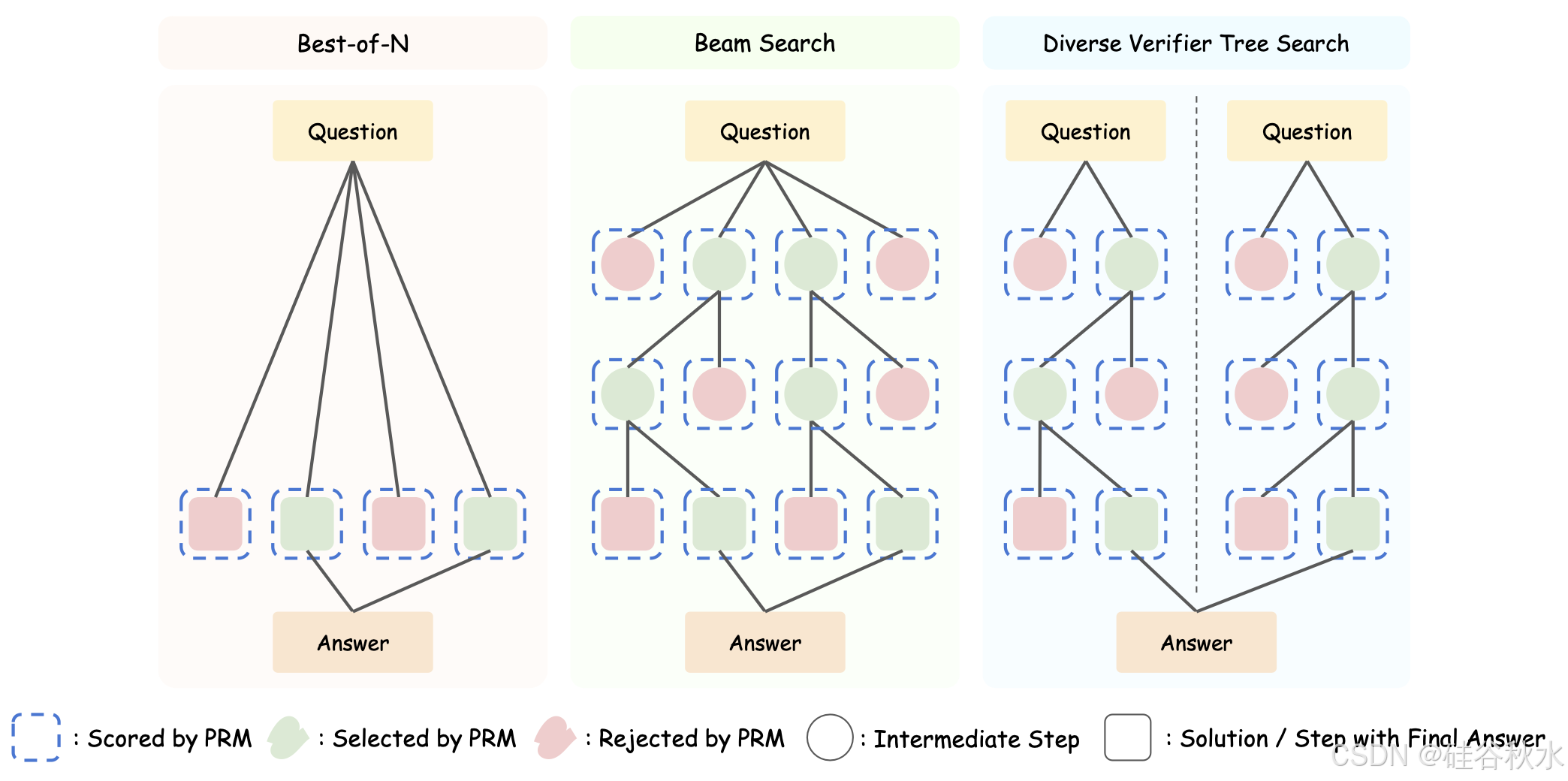
Best-of-N。在 BoN 方法中,策略模型生成 𝑁 个响应,然后应用评分和投票方法来选择最终答案。
波束搜索。给定波束宽度 𝑁 和波束大小 𝑀,策略模型首先生成 𝑁 个步骤。验证器选择前 𝑁 个步骤进行后续搜索。在下一步中,策略模型为每个选定的上一步采样 𝑀 个步骤。此过程重复进行,直到达到最大深度或生成 token。
多样化验证器树搜索。为了增加多样性,DVTS 通过将搜索过程划分为 𝑁/M 个子树来扩展波束搜索,每个子树都使用波束搜索独立探索。如 Beeching (2024) 所示,DVTS 在具有较大计算预算 𝑁 的简单和中等问题上表现优于波束搜索。在 Chen (2024) 中观察到类似的趋势,其中增加并行子树的数量被证明比在相同预算下增加束宽度更有效。
为了最大限度地提高 TTS 的性能,Snell (2024) 提出一种测试-时间计算优化规模化策略,该策略选择与给定测试-时间策略相对应的超参,以最大限度地提高特定提示的性能优势。给定提示 𝑥,让 Target(𝜃, 𝑁, 𝑥) 表示具有参数 𝜃 和计算预算 𝑁 的策略模型在 𝑥 上产生的输出分布。
重思考计算-最优测试-时间规模化
