









搭建AI推理模型-4090显卡
介绍:
| 系统 | Rocyk9.2 |
| IP | 192.168.0.97 |
| 显卡型号(非 4090p) | 4090 / 48G |
| 服务器型号 | H3C G5300-G5 |
| nvidia版本 | 550.54.15 |
| CUDA 版本 | 12.4 |
| 程序 |
|---|
| AnythingLLM |
| 前端界面Open WebUI |
| ChatOllama |
| ollama |
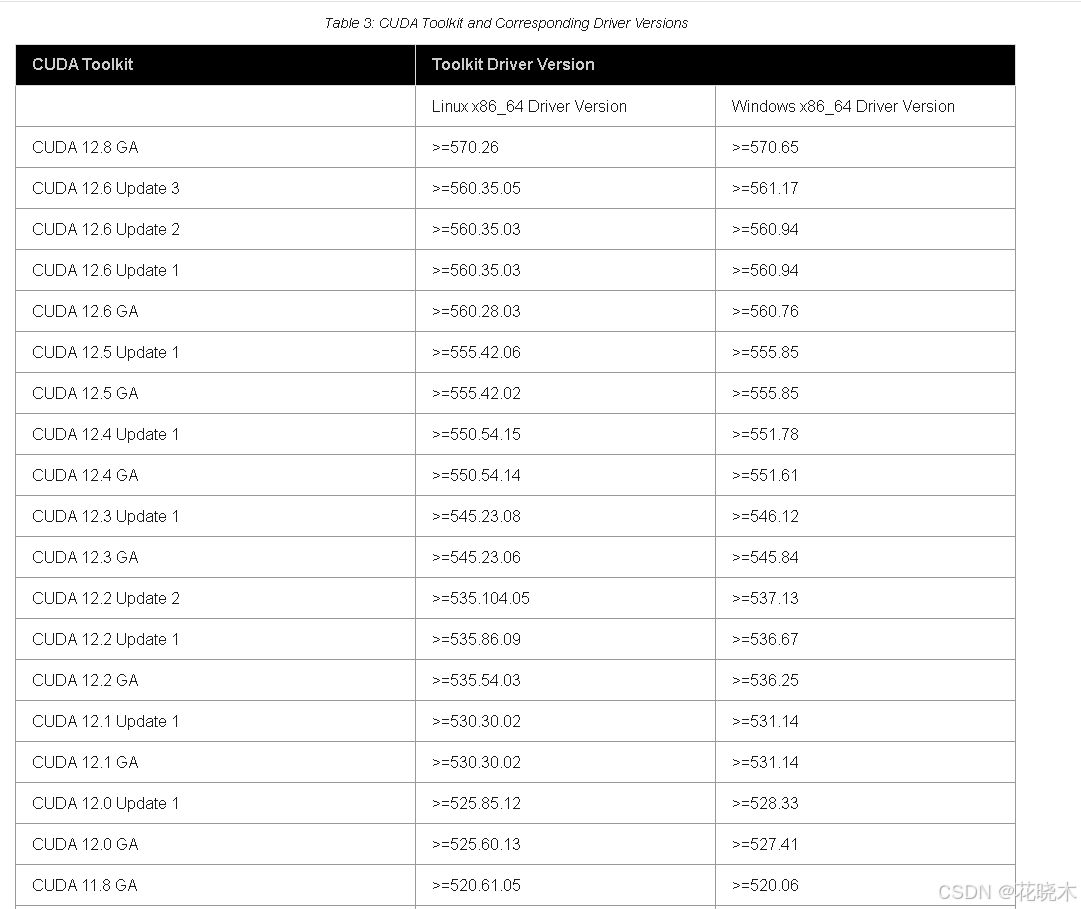
查看显卡驱动版本号和CUDA版本对应关系
点击该链接:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
前期准备:
rpm -qa | grep kernel
kernel-headers-5.14.0-284.11.1.el9_2.x86_64
kernel-tools-libs-5.14.0-284.11.1.el9_2.x86_64
kernel-srpm-macros-1.0-12.el9.noarch
kernel-tools-5.14.0-284.11.1.el9_2.x86_64
kernel-devel-5.14.0-284.11.1.el9_2.x86_64
kernel-modules-core-5.14.0-284.11.1.el9_2.x86_64
kernel-core-5.14.0-284.11.1.el9_2.x86_64
kernel-modules-5.14.0-284.11.1.el9_2.x86_64
kernel-5.14.0-284.11.1.el9_2.x86_64
# 如果有 kernel-headers 和 kernel-devel 而且版本对应正常则无需下载,如果没有这需要下载,
如果不一样 需要卸载之后手动下载
手动下载地址
wget https://yum.oracle.com/repo/OracleLinux/OL9/appstream/x86_64/getPackage/kernel-devel-5.14.0-284.11.1.el9_2.x86_64.rpm
yum -y install kernel-devel-5.14.0-284.11.1.el9_2.x86_64.rpm
wget https://repo.almalinux.org/almalinux/9/AppStream/x86_64/os/Packages/kernel-headers-5.14.0-284.11.1.el9_2.x86_64.rpm
yum -y install kernel-headers-5.14.0-284.11.1.el9_2.x86_64.rpm
命令行输出:lspci |grep -i nvidia 查看nvidia显卡信息显示如下:
0b:00.0 NIVIDIA compatible controller: Matrox Electronics Systems Ltd. G200eR2
如果没有lspci命令,执行:yum -y install pci*,就能在线安装lspci。
然后在命令行执行:lspci -v -s 0b:00.0 显示显卡大致信息,说明系统已经识别显卡。
修改各个配置文件
配置文件如果不存在,直接新建
修改一:
vim /usr/lib/modprobe.d/dist-blacklist.conf
blacklist nouveau
options nouveau modeset=0
修改二:
vim /etc/modprobe.d/dccp-blacklist.conf
blacklist dccp
blacklist dccp_diag
blacklist dccp_ipv4
blacklist dccp_ipv6
blacklist nouveau
blacklist nvidiafb
options nouveau modeset=0
修改三:
vim /etc/modprobe.d/blacklist-nouveau.conf
blacklist nouveau
