






url = 腾讯网
1.找出数据所在包 由于是异步加载进入Fetch/XHR栏下寻找 可以通过下滑观察新增响应报文
不难发现 我们需要的数据在 getHotModuleList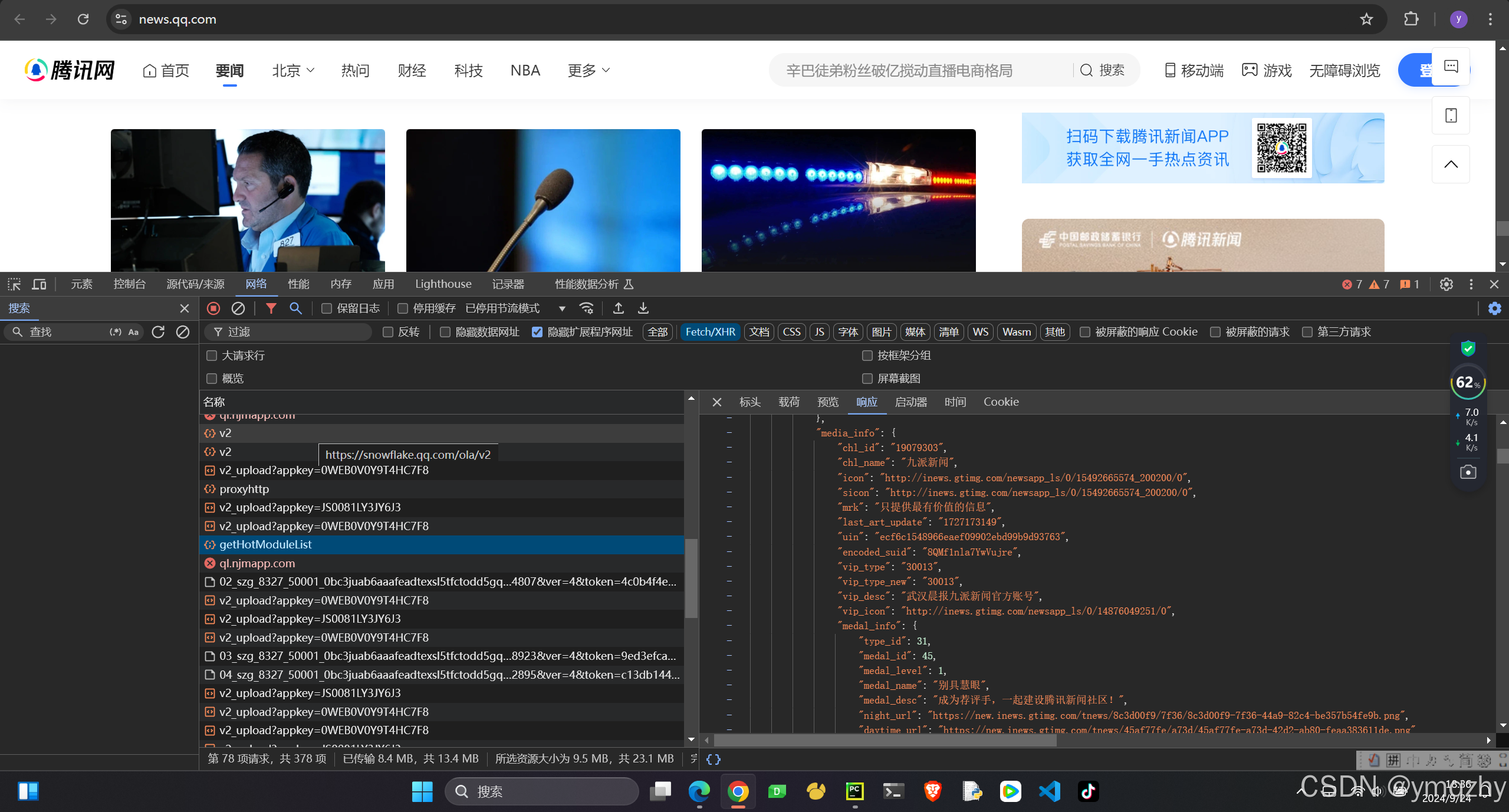
2.我们进入标头
发现是post请求 于是我们进入载荷查看需要携带的参数
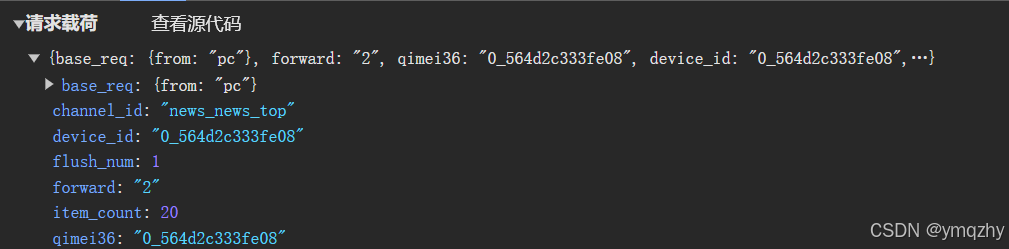
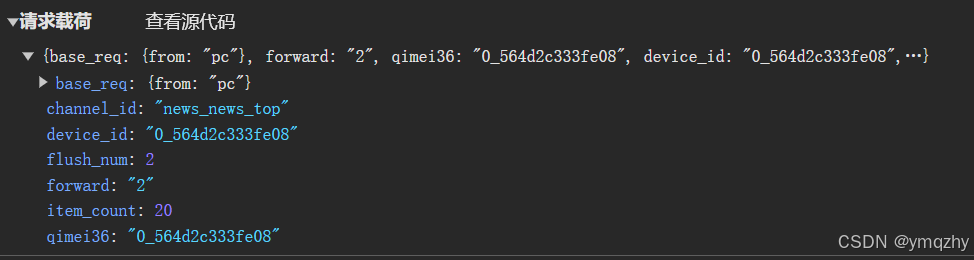 我们会发现仅有flush_num不同而这个恰恰是我们翻页需要变的参数
我们会发现仅有flush_num不同而这个恰恰是我们翻页需要变的参数
(没有js加密)
我们此次爬取要闻的title,url,来源
仅需要用到jsonpath就可以轻松获取(因为数据是以json文档形式响应的)
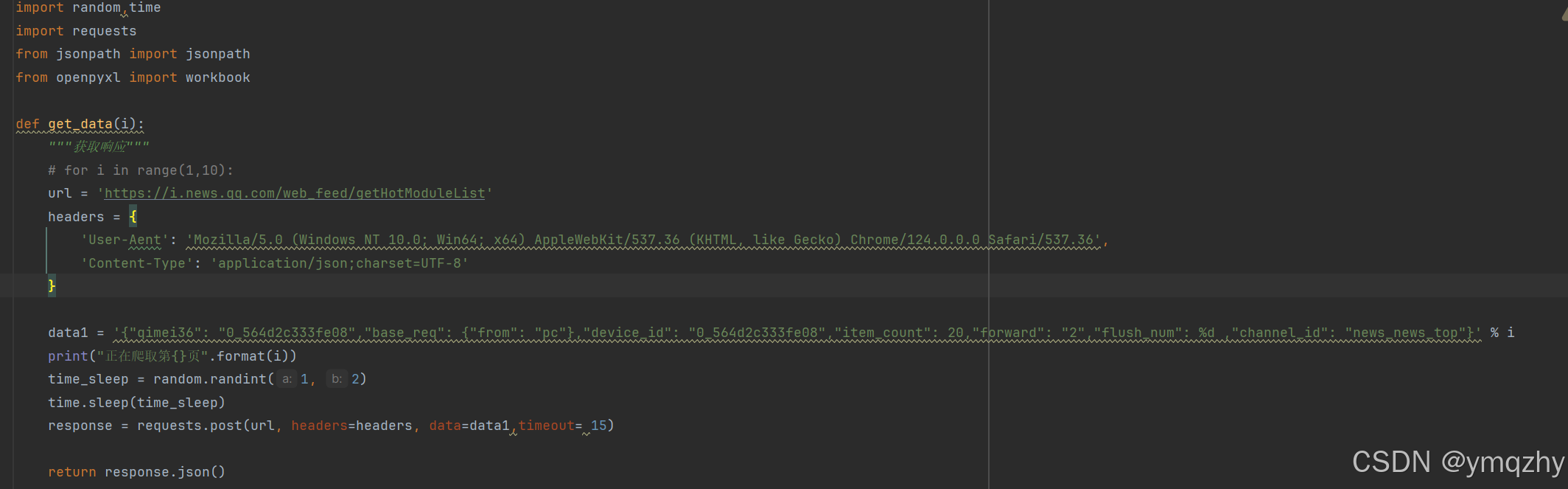