计算-最优 TTS 旨在为每个问题分配最优计算(Snell,2024)。之前关于 TTS 的研究使用单个 PRM 作为验证器(Snell,2024;Wu,2024;Beeching,2024)。Snell(2024)在策略模型的响应上训练 PRM,并将其用作验证器以相同的策略模型进行 TTS,而 Wu(2024 );Beeching(2024)使用在不同策略模型上训练的 PRM 进行 TTS。从强化学习 (RL) 的角度来看,在前一种情况下获得基于策略的 PRM,在后一种情况下获得离线 PRM。基于策略的 PRM 会为策略模型的响应产生更准确的奖励,而离线 PRM 通常会由于分布不均 (OOD) 问题而产生不准确的奖励(Snell,2024;Zheng,2024)。
对于计算最优 TTS 的实际应用,为每个策略模型训练一个 PRM 以防止 OOD 问题在计算上是昂贵的。因此,在更一般的环境中研究计算最优 TTS 策略,其中 PRM 可能在与用于 TTS 策略模型不同的策略模型上进行训练。对于基于搜索的方法,PRM 指导每个响应步骤的选择,而对于基于采样的方法,PRM 在生成后评估响应。这表明 (1) 奖励会影响所有方法的响应选择;(2) 对于基于搜索的方法,奖励也会影响搜索过程。
为了分析这些要点,用以 Llama-3.1-8B-Instruct 为策略模型、以 RLHFlow-PRM-Mistral-8B 和 RLHFlow-PRM-Deepseek-8B 为 PRM 的集束搜索进行初步案例研究。结果表明,奖励显著影响生成过程和结果。RLHFlow-PRM-Mistral-8B 为简短的响应分配高奖励,导致答案错误,而使用 RLHFlow-Deepseek-PRM-8B 搜索会产生正确答案但使用更多token。经验表明,奖励对 TTS 性能和输出tokens有很大影响。
