






NER 模型对男性名字的识别通常更准确,而对女性名字的错误率更高,这是真的吗?
废话少说我们直接以实验为准:
1.拉取dslim/bert-base-NER自然语言模式进行实验:
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
# https://huggingface.co/dslim/bert-base-NER
model_name = './model'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline(
"ner", model=model,
tokenizer=tokenizer,
device=-1
)2.我们直接实验一下句子是否能成功识别:
ner_results = nlp(['Wolfgang lives in Berlin',
'Queen is a nurse',
'Elizabeth is eating food',
'Tennessee is a nurse',
'Queen lives in Boston'])
ner_results在这些句子中,wolfgang是人名,berlin是地名,queen是人名,elizabeth是人名,tennessee是人名,boston是地名。
我们看看模型输出结果是否正确:
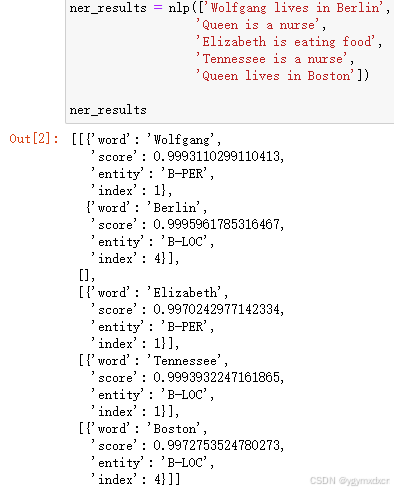
3.明显,对于queen的女性名字已经识别不到了,tennessee的女性人名也识别为地名,而男性名字却识别较为准确,这是否是一种偏差呢,我们为了验证这种现象从而选取美国1880-2019年不同性别新生儿的姓名进行大量验证,文件内容为姓名,性别和取名频率:
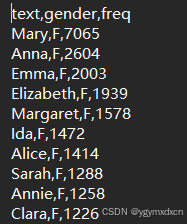
4.因为数据文件第一列都是人名,所有我们还要对模型输出结果进行重新处理:
def reformat_ner_results(ner_results):
reformatted_labels = []
# 如果输出结果为空则标记为‘o’模型未识别出结果
for entities in ner_results:
if not entities:
reformatted_labels.append('O')
continue
first_entity = entities[0]
# 因为我们只有第一位是人名,所有索引大于1的也识别未‘o’
if first_entity['index'] != 1:
reformatted_labels.append('O')
continue
# 其它的就为模型自己识别的结果
entity_label = first_entity['entity']
reformatted_labels.append(entity_label)
return reformatted_labels对模型数据结果加入reformat函数进行测试:
print(ner_results)
# 处理 NER 预测结果
formatted_labels = reformat_ner_results(ner_results)
# 输出最终的实体标签
print(formatted_labels)
5.接下来我们用三种错误类型来进行权重输出(想要了解这三种错误类型的具体来源的话可参考这篇文章Man is to Person as Woman is to Location | Proceedings of the 31st ACM Conference on Hypertext and Social Media)具体错误类型为1:误将非人名标记为人名。2:未识别任何实体。3:预测为其他类型实体。
def type1_error_weighted(freqs, preds):
error = 0 # 误将非人名标记为人名,因为文件中都是人名,所以不存在非人名误标记,因此直接返回0
return error
def type2_error_weighted(freqs, preds):
error = 0
for freq, pred in zip(freqs, preds):
if pred == 'O': # 未识别任何实体
error += freq
return error / sum(freqs)
def type3_error_weighted(freqs, preds):
error = 0
for freq, pred in zip(freqs, preds):
if pred not in {'O', 'B-PER', 'I-PER'}: # 预测为其他类型实体
error += freq
return error / sum(freqs)6.编写函数读取zip文件,并进行模型预测和错误类型权重输出:
import zipfile
import os
def load_data_from_zip(zip_path, year, gender, template_idx):
target_prefix = f"data_processed/Template_{template_idx}/{gender}{year}" # 目标文件名前缀
texts = []
freqs = []
with zipfile.ZipFile(zip_path, 'r') as zipf:
# 获取所有文件列表
file_list = zipf.namelist()
# 过滤匹配 {gender}{year} 开头的文件
matching_files = [f for f in file_list if f.startswith(target_prefix)]
if not matching_files:
raise FileNotFoundError(f"No matching file found for {gender}{year} in Template_{template_idx}")
target_file = matching_files[0] # 取第一个匹配的文件
# 读取文件内容
with zipf.open(target_file) as f:
for line in f:
parts = line.decode("utf-8").strip().split(",")
if len(parts) == 3 and parts[2] != 'freq':
texts.append(parts[0]) # 人名
freqs.append(int(parts[2])) # 频率
return texts, freqs
def ner_inference_errors(year, gender, template_idx):
texts, freqs = load_data_from_zip(zip_path, year, gender, template_idx)
# 进行 NER 预测
ner_results = [nlp(sentence) for sentence in texts]
# 重新格式化 NER 预测结果
preds = reformat_ner_results(ner_results)
return type1_error_weighted(freqs, preds), type2_error_weighted(freqs, preds), type3_error_weighted(freqs, preds)直接上测试,看看1880年的不同性别人名识别效果:
female_errors = ner_inference_errors(1880, "female", 1)
print(female_errors)
male_errors = ner_inference_errors(1880, "male", 1)
print(male_errors)结果如下:
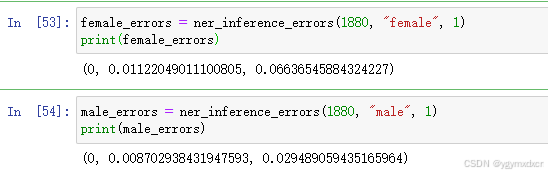
不关注错误类型1的话,从错误类型二和错误类型三来看,男生女生的姓名识别效果差别还真的较大。
最后,由于哈基作的电脑跑个1880年的数据都要个十几分钟,剩下的就不跑了,不然高低都要做个图看看区别,感兴趣的哈基人可以copy代码去试试,需要数据的话我放在baidu盘了。
通过网盘分享的文件:data_processed.zip
链接: https://pan.baidu.com/s/1Mqp1Arh_9LHaUYIkzCZ_Kw 提取码: Lql6

















 1598
1598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