我们正常向网页发送请求 携带载荷里的参数
将获取到的数据以json形式返回给解析数据的函数
防止数据没有来源造成异常报错 如果没有来源直接用无代替 保证需要获取的三个数据类长度都相同
这里使用openpyxl库中的workbook模块保存数据
import random,time
import requests
from jsonpath import jsonpath
from openpyxl import workbook,load_workbook
def get_data(i):
"""获取响应"""
# for i in range(1,10):
url = 'https://i.news.qq.com/web_feed/getHotModuleList'
headers = {
'User-Aent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',
'Content-Type': 'application/json;charset=UTF-8'
}
data1 = '{"qimei36": "0_564d2c333fe08","base_req": {"from": "pc"},"device_id": "0_564d2c333fe08","item_count": 20,"forward": "2","flush_num": %d ,"channel_id": "news_news_top"}' % i
print("正在爬取第{}页".format(i))
time_sleep = random.randint(1, 2)
time.sleep(time_sleep)
response = requests.post(url, headers=headers, data=data1,timeout= 15)
return response.json()
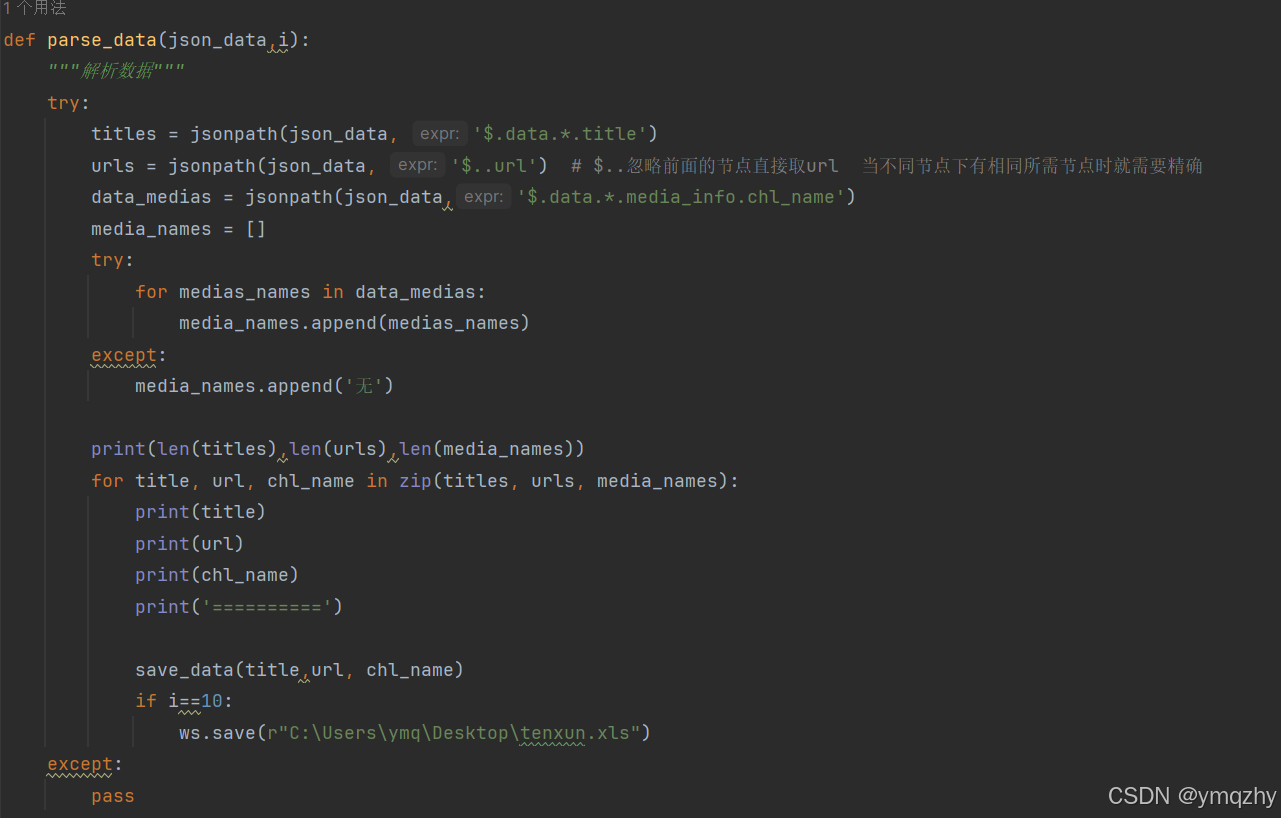
def parse_data(json_data,i):