基于这些分析,将奖励整合到计算最优 TTS 策略中。对于基于采样的规模化方法,输出分布无需考虑奖励模型。这种奖励-觉察策略可确保计算-最优规模化适配策略模型、提示和奖励函数,从而为实际 TTS 提供更通用的框架。
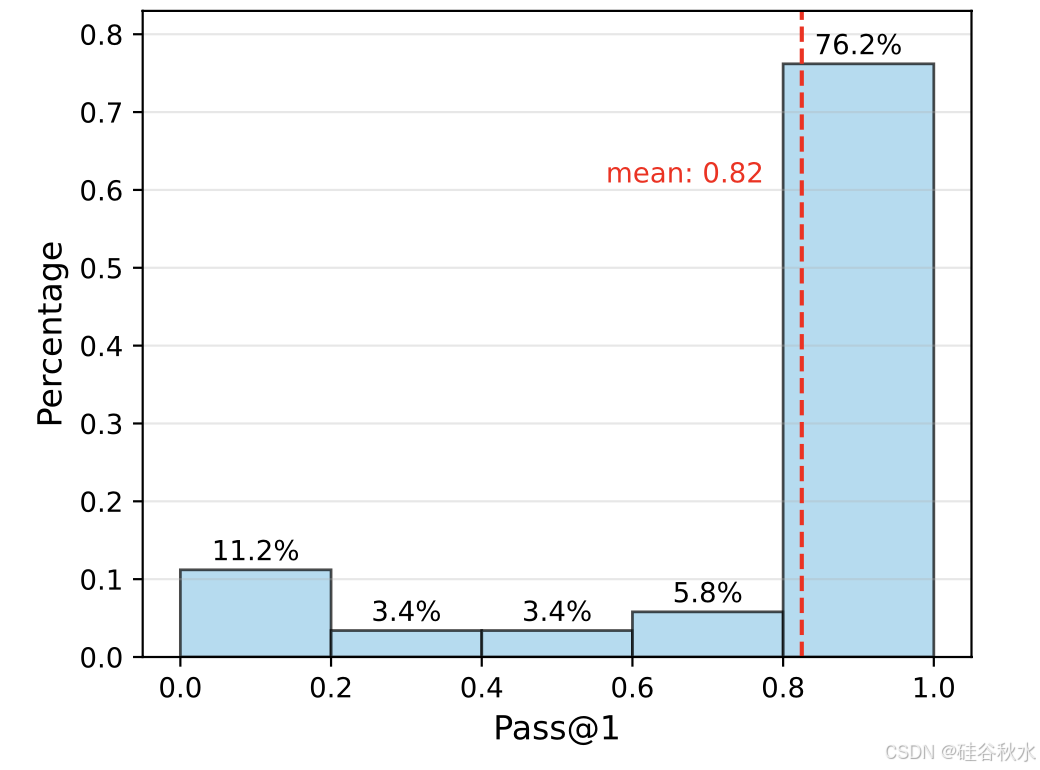
为了考虑问题难度对 TTS 的影响,Snell(2024)根据 Pass@1 准确率分位数将问题分为五个难度级别。然而,使用 MATH 中的难度级别(Hendrycks,2021)或基于 Pass@1 准确率分位数的 oracle 标签(Snell,2024)效果不佳,因为不同的策略模型具有不同的推理能力。如图所示,Qwen2.5-72B-Instruct 在 76.2% 的 MATH-500 问题上实现 80% 以上的 Pass@1 准确率。因此,使用绝对阈值而不是分位数来衡量问题难度。具体而言,根据 Pass@1 准确率定义三个难度级别:简单(50% ∼ 100%)、中等(10% ∼ 50%)和困难(0% ∼ 10%)。
如何以最佳方式规模化测试-时间计算?
在此旨在回答以下问题:
Q1:TTS 如何通过不同的策略模型和 PRM 进行改进?
Q2:TTS 如何针对不同难度级别的问题进行改进?
Q3:PRM 是否对特定的响应长度有偏见或对投票方法敏感?
