








 超级会员免费看
超级会员免费看

引言
这是GPT系列的第二篇文章。在上篇文章中我们实现了GPT1并训练了一个小说生成器。
今天我们尝试实现GPT2来完成小说生成这件事。
模型架构
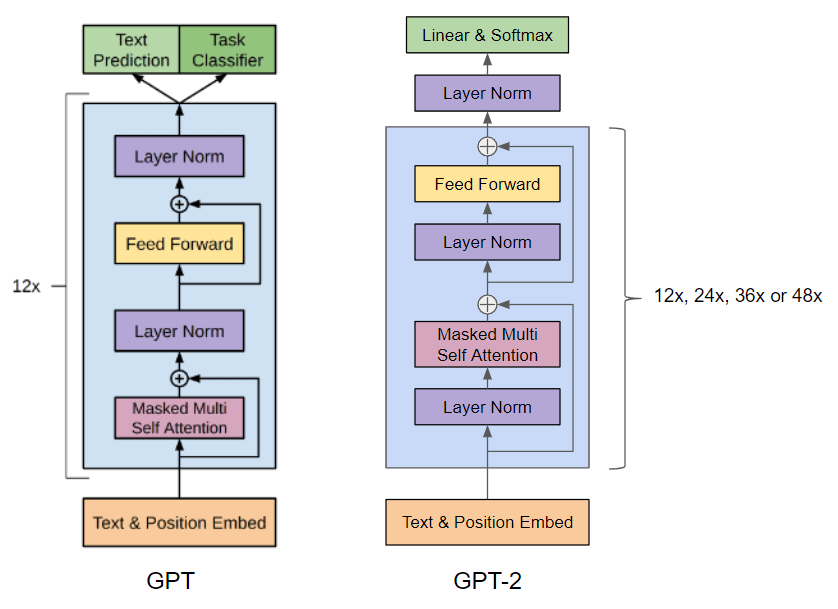
GPT2很大程度上遵循了GPT-1的细节,但做了一些优化/修改:
- 层归一化被移动到每个子块(sub-block)的输入处(Pre-LN);
- 在最后一个块之后添加了一个额外的层归一化;
- 使用了一种修改后的初始化方法,考虑了模型深度上残差路径的累积。在初始化时,将残差层的权重缩放因子设置为 1 / N
这是GPT系列的第二篇文章。在上篇文章中我们实现了GPT1并训练了一个小说生成器。
今天我们尝试实现GPT2来完成小说生成这件事。
GPT2很大程度上遵循了GPT-1的细节,但做了一些优化/修改:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