options nouveau modeset=0
blacklist nvidiafb
修改四:
vim /etc/modprobe.d/blacklist.conf
blacklist nouveau
options nouveau modeset=0
blacklist nvidiafb
blacklist vga16fb
blacklist nouveau
blacklist rivafb
blacklist rivatv
备份initramfs:
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
重新建立initramfs:
dracut -v /boot/initramfs-$(uname -r).img $(uname -r)
启动服务
systemctl set-default multi-user.target
刷新文本,重启服务器
reboot
## 重启后,检查nouveau driver确保没有被加载! 为空就对了
lsmod | grep nouveau
安装 NVIDIA
浏览器访问:
https://www.nvidia.cn/
点击驱动程序

选择 – 点击查找

选择第一个 --》 点击查看
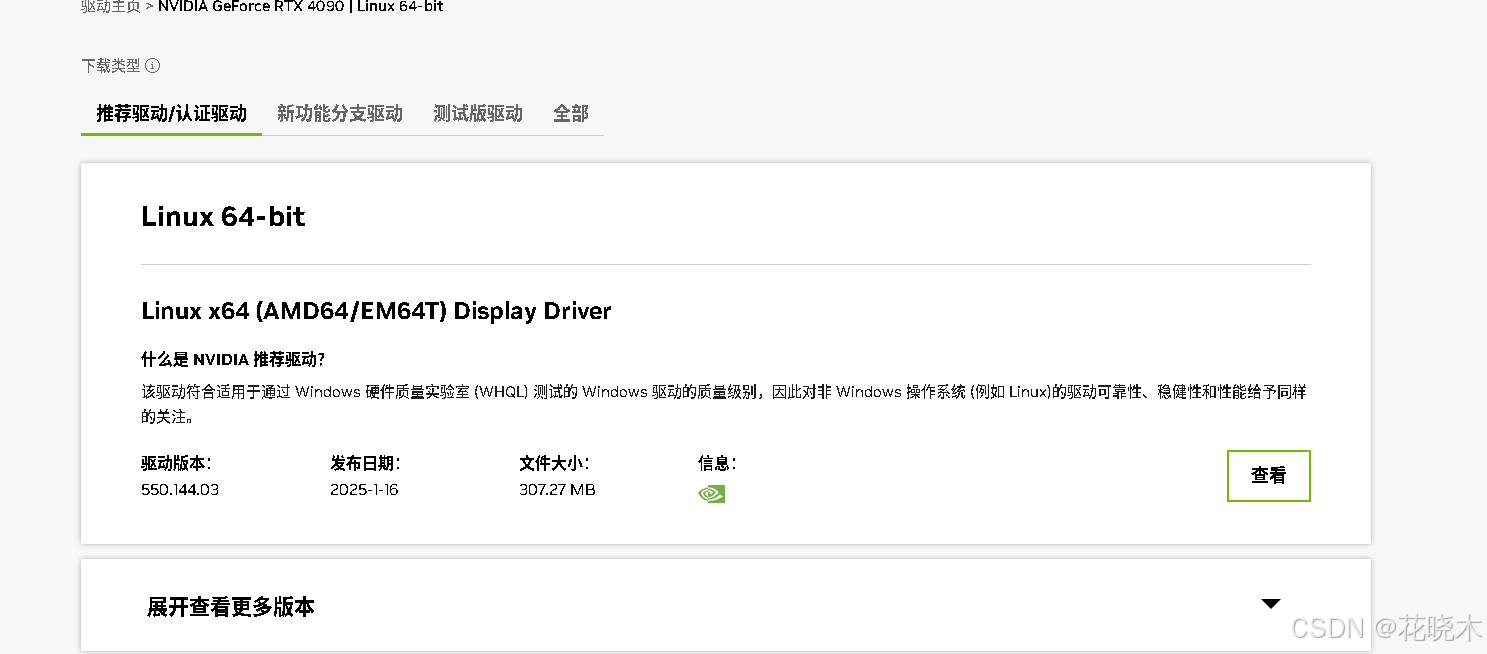
点击下载
将文件上传至服务器
chmod 777 NVIDIA-Linux-x86_64-550.144.03.run
执行如下命令:
[root@localhost src]# ./NVIDIA-Linux-x86_64-550.144.03.run --kernel-source-path=/usr/src/kernels/5.14.0-284.11.1.el9_2.x86_64/ --no-drm --no-opengl-files
尝试安装“vulkan加载器”、“vulkanicd加载器”或“libvulkan1”包。
点击OK

等着安装进度到 100%
Install NVIDIA's 32-bit compatibility libraries?
选择 NO


由于以下情况,可能需要重建initramfs:
选择Rebuild initramfs

是否要运行nvidia-xconfig实用程序自动更新X配置文件,以便在重新启动X时使用nvidia X驱动程序?
Would you like to run the nvidia-xconfig utility to automatically update your X configuration file so that the NVIDIA X driver will be used when you restart X? Any pre-existing X
configuration file will be backed up.
选择 NO

查看日志:无报错
tail -f /var/log/nvidia-installer.log
executing: '/usr/bin/chcon -t textrel_shlib_t /usr/lib64/libnvidia-opticalflow.so.525.85.12'...
executing: '/usr/sbin/ldconfig'...
executing: '/usr/sbin/depmod -a '...
executing: '/usr/bin/systemctl daemon-reload'...
-> done.
-> Driver file installation is complete.
-> Running post-install sanity check:
-> done.
-> Post-install sanity check passed.
-> Installation of the NVIDIA Accelerated Graphics Driver for Linux-x86_64 (version: 525.85.12) is now complete.
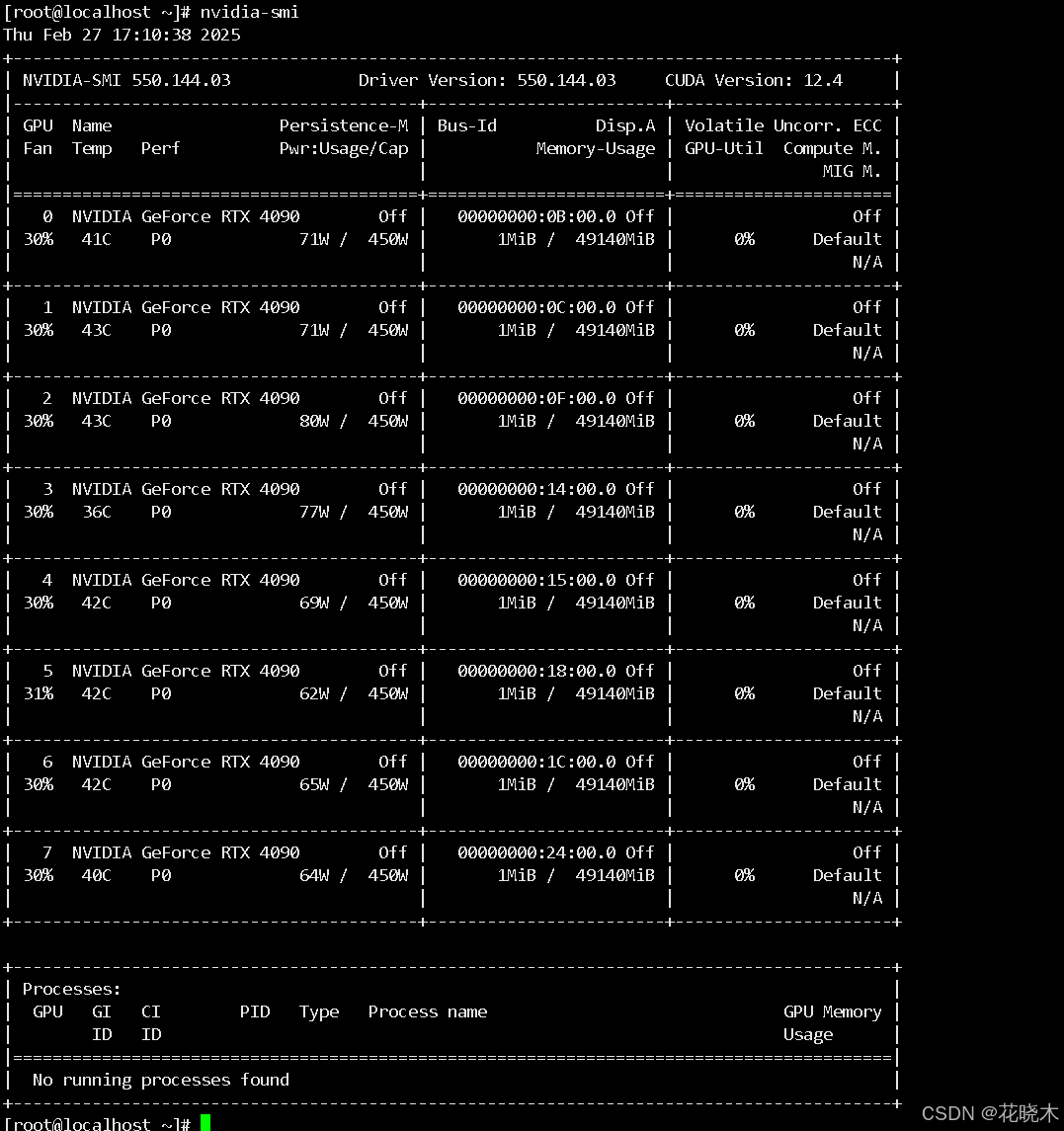
测试安装结果
`执行:nvidia-smi
如图:
安装CUDA
版本下载地址:https://developer.nvidia.com/cuda-toolkit-archive
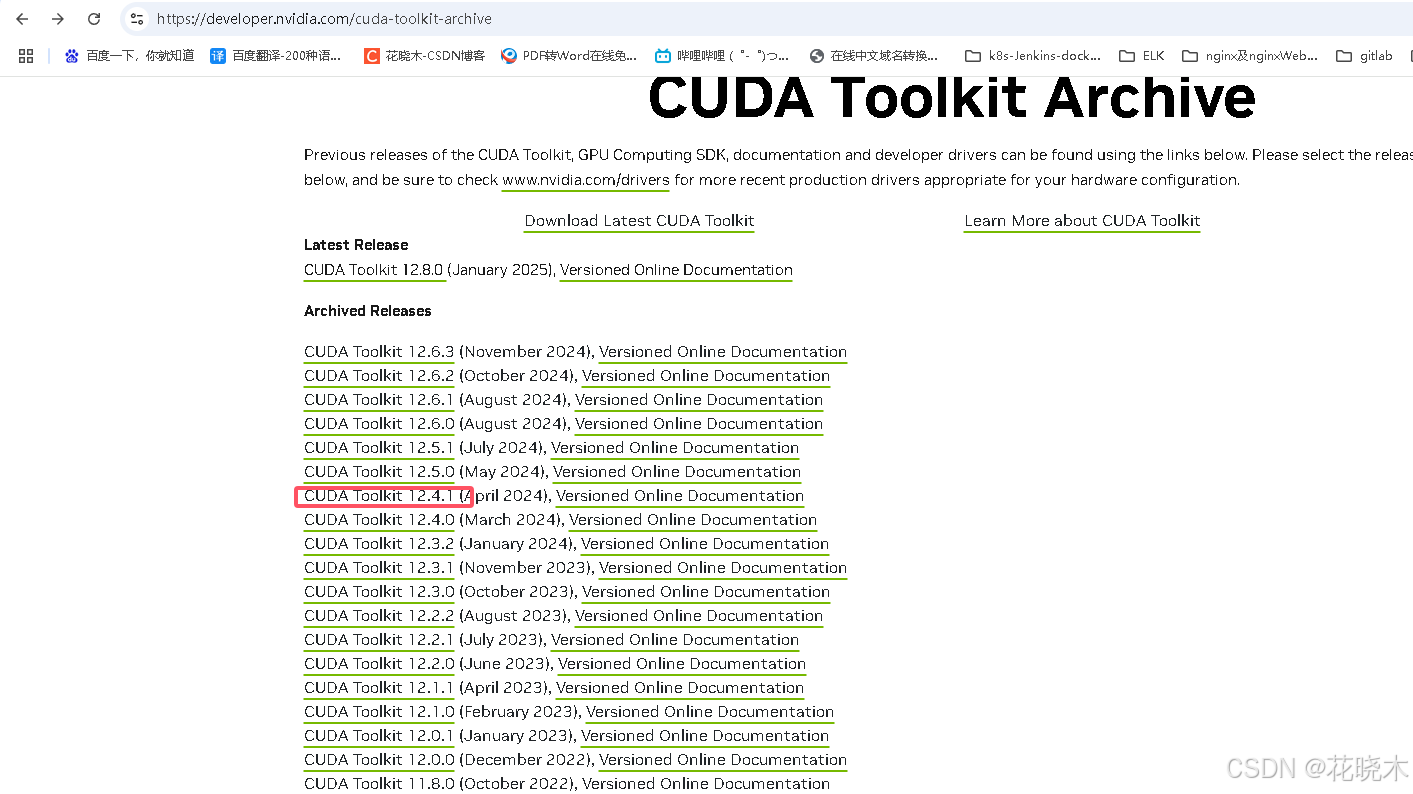
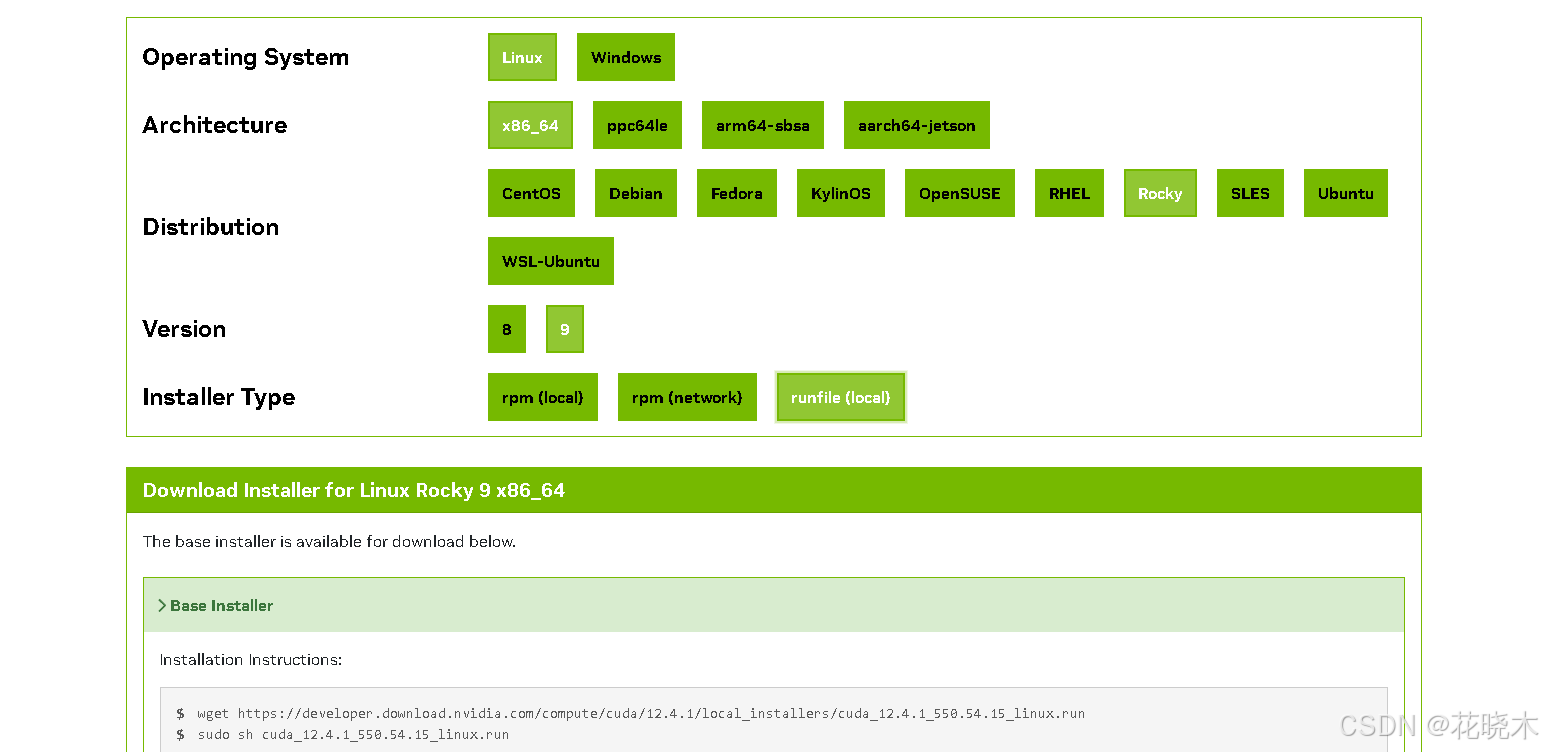
按照如图所示下载:
到服务器上:
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda_12.4.1_550.54.15_linux.run
mv cuda_12.4.1_550.54.15_linux.run /opt/src
chmod 755 cuda_12.4.1_550.54.15_linux.run
执行安装命令:
./cuda_12.4.1_550.54.15_linux.run --kernel-source-path=/usr/src/kernels/5.14.0-284.11.1.el9_2.x86_64/
如图:
输入:accept 回车
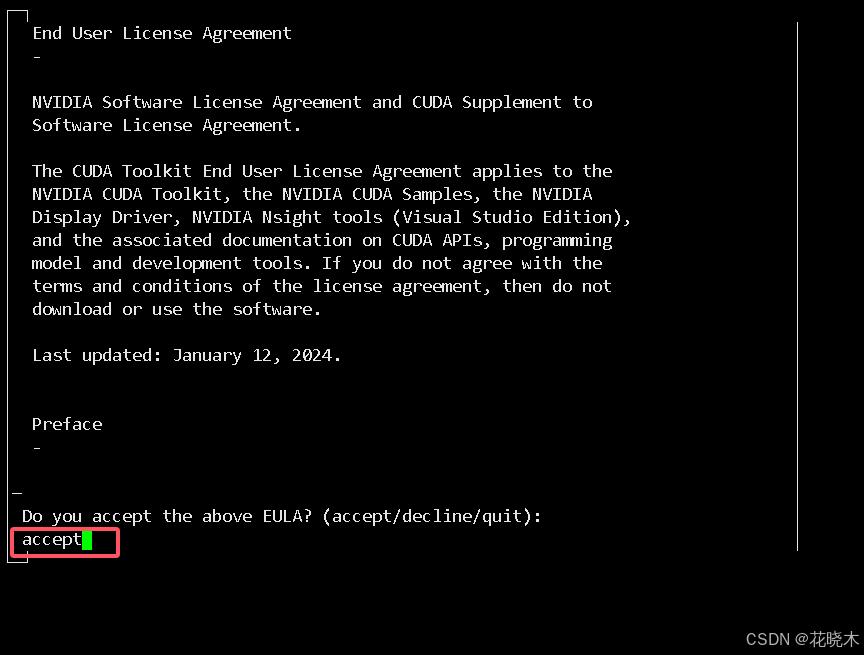
使用上下左右键 将鼠标放到 Install 上 回车
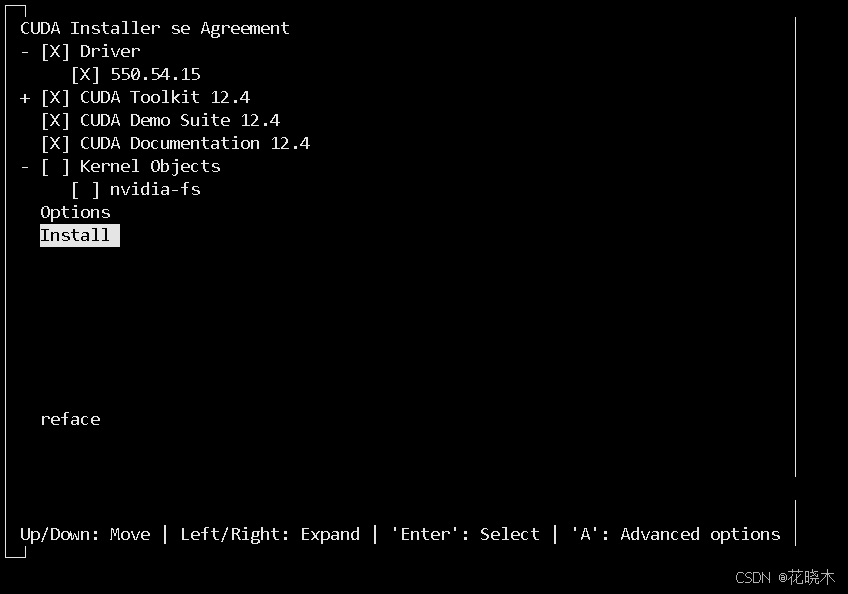
等待
如果有报错 查看日志:
tail -f /var/log/cuda-installer.log for details
出现如图这个说明安装成功。
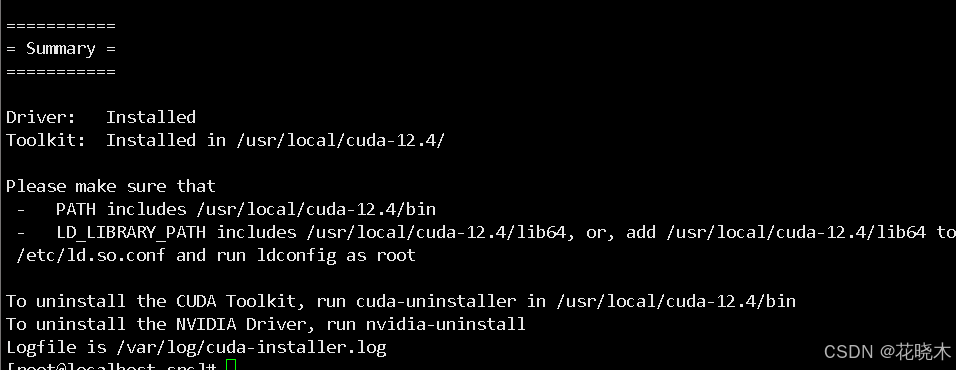
安装 conda
官网下载:https://www.anaconda.com/products/individual
清华镜像源: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
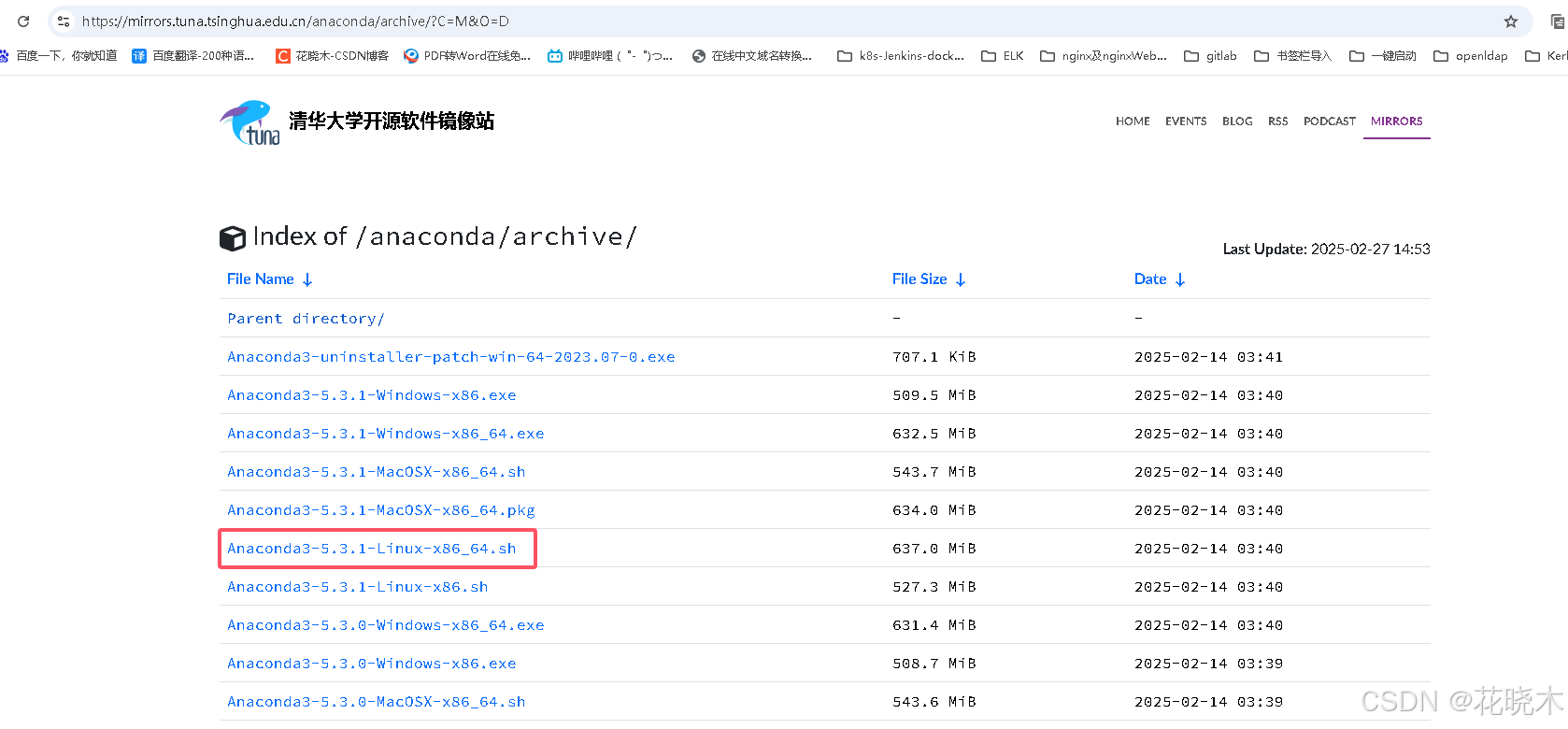
wget https://repo.anaconda.com/archive/Anaconda3-5.3.1-Linux-x86_64.sh
chmod 755 Anaconda3-5.3.1-Linux-x86_64.sh
mv Anaconda3-5.3.1-Linux-x86_64.sh /opt/src/
cd /opt/src/
sha256sum Anaconda3-5.3.1-Linux-x86_64.sh
bash Anaconda3-5.3.1-Linux-x86_64.sh
一共需要输入3次
第一次直接回车;
第二次输入yes;
第三次输入:/data/anaconda3
第四次输入yes;
之后等待即可 执行有点慢
more ~/.bashrc
### 最后的内容如下:
# added by Anaconda3 5.3.1 installer
# >>> conda init >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$(CONDA_REPORT_ERRORS=false '/data/anaconda3/bin/conda' shell.bash hook 2> /dev/
null)"
if [ $? -eq 0 ]; then
\eval "$__conda_setup"
else
if [ -f "/data/anaconda3/etc/profile.d/conda.sh" ]; then
. "/data/anaconda3/etc/profile.d/conda.sh"
CONDA_CHANGEPS1=false conda activate base
else
\export PATH="/data/anaconda3/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda init <<<
### 刷新
source ~/.bashrc
# 更换conda源
# 执行命令清理缓存
conda clean --all -y
conda config --remove-key channels
# 修改conda配置为国内镜像源(如清华源,中科大源,阿里云源)
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/