数据集。在竞赛级数学数据集上进行实验,包括 MATH-500(Lightman,2024)和 AIME24(AI-MO,2024)。MATH-500 包含来自 MATH(Hendrycks,2021)测试集的 500 个代表性问题,该子集按照 Snell(2024);Beeching(2024 年)使用。由于最近的 LLM 在数学推理方面取得重大进展(OpenAI,2024;DeepSeek-AI 等,2025),将更具挑战性的 AIME24 纳入实验。
策略模型。对于测试-时间方法,用不同大小的 Llama 3(Dubey,2024)和 Qwen2.5(Yang,2024b)系列的策略模型。对所有策略模型使用 Instruct 版本。
过程奖励模型。考虑使用以下开源 PRM 进行评估:
• Math-Shepherd(Wang,2024b):Math-Shepherd-PRM-7B 在 Mistral-7B(Jiang,2023)上进行训练,使用在 MetaMath(Yu,2024)上微调的 Mistral-7B 生成的 PRM 数据。
• RLHFlow 系列 (Xiong,2024 年):RLHFlow 包括 RLHFlow-PRM-Mistral-8B 和 RLHFlow-PRM-Deepseek-8B,它们分别基于 Mistral-7B 数据进行训练,并经过 Meta-Math (Yu,2024) 和 deepseek-math-7b-instruct (Shao,2024) 的微调。这两个 PRM 的基础模型都是 Llama-3.1-8B-Instruct (Dubey,2024)。
• Skywork 系列(Skywork o1,2024):Skywork 系列包括 Skywork-PRM-1.5B 和 Skywork-PRM-7B,分别在 Qwen2.5-Math-1.5B-Instruct 和 Qwen2.5-Math-7B- Instruct(Yang,2024c)上进行训练。训练数据由在数学数据集上微调的 Llama-2(Touvron,2023)和 Qwen2-Math(Yang,2024a)系列模型生成。
