



 本文深入探讨了快速排序和堆排序的原理与实现,包括partition过程、随机快排、堆的建立与调整,以及这两种排序算法的复杂度分析。
本文深入探讨了快速排序和堆排序的原理与实现,包括partition过程、随机快排、堆的建立与调整,以及这两种排序算法的复杂度分析。
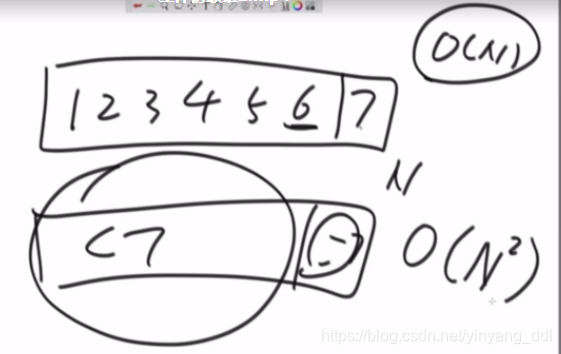
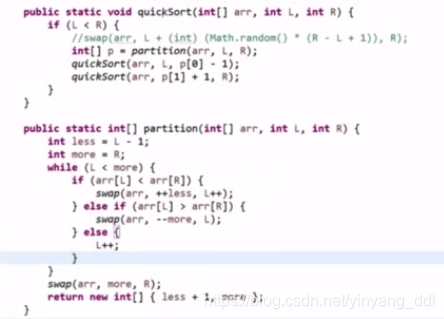
partition的快排:首先保留最后一个数,然后以这个数作为比较数,进行partition。
partition有三个指针,分别是less,more,current
less初始位于-1处
more初始位于7处
current从左至右遍历
if(current<比较数)
swap(current++,++less)
注:
++a表示取a的地址,增加它的内容,然后把值放在寄存器中;
a++表示取a的地址,把它的值装入寄存器,然后增加内存中的a的值;(也就是说操作的时候用到的都是寄存器里面的值,即自增前的值)
最坏情况:
1234567
7654321
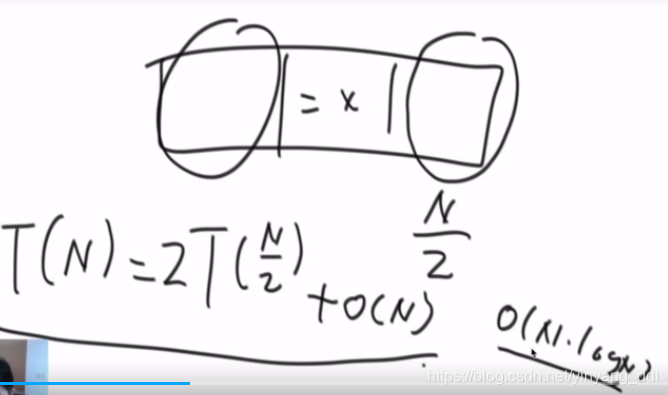
除了子过程,再加一个partition的过程
与数据状况有关,与划分节点的位置有关,对称最好,不对称最差
改进:随机快排,复杂度是一个概率事件,用期望计算复杂度:O(N*logN)
绕开原始数据状况:随机/哈希
每次排好一个或几个
代码简洁,说明常数项很低
随即快排:被大量使用,额外空间复杂度O(logN)(划分点,记录断点,以而为底/长期期望值如此)
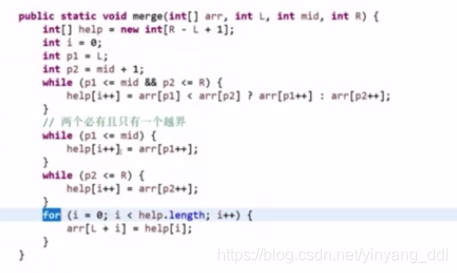
归并排序:O(N*logN)(上)
排序的稳定性?
堆排序:
堆-先讲:完全二叉树(不是满二叉树,新的一层(叶节点)从左向右补满)
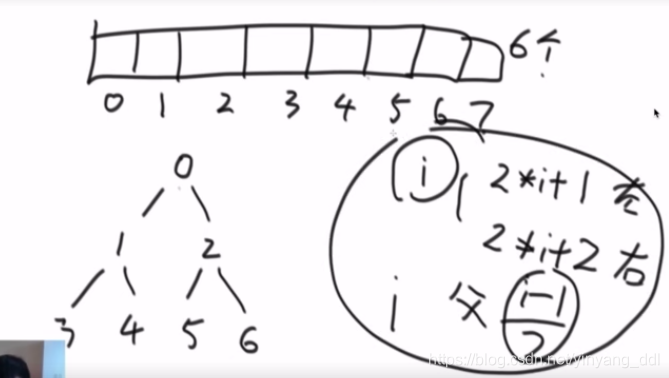
逻辑概念上的完全二叉树
堆:大根堆-完全二叉树,任何一颗子树的头部,都是这个子树的最大值
小根堆,反之
大根堆、小根堆的建立过程

复杂度估算:建立一个大根堆完全二叉树的时间复杂度,每一个节点O(logN),总体O(N)
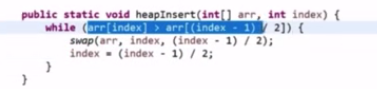
heapinsert:加入同时向上调整
heapify:下沉
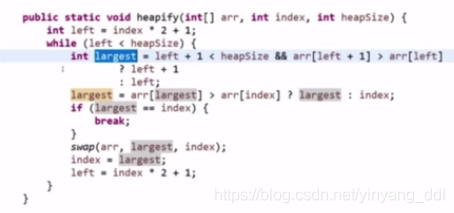
减堆操作:弹出堆顶,最后的数与堆顶交换,再headify,重新变成大根堆
掌握堆的爽的一点:数据流,找已进数据流的中位数(小根堆上“大”部分N/2,小根堆“小”部分N/2,堆大小插值超过1,弹出进入对方,因为要计算中位数
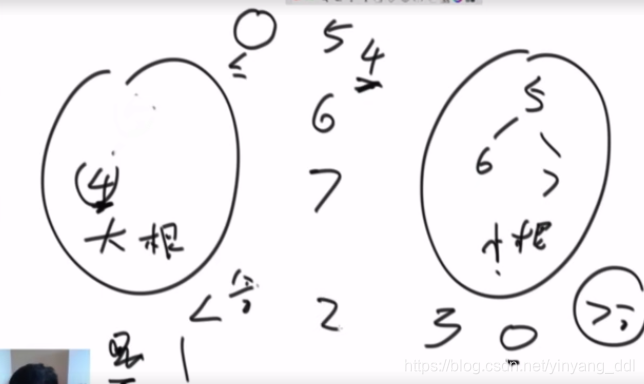
堆排序:头尾交换,斩尾,headify,牛逼!,大根堆
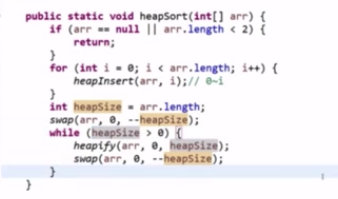
堆很重要,堆排序更重要,很多贪心问题,创建堆O(N)(logN求和积分出来),插入堆O(logN)
搞定所有code!

















 2001
2001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









