









往期内容看了看多模态RAG在文档问答上的相关内容及简单实践:
本文单独来看看检索部分的多模态嵌入部分。
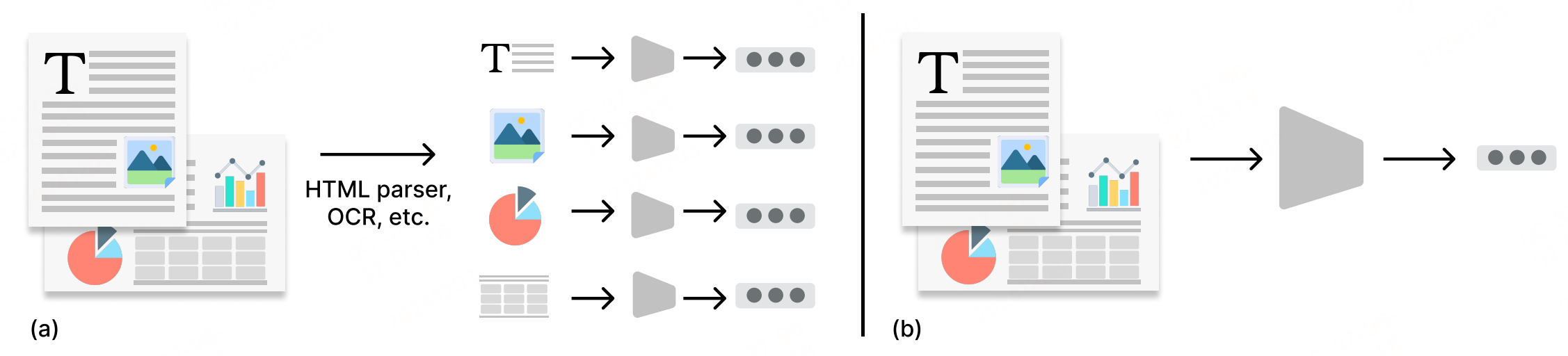
局限性:
现有的检索范式缺乏跨模态的统一编码过程,导致两个问题:
-
预处理工作繁琐:需要专门的处理来应对各种文档类型和内容模态,而这些处理往往不完美。例如,HTML文件由于其多样的结构,复杂性较高,使得单一工具难以准确解析所有信息。同样,ppt和PDF通常需要OCR模型来提取文本并分别处理其他内容类型,如表格和图表。处理这些长尾问题较为复杂。
-
破坏文档原始布局信息:解析过程可能导致文档布局信息丢失。文档的视觉呈现可以传达通过内容提取难以捕捉的关键信息。例如,除了文本和图像的内容外,这些元素在文档中的大小和位置可能编码了一些信息。
解决手段:提出了文档截图嵌入(Document Screenshot Embedding, DSE),将不同格式和模态的文档统一为一种形式进行直接文档编码和索引:截图。与使用各种工具从不同格式的文档中提取文本和图像不同,截图易于获取并且文档的所有信息在视觉上都得到了保留。如上图(b)所示,DSE将给定文档的截图进行embedding。
方法