• Qwen2.5-MathSeries(Zhang etal.,2025):评估 Qwen2.5-Math-PRM-7B 和 Qwen2.5-Math-PRM-72B,分别在 Qwen2.5-Math-7B-Instruct 和 Qwen2.5-Math-72B-Instruct(Yang et al.,2024c)上进行训练。训练数据是使用 Qwen2-Math(Yang et al.,2024a)和 Qwen2.5-Math 系列模型(Yang et al.,2024c)生成的。在列出的所有 PRM 中,Qwen2.5-Math-PRM-72B 是数学任务中最强大的开源 PRM,而 Qwen2.5-Math-PRM-7B 是具有 7B/8B 参数的 PRM 中最强大的 PRM,如 Zhang et al.(2025)所示。
评分和投票方法。按照 Wang (2024a) 的方法,考虑三种评分方法:PRM-Min、PRM-Last 和 PRM-Avg,以及三种投票方法:Majority Vote、PRM-Max 和 PRM-Vote。为了获得最终答案,首先使用评分方法来评估答案。对于长度为 𝐻 的轨迹,使用不同评分方法对每条轨迹的得分计算如下:(1) PRM-Min 根据所有步骤中的最小奖励对每条轨迹进行评分,即得分 = min_R{R_𝑡}。(2) PRM-Last 根据最后一步的奖励对每条轨迹进行评分,即得分 = R_𝐻。 (3) PRM-Avg 根据所有步骤的平均奖励对每条轨迹进行评分,即得分 = ∑︀R_𝑡/H。然后,投票方法汇总得分以确定最终答案。多数投票选择获得多数票的答案(Wang,2023),而 PRM-Max 选择得分最高的答案,PRM-Vote 首先累积所有相同答案的得分,然后选择得分最高的答案。
