




选择合适的库
目前我学习pyhton的主要目的是读写excel
上周我先后尝试了pandas、openpyxl和xlwings,最后选择了openpyxl。
具体原因如下:
xlwings:这是我最先尝试的库,因为我看了功能对比,这个库支持的功能最全。但他需要本地安装excel或wps,我在个人电脑测试成功后,在单位电脑上由于excel环境的问题折腾了一天没弄好,为避免以后运行的稳定性,所以放弃了。
pandas:这个库支持很多类数据库的操作、统计函数等,比如group by 非常全面而强大,我放弃的原因是,我用不到这些功能。
openpyxl:我在测试pandas时发现它读写excel用的就是openpyxl,这么NB的库都用它,侧面说明了它性能和稳定性。正好只需要最基本的读写功能,数据清理以及结构调整都自己写逻辑,这个库正合适。
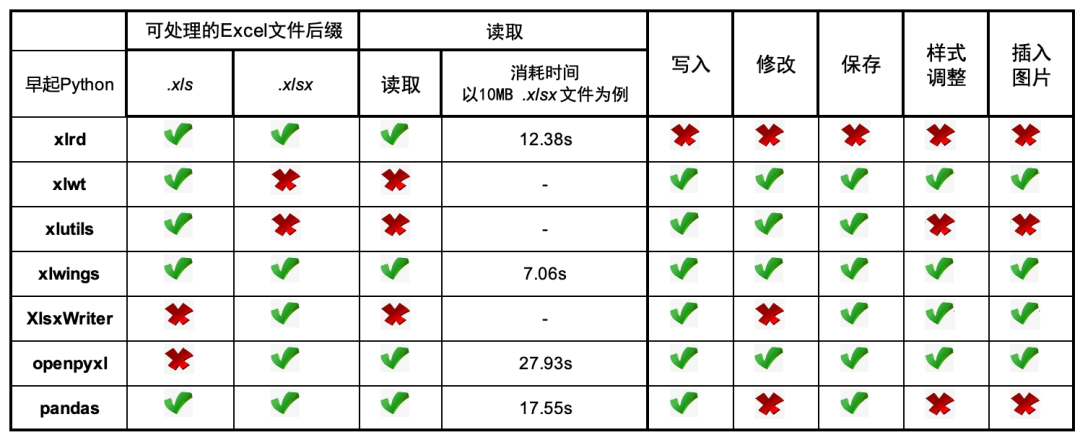
附:我开始选择库时参考的对比图,但实测openpyxl读写是非常快的。
补充一些常用代码
只读方式读取“read_only=True”
from openpyxl import load_workbook
wb = load_workbook(filename='large_file.xlsx', read_only=True)
ws = wb['big_data']
设置读取范围
注意,第一行和第一列的索引都是1
下面的示例是用两种方式取第1-3行的2-4(BCD)列
# 按行获取值
for row in ws.iter_rows(min_row=1, max_row=3, min_col=2,max_col=4):
print(row)
# 按列获取值
for col in ws.iter_cols(min_row=1, max_row=3, min_col=2,max_col=4):
print(col)
创建新文件
import openpyxl
import os
file='XXX.xlsx'
if not os.path.exists(file)
wb = openpyxl.Workbook()
wb.save(file)
wb.close()
删除、新建sheet,写入一行,写入一格
import openpyxl
sheet_name='xxxx.xlsx'
wb = openpyxl.load_workbook(filename=file)
#删除、创建sheet
sheet_name = 'Sheet1'
if sheet_name in wb.sheetnames:
wb.remove(wb[sheet_name])
wb.create_sheet(sheet_name)
else:
wb.create_sheet(sheet_name)
#写入一行
row = ['日期', '机构', '员工', '角色']
wb[sheet_name].append(row)
#写入一格
wb['sheet_name']['A3']=0
wb.save(file)
分享几个自己的函数
把excel用字母表示的列转成自然数表示的列序号
def excel_column_to_number(column):
# 把excel用字母表示的列转成自然数表示的列序号
if not column:
return 0
result = 0
column = column.upper()
for char in column:
if not char.isupper():
raise ValueError("Column must be uppercase letters only.")
result = result * 26 + (ord(char) - ord('A') + 1)
return result
把自然数转成A-Z表示的27进制字符,用于转换成excel列
def number_to_excel_column(n):
# 把自然数转成A-Z表示的27进制字符,用于转换成excel列
result = ''
while n > 0:
n -= 1
remainder = n % 26
current_char = chr(ord('A') + remainder)
result = current_char + result
n = n // 26
return result
把二维数组转成带excel单元格坐标的字典
def array_to_excel_cell(data : list,start_col :str = 'A',start_row :int =1):
start_col = excel_column_to_number(start_col)
sheet_dict = {}
for row_idx, row in enumerate(data):
for col_idx, value in enumerate(row):
current_row = start_row + row_idx
current_col = start_col + col_idx
sheet_dict[f'{number_to_excel_column(current_col)}{current_row}'] = value
'''
# 创建一个新工作簿
wb = openpyxl.Workbook()
# 创建一个新的工作表
wb.create_sheet('NewSheet')
# 定义要写入的数据
data = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9,10]
]
for key,value in array_to_excel_cell(data,5,'d').items():
wb['NewSheet'][f'{key}']=value
wb.save('example.xlsx')
'''
return sheet_dict
代码示例
# 定义要写入的数据
data = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9,10]
]
#从D5这个位置开始写入数组
for key,value in array_to_excel_cell(data,'d',5).items():
wb['NewSheet'][f'{key}']=value
wb.save('example.xlsx')


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