文档检索任务的任务定义:给定一个查询 Q Q Q 和一个包含文档 { D 1 , D 2 , … , D n } \{D_1, D_2, \ldots, D_n\} {D1,D2,…,Dn} 的语料库 C C C,任务是识别出与查询 Q Q Q 最相关的 k k k 个文档,其中 k ≪ n k \ll n k≪n。相关性是通过相似性度量 S i m ( Q , D ) ∈ R Sim(Q, D) \in R Sim(Q,D)∈R 来确定的。
文档截图embedding
采用双编码器架构进行密集检索,其中文档截图和用户文本查询分别通过视觉编码器和文本编码器编码成密集向量。
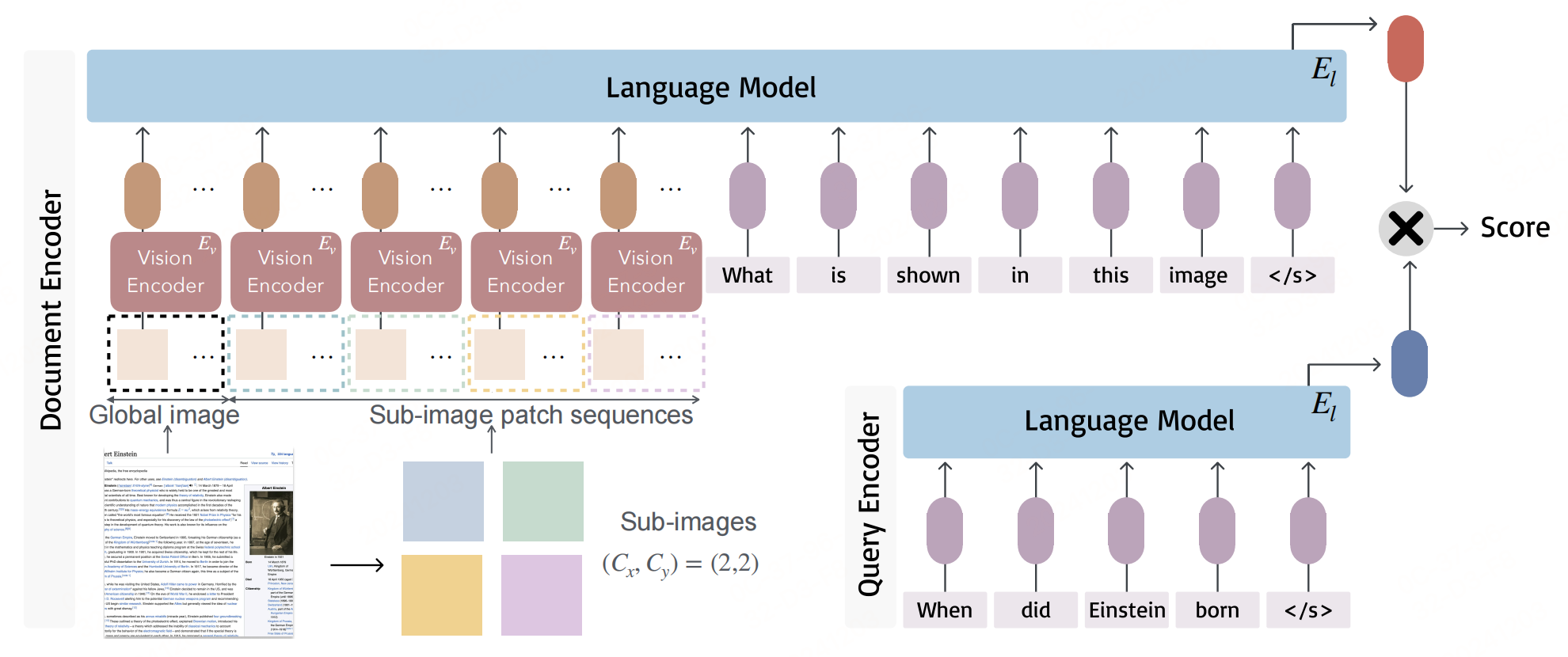
视觉编码器
一个文档截图 D D D ,首先由视觉编码器 E v E_v Ev 处理,生成隐藏层表示。序列的长度由视觉编码器的图像tokenizer决定。以 clip-vit-large-patch14-336l 为例,任何给定的截图首先转换为 336 × 336 336 \times 336 336×336 像素的图像,然后分成 24 × 24 24 \times 24 24×24 个块(即总共 576 个块),每个块由 14 × \times × 14 像素组成。每个块展平并通过可训练的线性投影映射到块嵌入。块嵌入由视觉编码器编码成隐藏层表示。但是,如果截图包含大量文本(例如维基百科网页),576 个块的潜在嵌入可能无法捕捉截图中的细粒度文本信息。
视觉-语言模型