"""解析数据"""
try:
titles = jsonpath(json_data, '$.data.*.title')
urls = jsonpath(json_data, '$..url') # $..忽略前面的节点直接取url 当不同节点下有相同所需节点时就需要精确
data_medias = jsonpath(json_data,'$.data.*.media_info.chl_name')
media_names = []
try:
for medias_names in data_medias:
media_names.append(medias_names)
except:
media_names.append('无')
print(len(titles),len(urls),len(media_names))
for title, url, chl_name in zip(titles, urls, media_names):
print(title)
print(url)
print(chl_name)
print('==========')
save_data(title,url, chl_name)
if i==10:
ws.save(r"C:\Users\ymq\Desktop\tenxun.xls") 这里的保存路径一定要改成自己的哦
# wb = load_workbook(r"C:\Users\ymq\Desktop\tenxun.xls")
# wt = wb[wb.sheetnames[0]]
# wt.column_dimensions['A'].width = 70
# ws.save(r"C:\Users\ymq\Desktop\tenxun.xls")
except:
pass
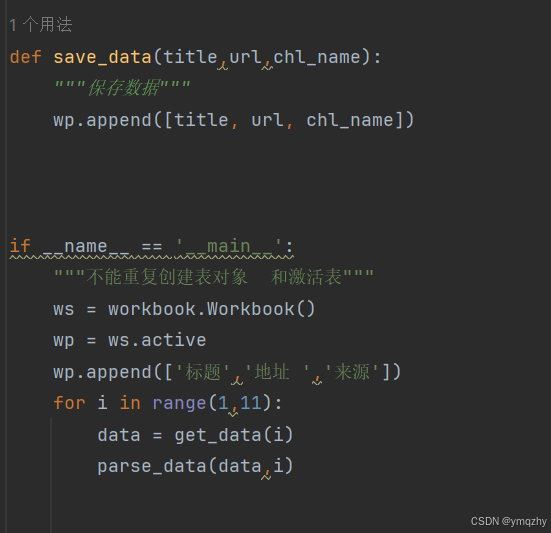
def save_data(title,url,chl_name):
"""保存数据"""
wp.append([title, url, chl_name])
