



Policy Gradient到TRPO再到PPO,我们可以看出强化学习方法的演化逻辑:
- Policy Gradient重在“可行性”,为强化学习提供了一种端到端优化策略的框架;
- TRPO则更注重理论上的“稳定性”,为策略优化提供了一个严格的数学基础;
- PPO则追求“效率”,在工业实践中找到了理论与实用的最佳平衡点。
一、Policy Gradient
在Policy Gradient方法中,核心思想是通过直接优化策略 πθ(a|s) 的参数 θ,最大化累积回报。它的优化目标是:
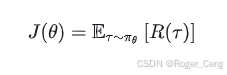
这里,R(τ) 表示一条轨迹 τ 的累积奖励。通过策略梯度定理,我们可以将目标函数的梯度写为:
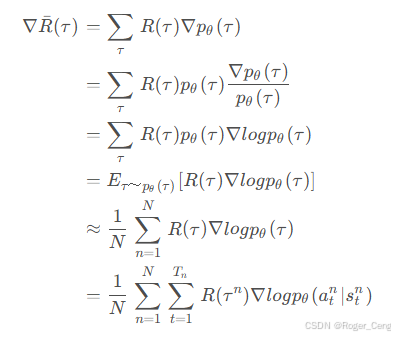
公式中的每一部分都很直观:logπθ 提供方向,R(τ) 衡量优劣。然而,这种方法直接依赖采样,噪声较大,收敛速度较慢。
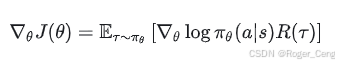
Policy Gradient简单直观,但有两个关键问题:
- 更新步长过大:梯度优化可能导致策略分布发生剧烈变化,甚至丧失现有策略的优点。
- 样本效率低:由于直接采样,许多样本的利用率很低。
二、TRPO
在尽量小的策略更新范围内,稳步提升策略的表现。引入了信任域(trust region),限制新策略和旧策略之间的“距离”。距离用KL散度来衡量。
![]()
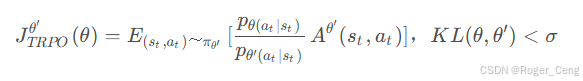
TRPO相当于给目标函数增加了一项额外的约束(constrain),而且这个约束并没有体现在目标函数里,在计算过程中这样的约束是很难处理的。PPO的做法就是将这样约束融进了目标函数
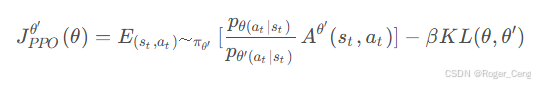
优势函数的引入:重要性采样(Importance Sampling)--->比较优势函数引入
1.设置基线Baseline b
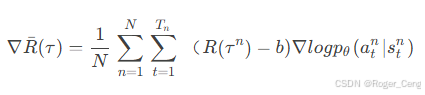
![]()
![]()
2.设置合适权重
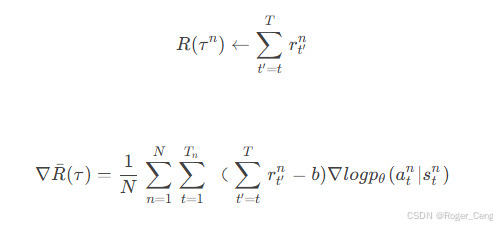
引入一个discount factor(衰减因子) γ , γ ∈ [ 0 , 1 ]
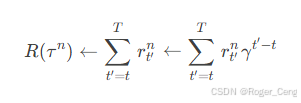
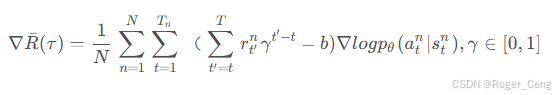
定义R-b为优势函数,表示为
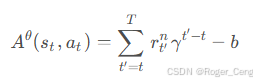
优势函数由网络估计“critic”。
3.推导off-policy(异智能体策略)的梯度公式


调试说明:

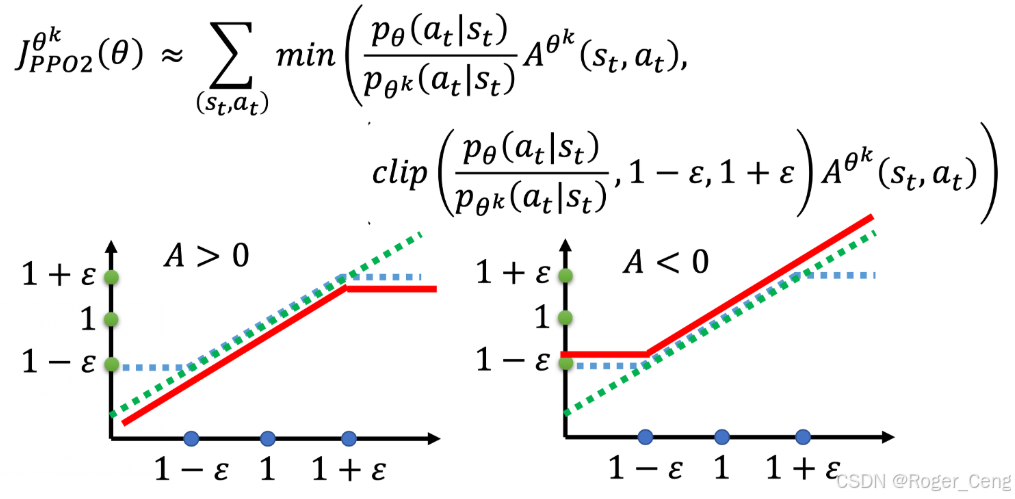
三、PPO-Clip
不采用KL散度作为约束,而是采用逻辑上合理的思路设计目标函数
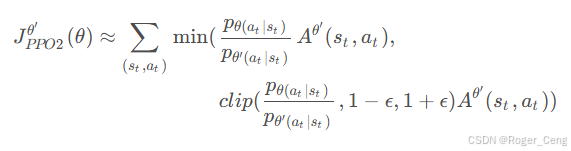
clip函的括号里面有三项,分别是(变量,下限,上限),如果变量小于下限,那么就输出下限,大于上限就输出上限,如果在二者之间,就输出变量的值
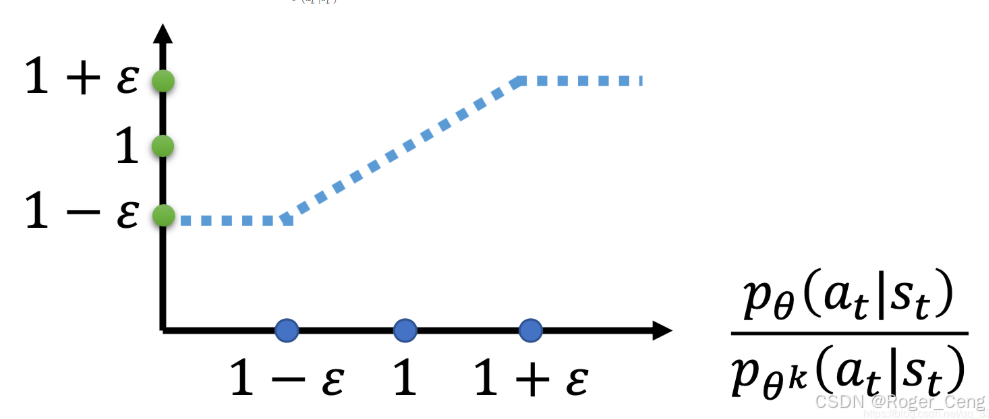
函数的取值逻辑:



















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