为了视觉编码器中的问题,利用多模态大模型 Phi-3-vision,其使用与 clip-vit-large-patch14-336 相同的图像tokenizer,但可以通过将图像裁剪成子图像来表示更多的块。例如,给定一个截图,可以选择将其分成 ( C x × 24 ) × ( C y × 24 ) (Cx \times 24) \times (Cy \times 24) (Cx×24)×(Cy×24) 个块。给定的截图转换为 ( C x × 336 ) × ( C y × 336 ) (Cx \times 336) \times (Cy \times 336) (Cx×336)×(Cy×336) 像素的图像,并裁剪成 C x × C y Cx \times Cy Cx×Cy 个子图像,每个子图像有 336 × 336 336 \times 336 336×336 像素。同样,每个子图像独立编码成 576 个块潜在表示。在这里,Phi-3-vision 进一步将整个截图转换为 336 × 336 336 \times 336 336×336 像素,并编码成额外的 576 个块潜在表示以捕捉全局信息,总共生成 ( C x × C y + 1 ) × 576 (Cx \times Cy + 1) \times 576 (Cx×Cy+1)×576 个块潜在表示,如上图中左侧所示。此外,每四个块潜在表示连接并投影成一个嵌入,作为语言模型输入。这个过程产生 ( C x × C y + 1 ) × 576 4 (Cx \times Cy + 1) \times \frac{576}{4} (Cx×Cy+1)×4576 个块潜在嵌入作为语言模型 E l E_l El 的输入。
编码后的块潜在嵌入与文本提示一起作为后续语言模型的输入:“< s> What is
shown in this image?</ s>”。这里,
<
i
m
g
>
< img>
<img> 是一个特殊的占位符标记,被视觉编码器的块潜在嵌入序列替换。为了使用具有单向注意力的语言模型聚合序列信息,使用最后一个隐藏状态的序列标记
<
/
s
>
< /s>
</s> 的嵌入作为文档截图嵌入:
V d = E l ( E v ( D ) , prompt ) [ − 1 ] V_d = E_l(E_v(D), \text{prompt})[-1] Vd=El(Ev(D),prompt)[−1]
对比学习
query和文档之间的相似性通过embedding之间的余弦相似度计算:
Sim ( Q , D ) = V q ⊤ V d ∥ V q ∥ ⋅ ∥ V d ∥ \operatorname*{Sim}(Q, D) = \frac{V_q^\top V_d}{\|V_q\| \cdot \|V_d\|} Sim(Q,D)=∥Vq∥⋅∥Vd∥Vq⊤Vd