conda config --set show_channel_urls yes
conda config --show-sources
# 查询当前镜像
conda config --show channels
conda config --show
# 添加conda-forge通道:
conda config --append channels conda-forge
conda config --set channel_priority flexible
指定具体版本:
conda create -n qwenvl python=3.11 -y
conda create -n test python=3.11 -y --override-channels -c conda-forge
# 如果要换回默认源
conda config --remove-key channels
conda config --show-sources
==> /root/.condarc <==
channel_alias: http://mirrors.tuna.tsinghua.edu.cn/anaconda
show_channel_urls: True
report_errors: True
配置 qwenvl 虚拟环境
https://blog.youkuaiyun.com/yhl18931306541/article/details/147309402?spm=1001.2014.3001.5501
安装语言推理模型
一、AnythingLLM 介绍
AnythingLLM 是 Mintplex Labs Inc. 开发的一款开源 ChatGPT 等效工具,
用于在安全的环境中与文档等进行聊天,专为想要使用现有文档进行智能聊天或构建知识库的任何人而构建。
二、前端界面Open WebUI 介绍
Open WebUI 是针对 LLM 的用户友好的 WebUI,支持的 LLM 运行程序包括 Ollama
和 OpenAI 兼容的 API。
Open WebUI 系统旨在简化客户端(您的浏览器)和 Ollama API 之间的交互。
此设计的核心是后端反向代理,可增强安全性并解决 CORS 问题。
三、ChatOllama 介绍
ChatOllama 是一个 Nuxt 3 + Ollama Web 应用程序。ChatOllama 允许您管理您的 Ollama 服务器,
并与世界各地的 LLM 聊天。
从功能上来说,ChatOllama 类似于 Open WebU 和 AnythingLLM 的混合体,既可以和 AI 聊天,
也可以用来构建自己专属的知识库
四、ollama 介绍
开源免费:Ollama是一个不收费的开源工具。
即插即用:它提供了预装好的大模型,免除了复杂的安装和下载流程。
用户友好:即便没有任何技术背景,Ollama也易于上手和使用。
跨平台兼容性:
Ollama支持各种设备,包括PC、Mac甚至是树莓派。
运行各种规模的模型,保证了出色的扩展性。
安装 docker
https://blog.youkuaiyun.com/yhl18931306541/article/details/126542342?spm=1001.2014.3001.5501
安装 AnythingLLM
docker pull mintplexlabs/anythingllm
export STORAGE_LOCATION=/data/anythingllm && \
mkdir -p $STORAGE_LOCATION && \
touch "$STORAGE_LOCATION/.env" && \
docker run -d -p 3001:3001 \
--restart always \
--cap-add SYS_ADMIN \
-v ${STORAGE_LOCATION}:/app/server/storage \
-v ${STORAGE_LOCATION}/.env:/app/server/.env \
-e STORAGE_DIR="/app/server/storage" \
mintplexlabs/anythingllm