使用 OpenR(一个开源 LLM 推理框架)作为代码库。对于计算预算,在大多数实验中使用 {4, 16, 64, 256}。步骤的划分遵循 \n\n 格式,与先前的工作一样(Xiong,2024;Zhang,2025)。对于波束搜索和 DVTS,波束宽度设置为 4。CoT 的温度为 0.0,而其他方法的温度为 0.7。对于 CoT 和 BoN,将新 token 的最大数量限制为 8192。对于基于搜索的方法,每个步骤的 token 限制为 2048,总响应的 token 限制为 8192。
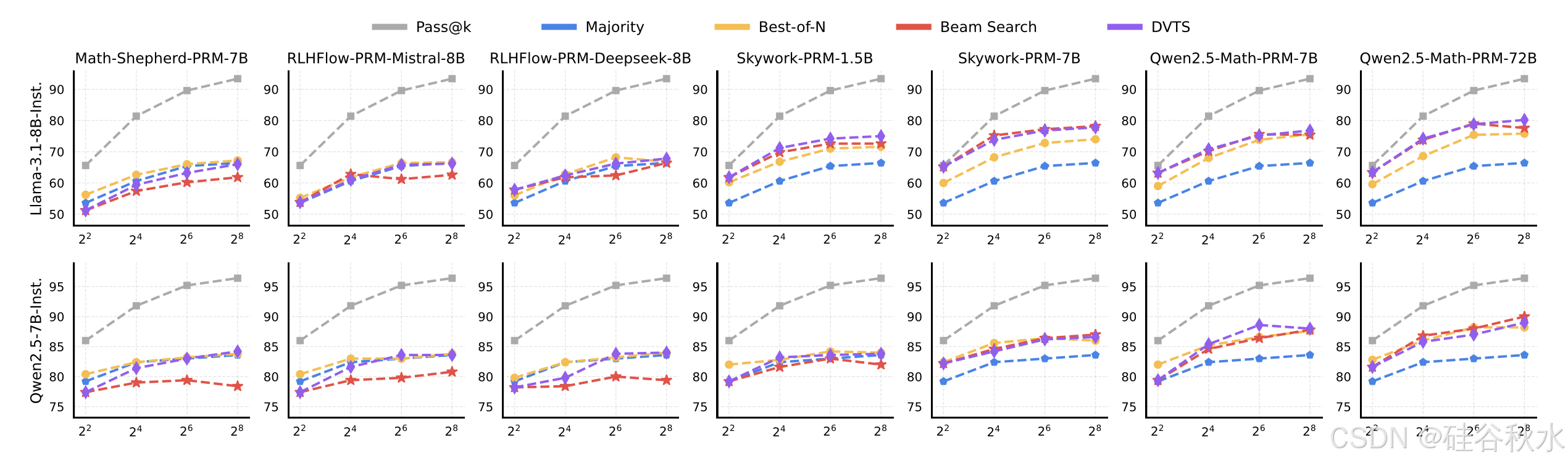
PRM 很难在策略模型和任务之间推广。如下图所示,对于 Llama-3.1-8B-Instruct,使用 Skywork 和 Qwen2.5-Math PRM 基于搜索方法的性能随计算预算的增加而显著提高,而使用 Math-Shepherd 和 RLHFlow PRM 进行搜索的结果仍然相对较差,甚至比多数投票更差。对于 Qwen2.5-7B-Instruct,使用 Skywork-PRM-7B 和 Qwen2.5-Math PRM 进行搜索的性能随着预算的增加而增长,而其他 PRM 的性能仍然很差。
最佳 TTS 方法取决于所使用的 PRM。如下图所示,在使用 Math-Shepherd 和 RLHFlow PRM 时,BoN 在大多数情况下优于其他策略,而使用 Skywork 和 Qwen2.5-Math PRM 时,基于搜索的方法表现更好。出现这种差异是因为使用 PRM 进行 OOD 策略响应会导致次优答案,因为 PRM 在策略模型中表现出有限的泛化能力。此外,如果使用 OOD PRM 选择每个步骤,则很可能会获得陷入局部最优的答案并降低性能。这也可能与 PRM 的基础模型有关,因为使用 PRM800K(Lightman,2024)在 Qwen2.5-Math-7B-Instruct 上训练的 PRM 比以 Mistral 和 Llama 作为基础模型的 PRM(Zhang,2025)泛化得更好。这些结果表明,最佳 TTS 策略的选择取决于所使用的特定 PRM,这强调了在计算最佳 TTS 时考虑奖励信息的重要性。
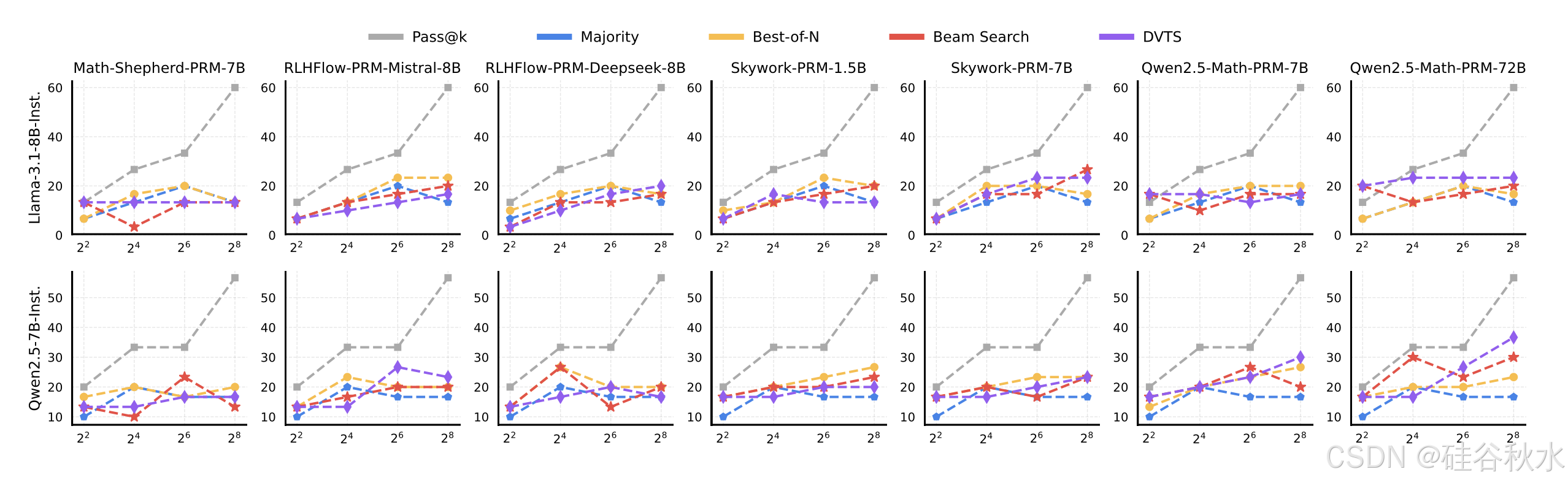