在训练期间,embedding模型使用 InfoNCE 损失进行优化:
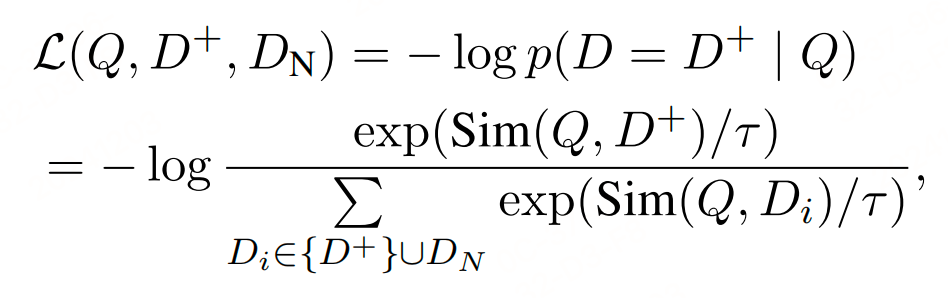
其中 D + D^+ D+ 表示正文档, D N D_N DN 表示与查询 Q Q Q 无关的一组负文档,包括难负样本和批次内负样本。 τ \tau τ 是在实验中设置为 0.02 的温度参数。此时只考虑文本查询,它们直接使用模板 f“< s>{query}< /s>” 输入到语言模型中, < / s > < /s> </s> 的最后一个隐藏状态作为query嵌入, V q = E l ( Q ) [ − 1 ] V_q = E_l(Q)[-1] Vq=El(Q)[−1]。
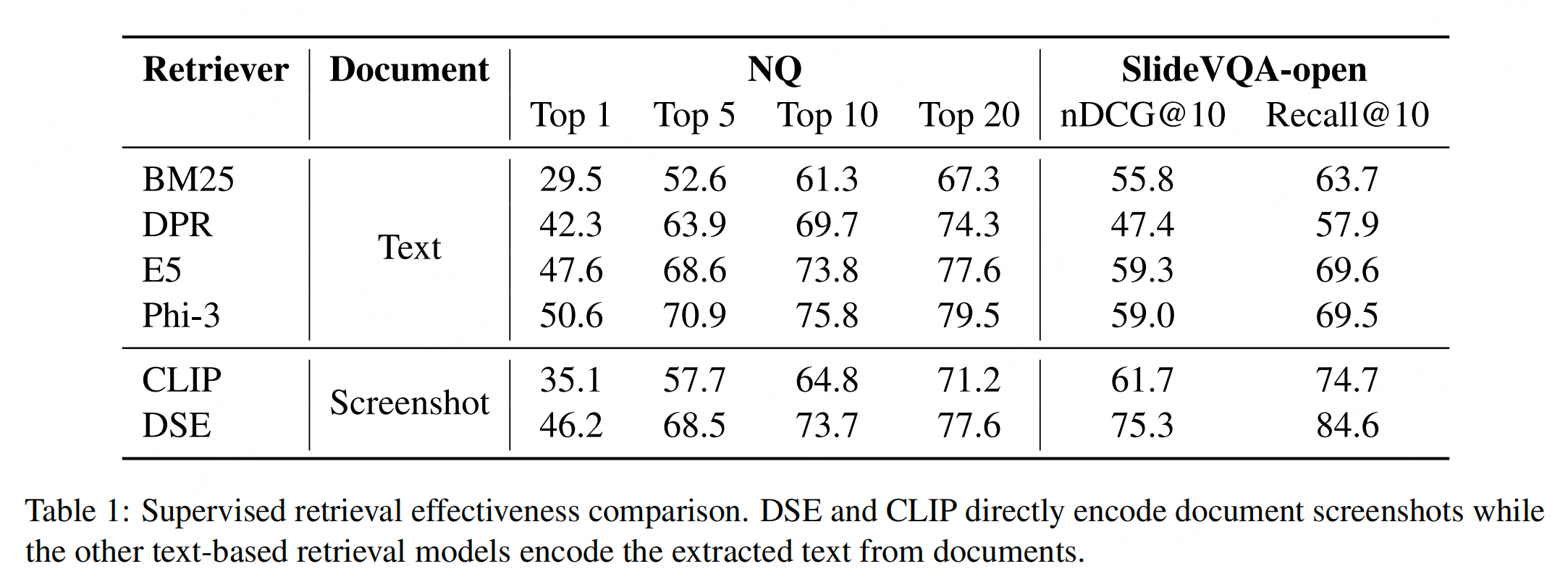
实验
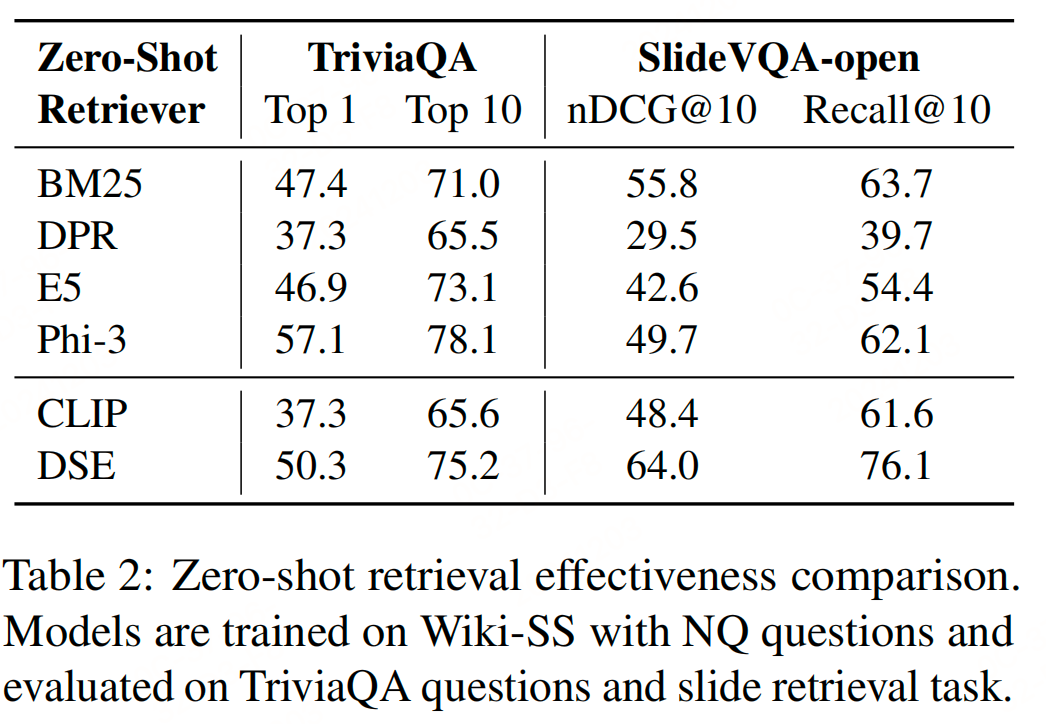

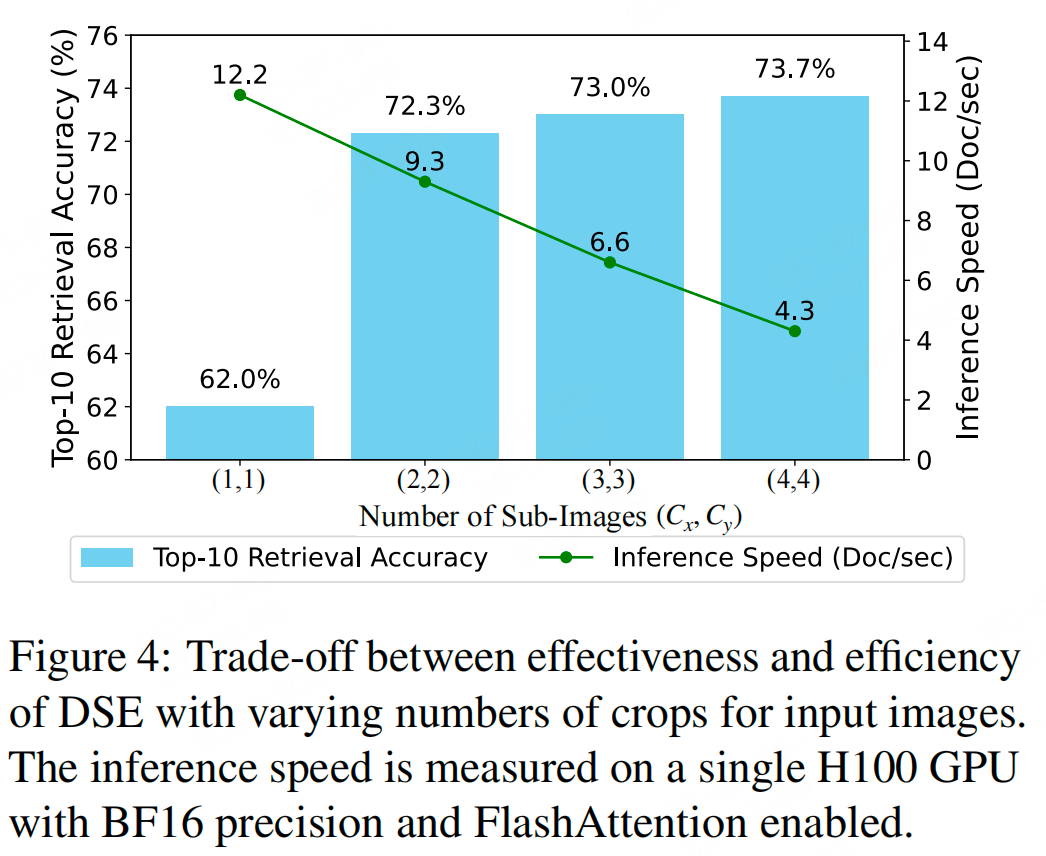
参考文献
Unifying Multimodal Retrieval via Document Screenshot Embedding,https://arxiv.org/pdf/2406.11251


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