报错:unable to open database file: ../storage/anythingllm.db
mkdir -p /data/anythingllm
chmod 777 -R /data/anythingllm
报错:Error: EACCES: permission denied, open '/app/server/.env'
chmod 777 -R /data/anythingllm/.env
报错:Error: EACCES: permission denied, open '/app/server/storage/comkey/ipc-priv.pem'
mkdir -p /data/anythingllm/comkey
chmod 777 -R /data/anythingllm/comkey
安装ChatOllama
mkdir -p /data/chatollama/{data,db}
cd /data/chatollama
vim docker-compose.yml
把如下配置放到 docker-compose.yml 里
version: '3.1'
services:
chromadb:
image: chromadb/chroma:latest
container_name: chatollama-db
restart: always
ports:
- "11431:8000"
volumes:
- ./data:/chroma/.chroma/index
networks:
mynetwork:
ipv4_address: 172.24.0.200 # 指定 chromadb 的 IP 地址
chatollama:
image: 0001coder/chatollama:latest
container_name: chatollama-web
restart: always
ports:
- "11432:3000"
volumes:
- ./db:/app/sqlite
environment:
- CHROMADB_URL=http://172.24.0.200:8000 # 使用指定的 chromadb IP 地址
- DATABASE_URL=file:/app/sqlite/chatollama.sqlite
build:
context: .
dockerfile: Dockerfile
depends_on:
- chromadb
networks:
mynetwork:
ipv4_address: 172.24.0.201 # 指定 chatollama 的 IP 地址
networks:
mynetwork:
driver: bridge
ipam:
config:
- subnet: 172.24.0.0/16
在目录中执行如下命令
docker-compose up -d
如果没有 docker-compose
安装地址
https://github.com/docker/compose/releases
wget https://github.com/docker/compose/releases/download/v2.28.1/docker-compose-linux-x86_64
mv docker-compose-linux-x86_64 /usr/bin/docker-compose
chmod +x /usr/bin/docker-compose
docker-compose --version
# 在执行
docker-compose up -d
数据库初始化
容器启动后,先不忙访问,还需要对 SQLite 数据库进行初始化处理
# 如果您是第一次启动,需要初始化 SQLite 数据库
docker-compose exec chatollama npx prisma migrate dev
如果不执行初始化,后面在创建知识库时会遇到下面的报错
Invalid `prisma.knowledgeBase.count()` invocation: The table `main.KnowledgeBase`
does not exist in the current database.