在下图中,虽然两种策略模型的 Pass@k 准确率随计算预算的增加而大幅提高,但 TTS 的性能提升仍然适中。这些结果表明,PRM 在不同策略模型和任务之间的推广尤其具有挑战性,尤其是对于更复杂的任务。
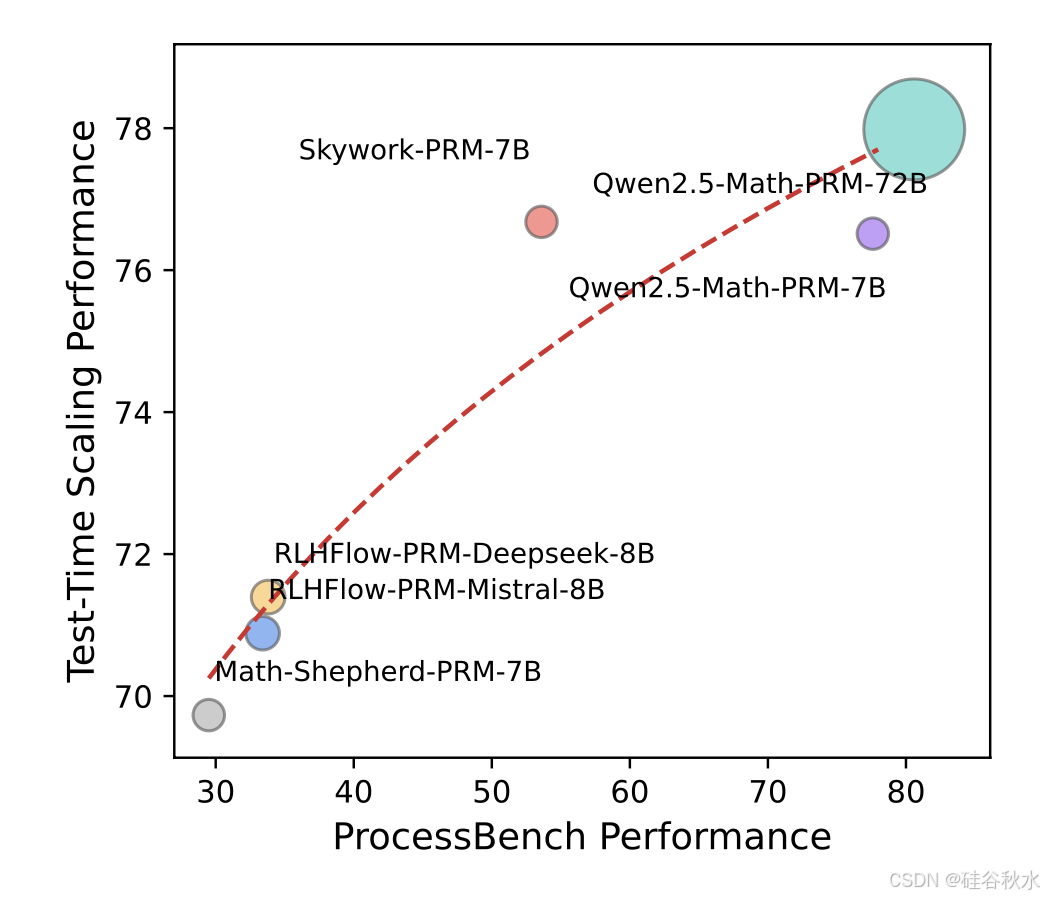
还探讨 TTS 性能与不同 PRM 的过程监督能力之间的关系。如图所示,TTS 性能与 PRM 的过程监督能力呈正相关,拟合函数为 𝑌 = 7.66 log(𝑋) + 44.31,其中 𝑌 表示 TTS 性能,𝑋 表示 PRM 的过程监督能力 (Zhang et al., 2025)。
最佳 TTS 方法因策略模型而异。为了研究策略模型参数与最优 TTS 方法之间的关系,用 Qwen2.5 系列 LLM(Yang et al., 2024b)进行实验,包括参数大小为 0.5B、1.5B、3B、7B、14B、32B 和 72B 的模型。如图结果表明,最优 TTS 方法取决于具体的策略模型。对于小型策略模型,基于搜索的方法优于 BoN,而对于大型策略模型,BoN 比基于搜索的方法更有效。出现这种差异的原因是大型模型具有更强的推理能力,不需要验证器进行逐步选择。相反,小型模型依靠验证器选择每一步,确保每个中间步骤的正确性。

遵循 Snell et al. (2024) 的研究,对不同难度级别的任务进行全面的评估。但是,使用 MATH 中定义的难度级别(Hendrycks,2021)或基于 Pass@1 准确率分位数的 oracle 标签(Snell,2024)并不合适,因为不同的策略模型表现出不同的推理能力。为了解决这个问题,根据 Pass@1 准确率的绝对值将难度级别分为三组:简单(50% ∼ 100%)、中等(10% ∼ 50%)和困难(0% ∼ 10%)。
最佳 TTS 方法因难度级别不同而不同。对于小型策略模型(即参数少于 7B),BoN 更适合简单问题,而波束搜索更适合较难问题。对于参数在 7B 到 32B 之间的策略模型,DVTS 对于简单和中等问题表现良好,而波束搜索对于困难问题更可取。对于具有 72B 参数的策略模型,BoN 是所有难度级别的最佳方法。