if __name__ == '__main__':
"""不能重复创建表对象 和激活表"""
ws = workbook.Workbook()
wp = ws.active
wp.append(['标题','地址 ','来源'])
for i in range(1,11):
data = get_data(i)
parse_data(data,i)
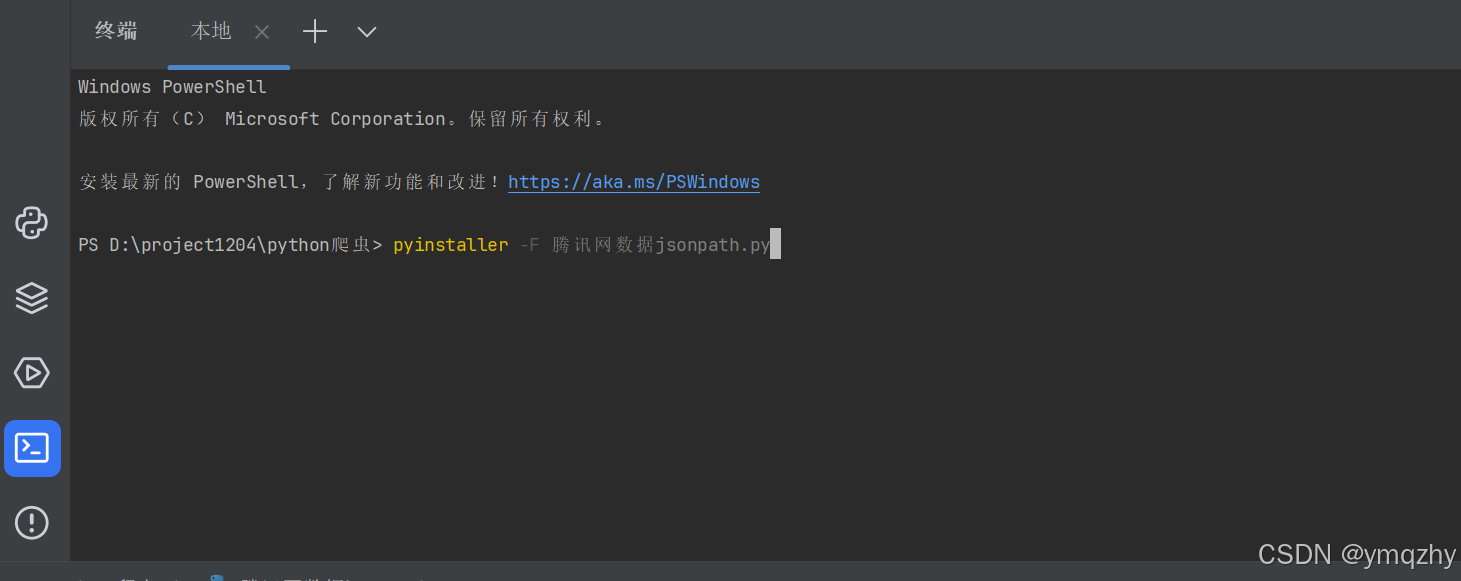
我们也可以将其打包成exe文件
在控制台输入pyinstaller -F 文件名.py(提前下载哦)
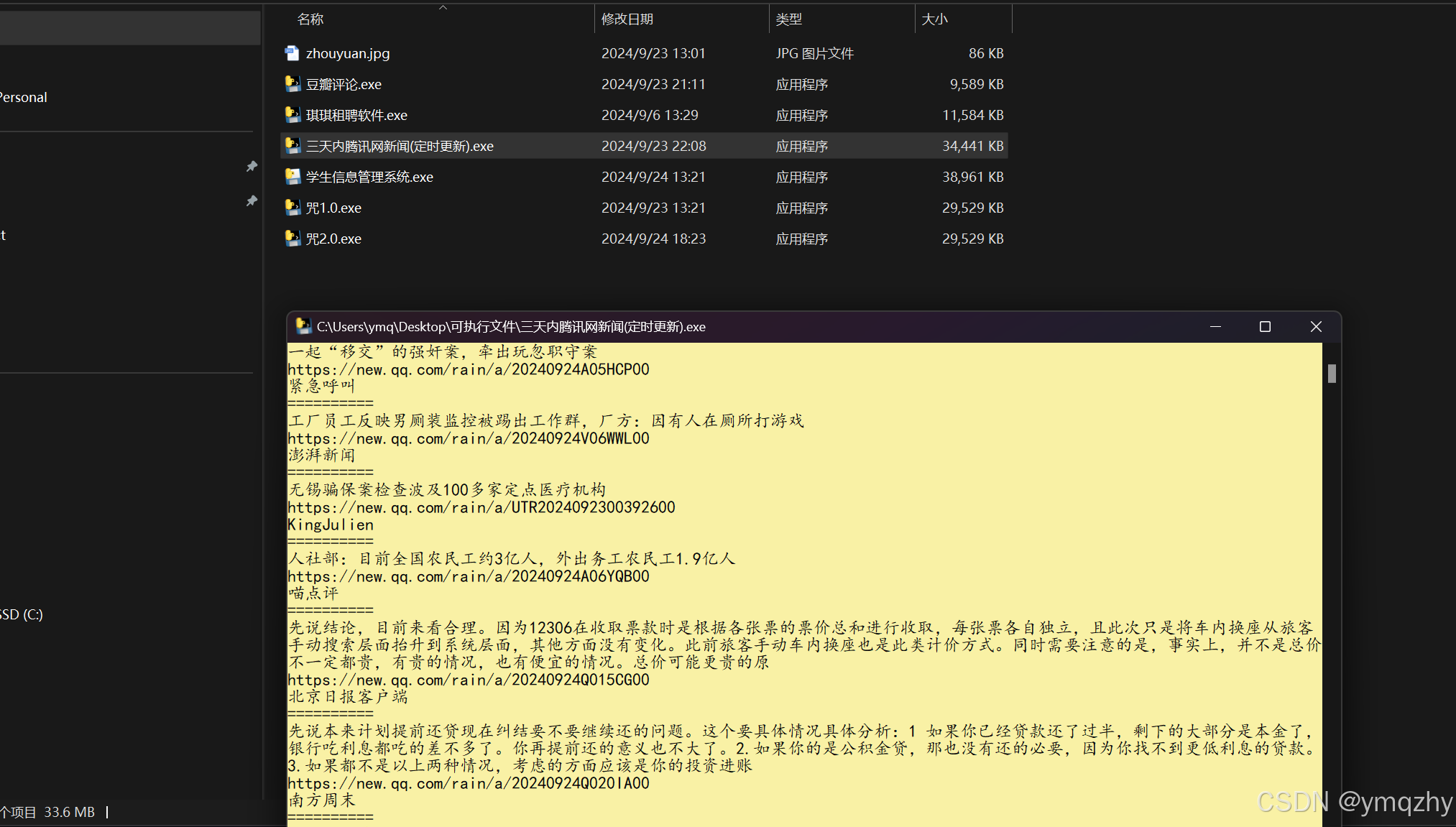
结束后桌面会出现一个xls表格
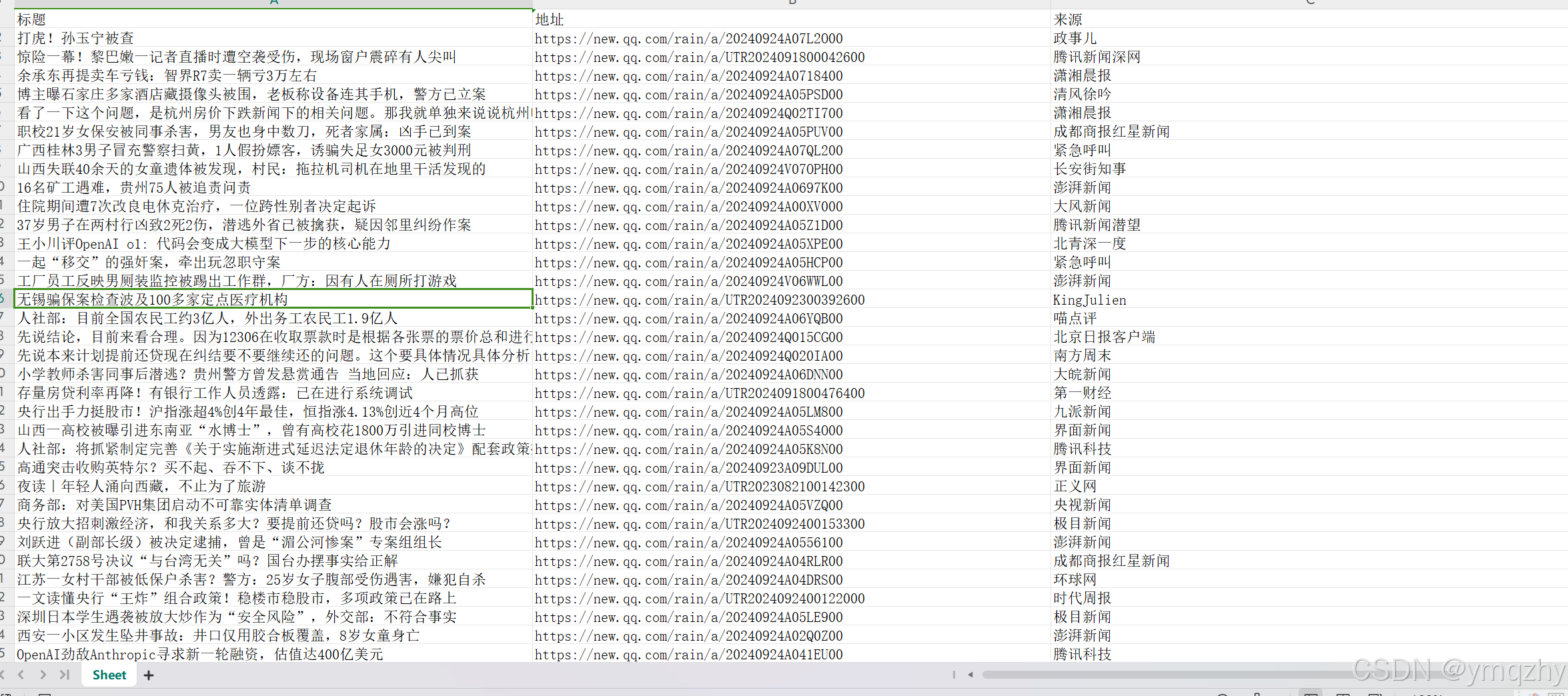

















 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