再启动
docker-compose up -d
如果要删除多余的网卡
如果可能,清理掉现有的冲突网络。你可以通过以下命令列出所有 Docker 网络并删除冲突的网络:
docker network ls
docker network rm <network_id_or_name>
安装 ollama (非 docker 版 )
curl -fsSL https://ollama.com/install.sh | sh
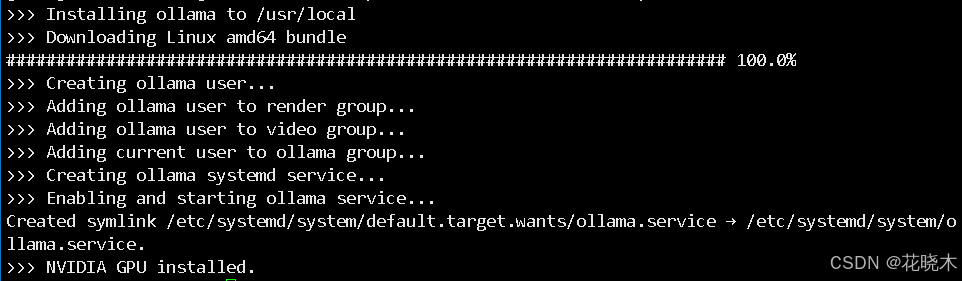
如果启动多个 Ollama 服务器实例,每个实例使用不同的主机和 GPU
mkdir /var/log/ollama_logs
vim start-ollama.sh
#!/bin/bash
# 启动多个 Ollama 实例,每个实例使用不同的 GPU 和端口
declare -A ports=( [0]=11434 [1]=11450 [2]=11451 [3]=11452 [4]=11453 [5]=11454 [6]=11455 [7]
=11456 )
for gpu in "${!ports[@]}"
do
export OLLAMA_HOST="0.0.0.0:${ports[$gpu]}"
export CUDA_VISIBLE_DEVICES=$gpu
# 启动 Ollama 实例
ollama serve &
# 输出启动信息
echo "Started Ollama instance on GPU $gpu at port ${ports[$gpu]}"
sleep 3
done
# 等待所有后台进程完成
wait
chmod 755 start-ollama.sh
bash /root/start_ollama.sh >/dev/null 2>&1 &
如果需要查询每个ollama状态,使用如下方式
vim ollama_status.sh
#!/bin/bash
# 定义一个端口数组
declare -A ports=( [0]=11434 [1]=11450 [2]=11451 [3]=11452 [4]=11453 [5]=11454 [6]=11455 [7]=11456 )
# 遍历每个端口,检查 Ollama 实例的状态
for gpu in "${!ports[@]}"
do
export OLLAMA_HOST="0.0.0.0:${ports[$gpu]}"
export CUDA_VISIBLE_DEVICES=$gpu
# 执行 ollama ps,检查该端口的状态
# status=$(ollama ps | grep "${ports[$gpu]}" | awk '{print $4}')
status=$(ollama ps | awk 'NR>1 {print $1, $5,$6}')
# 输出端口和状态信息
echo "Port ${ports[$gpu]} on GPU $gpu: $status"
done
安装 ollama ( docker 版 )
docker pull ollama/ollama
docker run --gpus "device=0" -e OLLAMA_FLASH_ATTENTI0N=1 \
--restart always --name ollama \
-p 11434:11434 -v /data/.ollama:/root/.ollama \
-v /etc/localtime:/etc/localtime -d ollama/ollama
docker run --gpus "device=1" -e OLLAMA_FLASH_ATTENTI0N=1 \
--restart always --name ollama_01 \
-p 11450:11434 -v /data/.ollama:/root/.ollama \
-v /etc/localtime:/etc/localtime -d ollama/ollama
注释:如果有四块GPU --gpus "device=" 指定使用哪一块显卡
从0开始 0是第一块 1是第二块
如果报错
docker: Error response from daemon:
could not select device driver "" with capabilities: [[gpu]].
nvidia-docker.repo 镜像链接地址
https://download.youkuaiyun.com/download/yhl18931306541/89493077?spm=1001.2014.3001.5501
将 repo 上传到服务器的 /etc/yum.repos.d 中
yum -y install nvidia-container-runtime
yum install -y nvidia-docker2
vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker.1ms.run",
"https://proxy.1panel.live",
"https://docker.ketches.cn"
],
"ipv6": false,
"max-concurrent-downloads": 10,
"log-driver": "json-file",
"log-level": "warn",
"log-opts": {
"max-size": "10m",
"max-file": "3"
},
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime": "nvidia",
"data-root": "/data/docker"
}
systemctl restart docker
然后执行
docker run --gpus "device=0" -e OLLAMA_FLASH_ATTENTI0N=1 \
--name ollama -v /data/.ollama:/root/.ollama -v /etc/localtime:/etc/localtime \
-p 11434:11434 -d ollama/ollama
安装前端界面Open WebUI
github地址 :https://github.com/open-webui/open-webui/pkgs/container/open-webui
## 例:
docker run -d -p 13000:8080 \
--gpus all --add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always ghcr.io/open-webui/open-webui:cuda
注释:
-d:在后台运行容器。
-p 13000:8080:将主机的 13000 端口映射到容器的 8080 端口。主机上访问 http://localhost:13000 会转发到容器中的 8080 端口。
--gpus all:允许容器访问所有可用的 GPU,这对于需要 GPU 加速的应用很重要。
--add-host=host.docker.internal:host-gateway:添加一个主机条目,将 host.docker.internal 映射到主机的 IP 地址,以便容器可以访问主机上的服务。
:host-gateway 是宿主机IP地址
-v open-webui:/app/backend/data:将主机上的 open-webui 数据卷挂载到容器中的 /app/backend/data 目录,以便容器可以访问和持久化数据。
--name open-webui:为容器指定名称 open-webui。
--restart always:确保容器在失败时自动重启,并在 Docker 启动时启动。
ghcr.io/open-webui/open-webui:cuda:指定 Docker 镜像及其标签,cuda 表示这个镜像包含 CUDA 支持,适用于 GPU 加速
--add-host=host.docker.internal:host-gateway 的作用就是在容器的hosts中加个解析
修正之后的命令如下:
docker run -d -p 13000:8080 \
--gpus all --add-host=host.docker.internal:192.168.0.97 \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always ghcr.nju.edu.cn/open-webui/open-webui:cuda
更改为国内地址(下载快一点)
docker run -d -p 13000:8080 \
--gpus all --add-host=host.docker.internal:192.168.0.48 \
--name open-webui --restart always \
-v open-webui:/app/backend/data \
registry.cn-shenzhen.aliyuncs.com/funet8/open-webui:cuda
访问:http://192.168.0.97:13000
如果选择模型为空
如果报错
docker: Error response from daemon:
could not select device driver "" with capabilities: [[gpu]].