PRMs 偏向步骤的长度。虽然在之前的实验中在相同的预算下执行 TTS,但不同 PRM 的推理tokens数量差异很大。例如,给定相同的预算和相同的策略模型,使用 RLHFlow-PRM-Deepseek-8B 进行规模化的推理token数量始终大于 RLHFlow-PRM-Mistral-8B,几乎是 2 倍。RLHFlow 系列 PRM 的训练数据是从不同的 LLM 中采样的,这可能导致输出长度的偏差。为了验证这一点,分析 RLHFlow-PRM-Mistral-8B3 和 RLHFlow-PRM-Deepseek-8B4 训练数据的几个属性。如表所示,DeepSeek-PRM-Data 的平均每响应 token 数和平均每步骤 token 数均大于 Mistral-PRM-Data,说明 RLHFlow-PRM-Deepseek-8B 的训练数据比 RLHFlow-PRM-Mistral-8B 的训练数据长,这可能导致输出结果偏长。我们还发现 Qwen2.5-Math-7B 缩放后的推理 token 数大于 Skywork-PRM-7B,但性能非常接近,说明使用 Skywork-PRM-7B 搜索比使用 Qwen2.5-Math-7B 搜索更有效率。

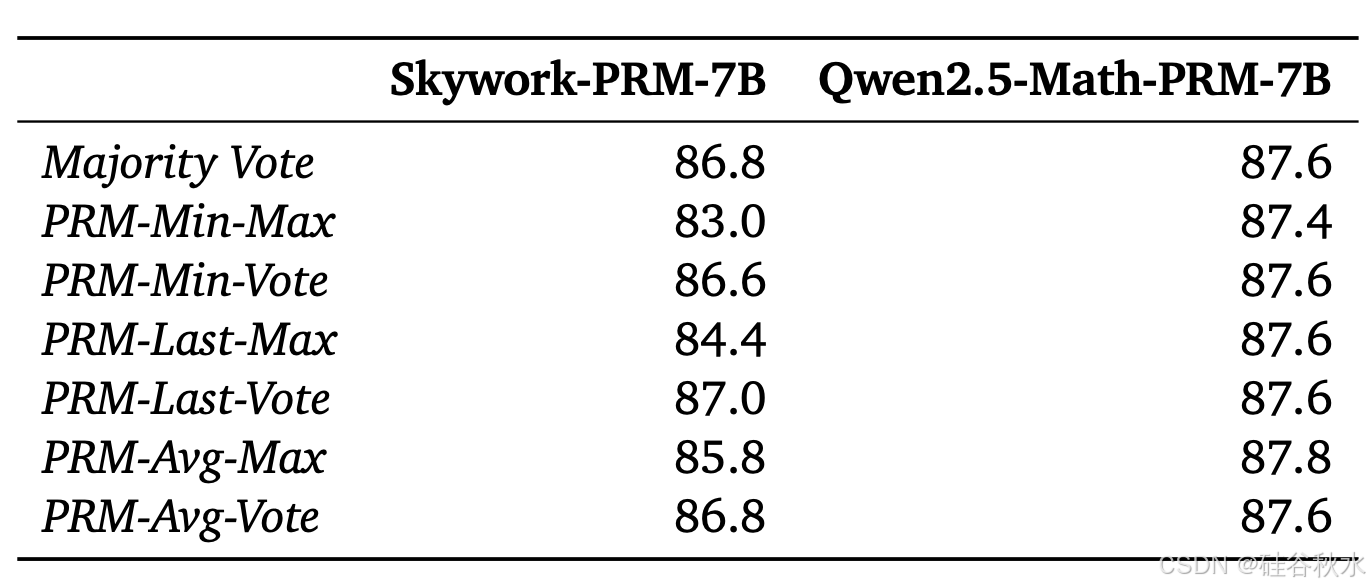
PRMs 对投票方法敏感。从下表的结果可以看出,Skywork-PRM-7B 与 PRM-Vote 配合的效果比与 PRM-Max 配合的效果好,而 Qwen2.5-Math-PRM-7B 对投票方式的敏感度不高。主要原因是 Qwen2.5-Math PRM 的训练数据经过 LLM-as-a-judge 处理(Zheng et al., 2023),去除了训练数据中被错误标记为正步骤的中间步骤,使得输出的大奖励值更有可能是正确的。这说明 PRM 的训练数据对于提高在搜索过程中发现错误的能力很重要。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









