




前段时间玩塞尔达传说荒野之息,其中释放三大技能的场景扫描效果很实用,其中涉及到一个深度图的原理及应用,下面我们先了解一下深度图的意义。
我们知道渲染流程中顶点变换过程,其中建模到世界到视口到裁剪到ndc这几个空间变换过程中,在视口空间就产生了z值,也就是顶点到camera的距离值,而这个z值在ndc空间中则变成了包含8bit的数值,当然我们也可以进行归一化了。而引擎一般都提供我们直接获取当前渲染场景这一帧的每个像素的深度信息,因为为了访问存储的便利性,所以和帧画幅一样创建一张名为深度图的贴图进行储存。顺便说一下,一般只适用RGBA四通道的R通道进行z值储存就行了。
如果我们长期坚持写shader,那么我们也就知道一般shader中texture全部都是用来储存信息的,或者换句话说,shader中涉及到大量数据引用传递都会使用texture,一方面是texture根据像素分量可以储存很大的数据量(比如512*512*RGB(3byte)),另一方面tex2D这种高效率的texture采样函数可以快速方便将其中数据进行提取。所以场景深度信息使用texture进行存储和tex2D采样提取就变得非常实用。
下面来看下unity如何进行深度图提取,c# shader代码如下:
using UnityEngine;
public class DepthTex : MonoBehaviour
{
public Material mEffectMaterial;
private Camera mMainCamera;
void Start()
{
//直接可以设置camera的rt为depthtexture类型,然后进行depth贴图数据传递
mMainCamera = GetComponent<Camera>();
mMainCamera.depthTextureMode = DepthTextureMode.Depth;
}
private void OnRenderImage(RenderTexture source, RenderTexture destination)
{
Graphics.Blit(source, destination, mEffectMaterial);
}
}
Shader "Unlit/DepthShader"
{
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float4 uv : TEXCOORD0;
};
struct v2f
{
float4 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
};
//unity方便我们直接使用_CameraDepthTexture接受场景camera提供的深度图
sampler2D _CameraDepthTexture;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
//顶点经过mvp变换后,在计算在屏幕中的坐标参数,如xy的w化数值
//这个计算不理解的可以查看屏幕空间相关计算
o.uv = ComputeScreenPos(o.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
