






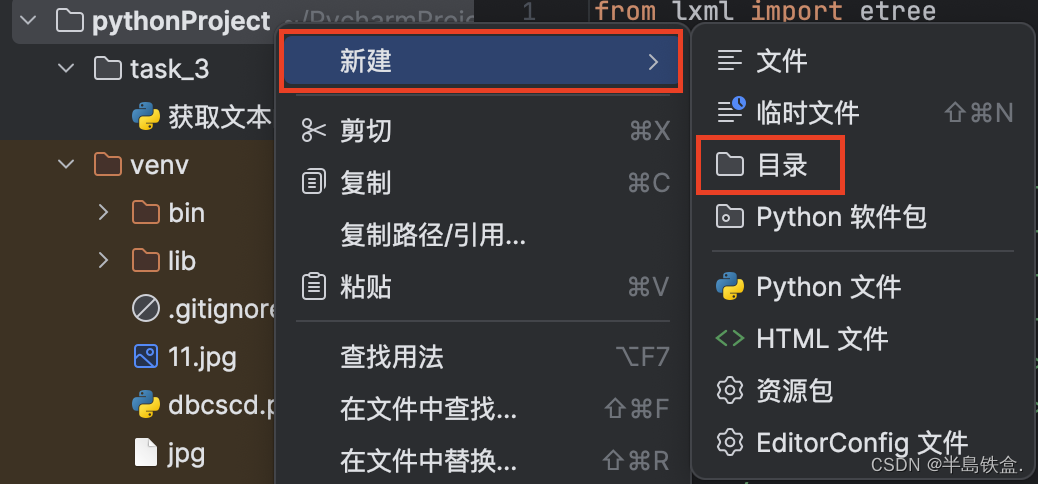
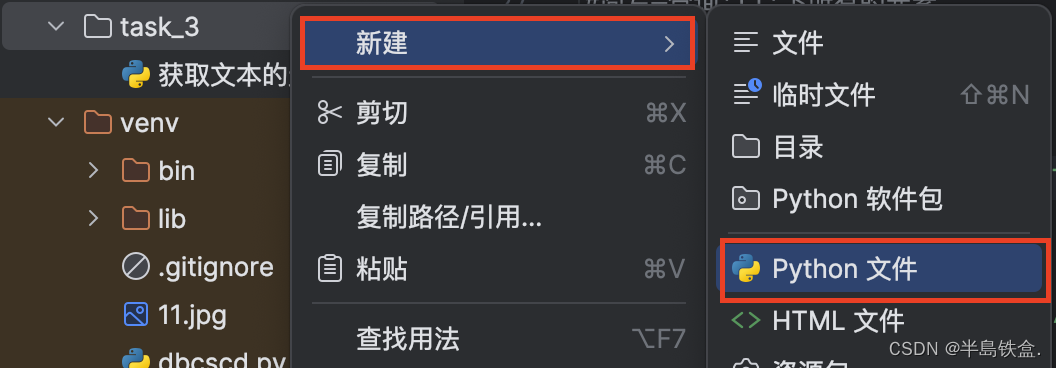
1.首先右键pythonproject新建一个目录,输入名字:task_3 回车,再在task_3里新建一个python文件,输入名字:获取文本的元素内容。
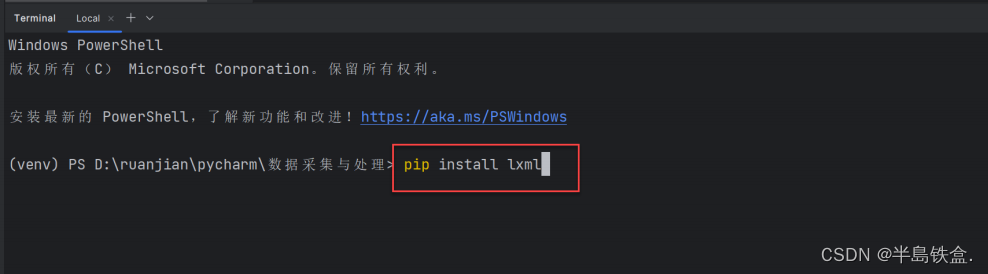
2.打开左下角的终端,pip安装lxml,输入核心代码:pip install lxml 为什么要安装lxml库(为了数据提取更加方便),lxml是帮助HTML、XML文件,快速定位、搜索、获取特定内容的python库。
3.lxml库安装完成
4.导入lxml库的etree包,核心代码:from lxml import etree (element tree(节点树))etree主要通过xpath进行定位

5.截取网页文本内容

6.使用etree解析网页,核心代码:selector=etree.HTML selector(挑选者,选择器)

7查询li下所有的元素,并打印,核心代码:list_all=selector.xpath('//div/ul/li')
print(list_all) xpath用来确定XML文档中某部分位置的语言

8.控制台打印结果展示

9.简写-查询li下所有的元素,从根节点选取(表示的是一层级)从匹配选择的当前节点选择文中的节点,而不考虑它们的位置(表示多个层级)核心代码:
list_all_short=selector.xpath('//li')
print(list_all_short)

10.控制台打印结果展示

11.查询li下的第2个元素内容,核心代码:
list_2=selector.xpath('//div/ul/li[2]/text()')
print(list_2)

12.控制台打印结果展示

13.简写-2查询li下的第2个元素内容,核心代码:
list_2_short=selector.xpath('//li[2]/text()')
print(list_2_short)

14.控制台打印结果展示

15.查询li下的第三个元素,text(代表文本内容)核心代码:
list_3=selector.xpath('//li[3]/text()')
print(list_3)

16.控制台打印结果展示

17.查询class="line-message"下的元素内容,(可以根据不同的内容进行定位,随后获取文本内容txt)核心代码:
list_class=selector.xpath('//li[@class="line-message"]/text()')
print(list_class) (可以根据不同的内容进行定位,随后获取文本内容txt)

18.控制台打印结果展示


















 3649
3649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









