




 本文介绍了一种预测电商平台上商品定价的方法,通过对商品描述等文本信息进行处理,并结合商品属性如分类、品牌等因素,利用机器学习算法预测商品的价格。
本文介绍了一种预测电商平台上商品定价的方法,通过对商品描述等文本信息进行处理,并结合商品属性如分类、品牌等因素,利用机器学习算法预测商品的价格。
我们通过上章的分析看到高品质,新品,本身昂贵的物品定价可能更高,而且特别的是不包邮的产品定价普遍高于包邮的。
那么一个商品的最终定价与这些客观因素的关联度如何呢?哪些方面更直接影响价格呢?由于不同类别产品价格相差太多,我们先将产品分类。
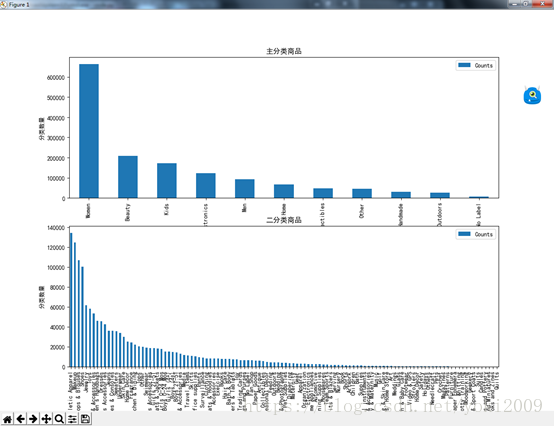
图 商品分类
将原有分类模式 主分类/二级分类/三级分类模式改为独立字段,用来训练使用。
代码:
|
def split_cat(text): try: return text.split("/") except: return ("No Label", "No Label", "No Label") #分三类 def GoodsCatlog(): full_data['general_cat'], full_data['subcat_1'], full_data['subcat_2'] = zip(*full_data['category_name'].apply(lambda x: split_cat(x)))
general_ax = plt.subplot(211) general_data = full_data.groupby('general_cat').size().to_frame('Counts').reset_index().sort_values('Counts',ascending=False) general_data.plot.bar(x='general_cat',y='Counts' ,ax = general_ax) general_ax.set_title("主分类商品") general_ax.set_xlabel("主分类") general_ax.set_ylabel("分类数量") general_ax.legend()
subcat_1_ax = plt.subplot(212) sub1_data = full_data.groupby('subcat_1').size().to_frame('Counts').reset_index().sort_values('Counts',ascending=False) sub1_data.plot.bar(x='subcat_1',y='Counts',ax = subcat_1_ax) subcat_1_ax.set_title("二分类商品") subcat_1_ax.set_xlabel("二分类") subcat_1_ax.set_ylabel("分类数量") subcat_1_ax.legend()
# subcat_2_ax = plt.subplot(313) # sub2_data = full_data.groupby('subcat_2').size().to_frame('Counts').reset_index().sort_values('Counts',ascending=False) # sub2_data.plot.bar(x='subcat_2',y='Counts', ax = subcat_2_ax) # subcat_2_ax.set_title("三分类商品") # subcat_2_ax.set_xlabel("三分类") # subcat_2_ax.set_ylabel("分类数量") # subcat_2_ax.legend()
#plt.show() print (sub1_data.head()) full_data.to_csv('subcate.csv') |
新的训练字段如下图,现在需要思考的是是如何将name,item_descption两个字段进行预处理来达到可以进行训练目的。
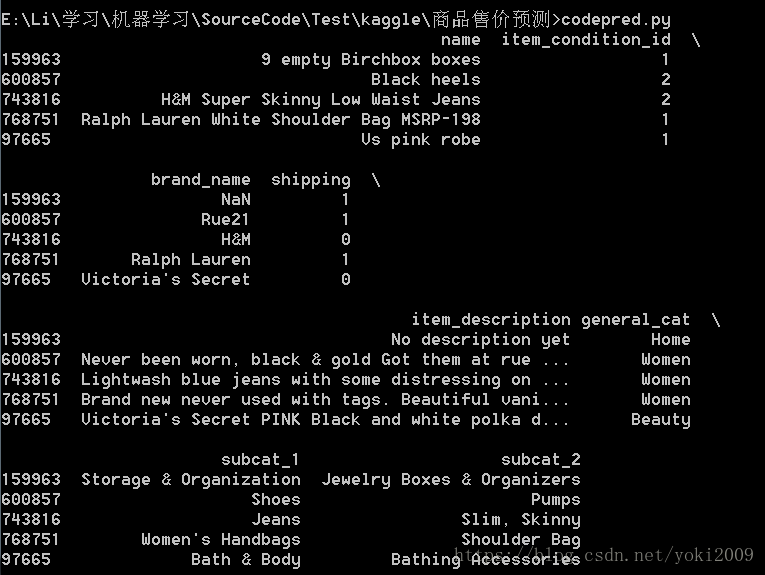
这里我的思路是将item_description字段按照文本进行处理,将其每个出现的词提炼出来组合成一个数字序列,先对使用item_description和目标价格进行一个模型预测,将每个item_description都替换成预测的Price值,形成新的数据集,这样做的好处是模拟了boostrap的方式,我们用两层预测来完成最后对Price的预估。
新数据集实现代码:
|
full_data['item_description'].fillna("No description yet",inplace=True) full_data['name'].fillna('0',inplace=True) full_data['brand_name'].fillna('0',inplace=True) full_data['general_cat'].fillna('0',inplace=True) full_data['subcat_1'].fillna('0',inplace=True) full_data['subcat_2'].fillna('0',inplace=True) full_data['shipping'].fillna(0,inplace=True) full_data['item_condition_id'].fillna('0',inplace=True)
stop_words = text.ENGLISH_STOP_WORDS.union(["[rm]"])
tv = TfidfVectorizer(stop_words=stop_words, ngram_range=(1, 2))
item_desc = tv.fit_transform(list(full_data['item_description']))
#综合回归梯度下降 from sklearn.ensemble import GradientBoostingRegressor gbr = GradientBoostingRegressor() gbr.fit(item_desc,full_data['price'])
gbr_y_pred = gbr.predict(item_desc) full_data['item_description'] = pd.Series(gbr_y_pred) full_data['item_description'].fillna(full_data['item_description'].mean(),inplace=True)
train_col = ['name','item_condition_id','brand_name','shipping','item_description','general_cat','subcat_1','subcat_2'] target_col = ['price'] full_data_col = train_col + target_col
from sklearn.model_selection import train_test_split
full_data = full_data[full_data_col] full_data[target_col] = np.log1p(full_data[target_col])
train_x,test_x,train_y,test_y = train_test_split(full_data[train_col],full_data[target_col])
le = preprocessing.LabelEncoder() train_x['name'] = le.fit_transform(train_x['name']).astype(float) train_x['brand_name'] = le.fit_transform(train_x['brand_name']).astype(float) train_x['general_cat'] = le.fit_transform(train_x['general_cat']).astype(float) train_x['subcat_1'] = le.fit_transform(train_x['subcat_1']).astype(float) train_x['subcat_2'] = le.fit_transform(train_x['subcat_2']).astype(float) train_x['item_condition_id'] = le.fit_transform(train_x['item_condition_id']).astype(float)
|
使用XGB进行预测
|
# #XGB from xgboost import XGBRegressor
xported_pipeline = XGBRegressor(learning_rate=0.1, max_depth=2, min_child_weight=6, n_estimators=100, nthread=1, subsample=0.9000000000000001)
exported_pipeline.fit(train_x, train_y) results = exported_pipeline.predict(test_x) print (results) |

















 4662
4662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