//对深度图进行采样,会发现只有R通道储存深度信息
fixed4 col = tex2D(_CameraDepthTexture,i.uv.xy / i.uv.w);
return col;
}
ENDCG
}
}
}
然后运行可以观察到屏幕后期效果变成了这样,一张R通道的深度图,如下:

观察framedebugger中的原始深度图也是一样,如下:
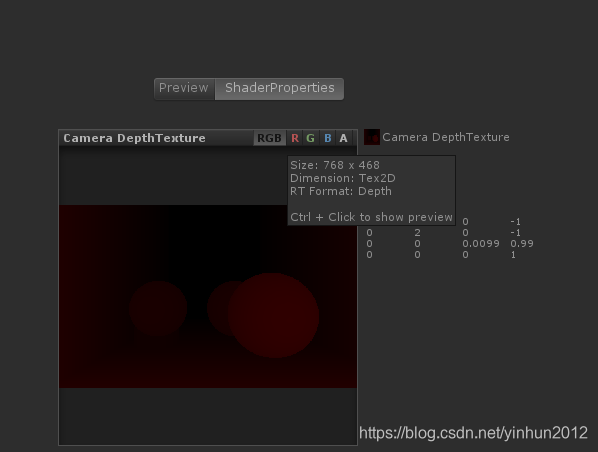
这是R通道表现的图,那么我们怎么把他变成一般情况下的深度图呢?什么叫一般情况呢?就是将R通道储存的深度z转换为RGB三通道0-1区间的归一化情况。
继续修改shader代码,进行R通道解码转化,如下:
unitycg.cginc提供了解码深度图的函数,如下:
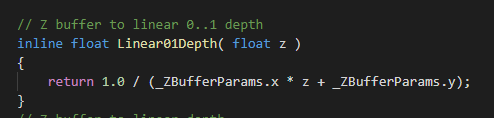
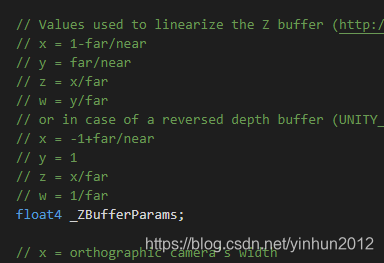
然后shader代码的片段函数中进行解码转换即可,如下:
Shader "Unlit/DepthShader"
{
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float4 uv : TEXCOORD0;
};
struct v2f
{
float4 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
};
sampler2D _CameraDepthTexture;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
//顶点经过mvp变换后,在计算在屏幕中的坐标参数,如xy的w化数值
//这个计算不理解的可以查看屏幕空间相关计算
o.uv = ComputeScreenPos(o.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
//只需要将深度图的R通道进行Linear01Depth操作就能得到
fixed depth = Linear01Depth(tex2D(_CameraDepthTexture,i.uv.xy / i.uv.w).r);
return fixed4(depth, depth, depth, 1);
}
ENDCG
}
}
}
最终实现的效果图如下:
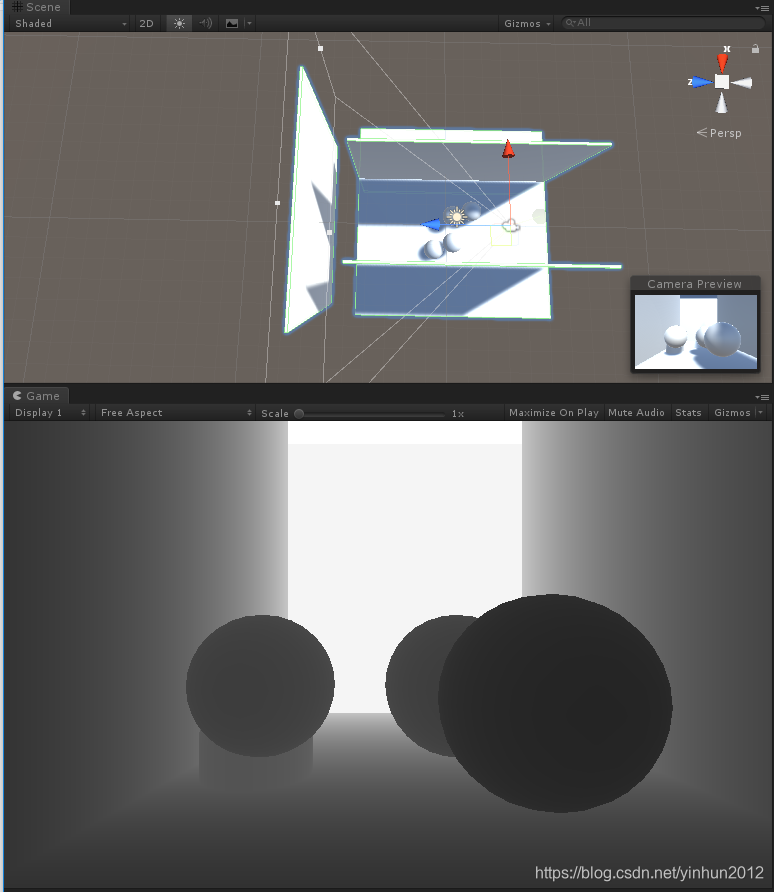
很好理解吧,距离摄像机越近的z值越趋近于0,所以采样转换后的颜色越黑,越远则z值越趋近于1,表现效果则是越白。
这里顺便抛出一个问题,就是为什么深度信息提取需要Linear01Depth和_ZBufferParams,原因是因为R通道的深度值并不是线性的,而是离散到从密集到稀松的,这里因为我现在办公台还没带上自动铅笔/白纸和尺规等工具,只能后面来推导一下这个计算过程的意义了。
好,写到这里,我们大致对深度图有了一定的了解,接下来的一段时间我要在独立游戏中实现一些效果,就会使用到深度图了,后面见。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