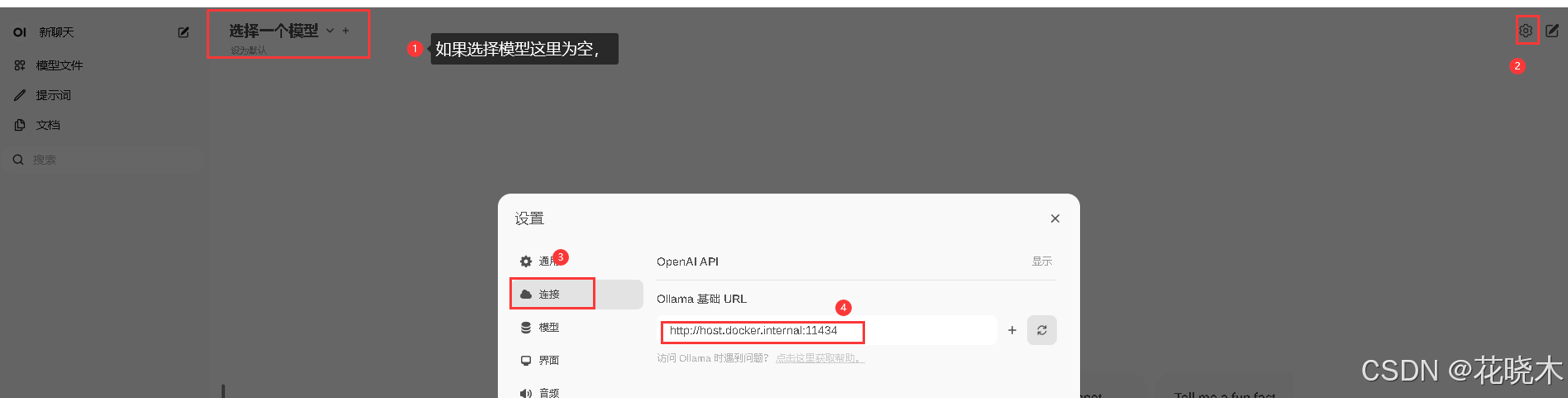
设置完成之后,去到服务器上,进到这个docker容器中
apt update
apt install -y iputils-ping vim net-tools telnet
vim /etc/hosts
192.168.0.97 host.docker.internal
退出容器
在 iptables 中 放开所有
service iptables save
vim /etc/sysconfig/iptables
-A INPUT -p tcp -m tcp --dport 11434 -j ACCEPT
systemctl restart iptables
默认的是访问11434端口,如果想改为其他端口
docker exec -it open-webui /bin/bash
进到容器中
/app/backend# vim config.py
:%s/11434/11449/g (改为你想修改的端口即可)
docker restart open-webui
如果重启完docker 看不到那些容器了
例如: 为空
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cd /etc/docker/
ls
daemon.json daemon.json.rpmorig
mv daemon.json.rpmorig daemon.json
mv:是否覆盖'daemon.json'? y
systemctl restart docker
[root@localhost docker]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
31fe10aec587 0001coder/chatollama:latest "docker-entrypoint.s…" 44 minutes ago Up 3 seconds 0.0.0.0:11432->3000/tcp, [::]:11432->3000/tcp chatollama-web
5fbdcdd318f7 chromadb/chroma:latest "/docker_entrypoint.…" 44 minutes ago Up 3 seconds 0.0.0.0:11431->8000/tcp, [::]:11431->8000/tcp chatollama-db
fd2df856d5a6 mintplexlabs/anythingllm "/bin/bash /usr/loca…" 2 hours ago Up 3 seconds (health: starting) 0.0.0.0:3001->3001/tcp, [::]:3001->3001/tcp youthful_noyce
# 在继续执行 ,成功
docker run -d -p 13000:8080 --gpus all \
--add-host=host.docker.internal:192.168.0.98 \
--name open-webui --restart always \
-v open-webui:/app/backend/data \
registry.cn-shenzhen.aliyuncs.com/funet8/open-webui:cuda
837670e9f60a3b07d0c1379483f06e7b0fc5383b6f9534d71530c7dc00a1396e
最后展示
访问 :http://192.168.0.98:13000
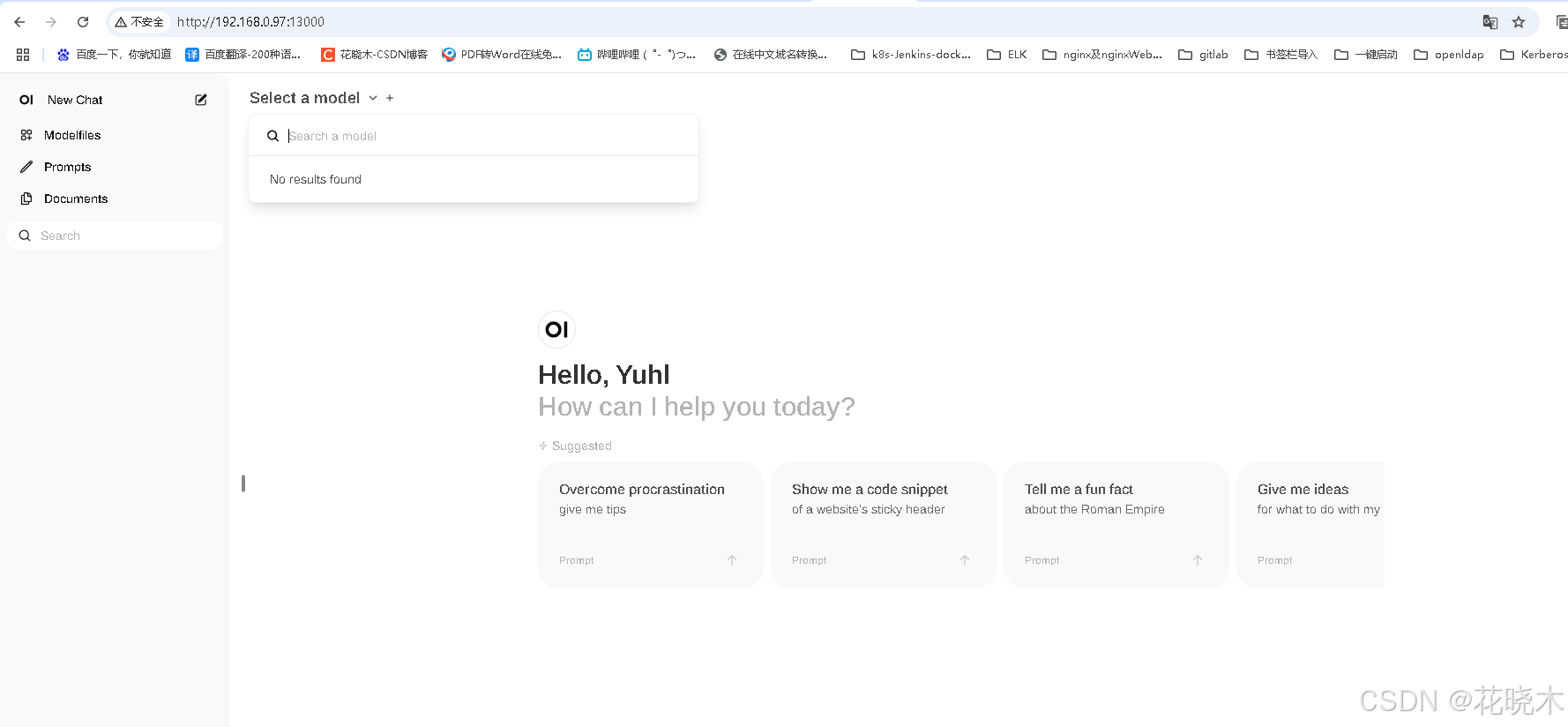
最好用的模型:
deepseek-r1:32B
deepseek-r1:70B (这个推理比较强一些)
deepseek-r1:14B
deepseek-r1:8B
deepseek-r1:7B
ollama run qwen:32b
ollama run qwen2.5:7b
ollama run qwen2.5:14b
ollama run qwen2.5:32b (这个比较稳定一些)
ollama run qwen2.5:70b (这个比较稳定一些)
ollama run qwen2:latest
ollama run qwen2:7b-instruct-q8_0

成果展示
ollama run deepseek-r1:70b
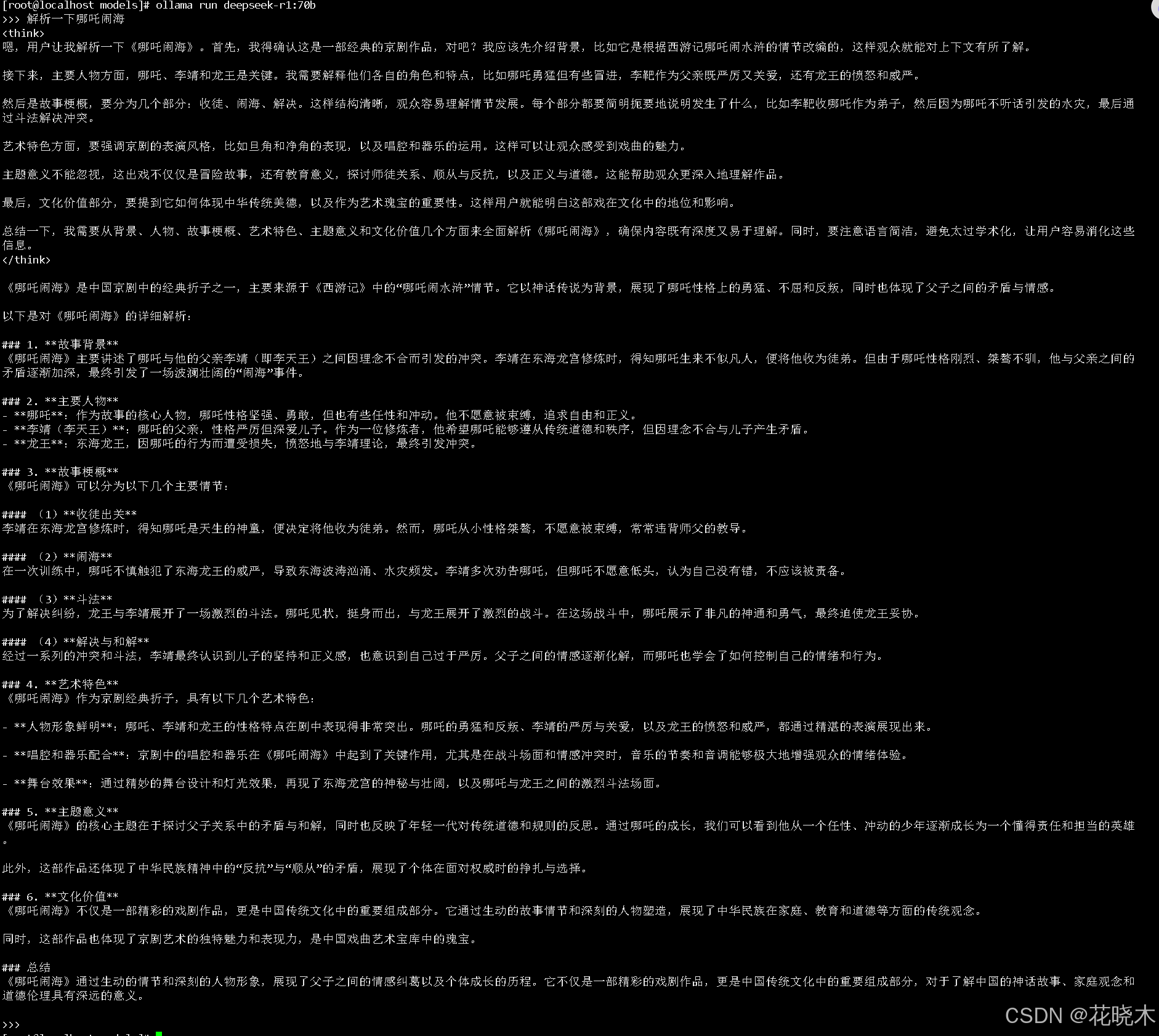
显存占比
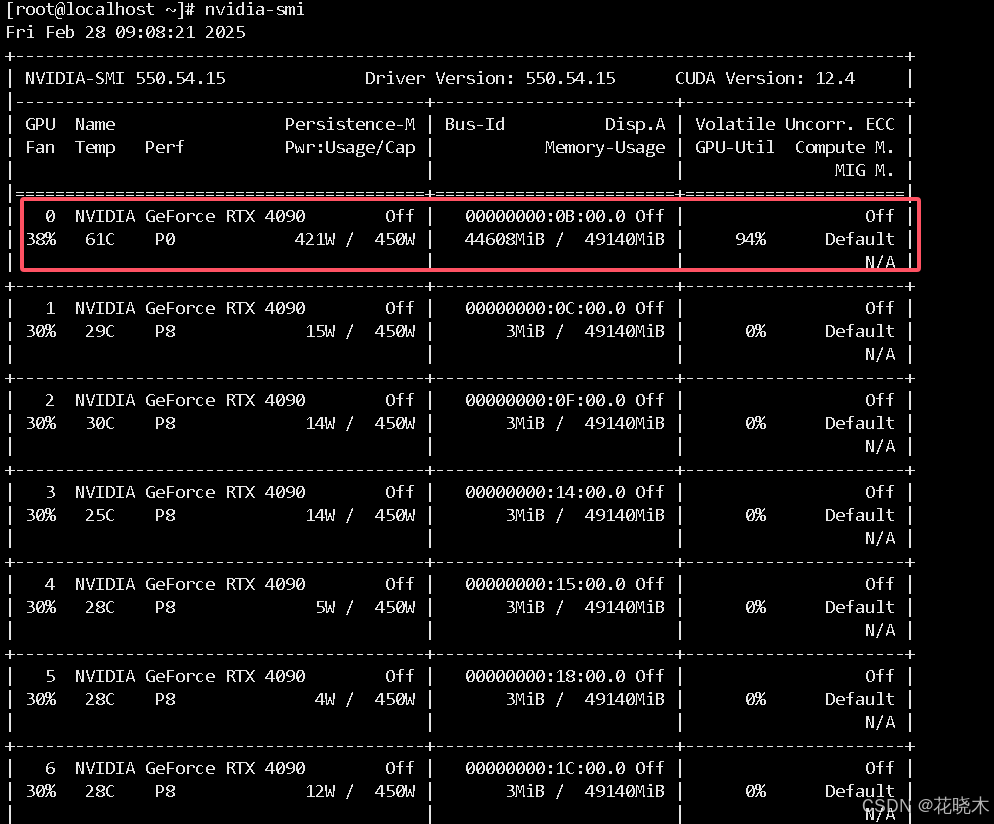
ollama run qwen2.5:72b

显存占比


















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









