 R语言绘图与数据分析
R语言绘图与数据分析





4.1基本图形函数
R中绘图命令可以分为高级、低级和交互式。
简要的说,高级绘图命令可以在图形设备上绘制新图;低级绘图命令将在已经存在的图形上添加更多的绘图信息,如点、线、
多边形等;使用交互式绘图命令创建的绘图,可以使用如鼠标这类的定点装置来添加或提取绘图信息。在已有图形上添加信息一般要使用低级绘图命令。
4.1.1 高级绘图函数
一:R中常用的高级函数
| 绘图函数 | 说明 |
| plot() | 以x的元素值为纵坐标,序号为横坐标绘图 |
| barplot() | 条图 |
| pie() | 饼图 |
| hist() | 直方图 |
| qqnorm() | 正态分位数-分位数图 |
| dotchart() | 点图,如果x是数据框,做cleveland点图 |
| boxplot() | 盒形图 |
| plot(x,y) | x与y的二元作图 |
| matplot(x,y) | 二元图,x的第一列对应y的第一列,x的第二列对应y的第二列 |
| pairs() | 如果x是矩阵或是数据框,做x的各列之间的二元图,这等同plot |
| stripchart() | 把x的值画在一条线段上,样本含量较小时可作为盒形图的替代 |
| coplot(x~y|z) | 关于z的每个数值(或数值区间)绘制x与y的二元图 |
| symbols(x,y,...) | 由x和y给定坐标画符号,符号的类型、大小、颜色、等由另外的变量指定 |
| contour(x,y,z) | 等高线图(画曲线时用内插补充空白的值),x和y必须为向量,z必须为矩阵,使得dim(z)=c(length(x),length(y))(x和y可以忽略) |
| image(x,y,z) | 同contour()函数,但是实际数据大小用不同色彩表示 |
| persp(x,y,z) | 同contour()函数,但为三维透视图 |
二.高级函数的主要参数
每一个函数,在R里都可以在线查询其选项。某些绘图函数的部分选项是一样的,下面列出一些主要的共同选项及其缺省值:
type="p"指定图形的类型,‘p':点;’l‘:线;‘b’:点连线,‘o’:点连线,线在点上,‘h’:垂直线,‘s’:阶梯式,垂直线顶端显示数据,‘S':阶梯式,在垂直线底端显示数据。
xlim=,ylim=指定轴的上下限,例如xlim=c(1,10),或者xlim=range(x)
xlab=,ylab=坐标轴的标签,必须是字符型值。
main=主标题,必须是字符型值。
sub=副标题(用小字体)
add=FALSE,如果是TRUE,叠加图形到前一个图上(如果有的话)
axes=TRUE,如果是FALSE,不绘制轴与边框。
下面就一学生身高及其分组数据来对这些函数做些简单介绍。
(1)多图设置:mfrow。
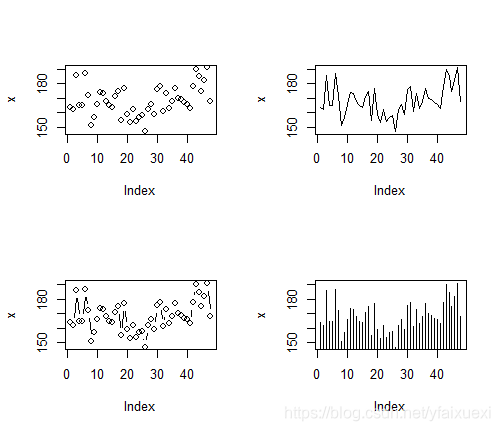
> x=ug$height
> plot(x)
> plot(x,type='l') #图的形状为线
> plot(x,type='b') #图的形状为点连线
> plot(x,type='h') #图的形状为垂直线。
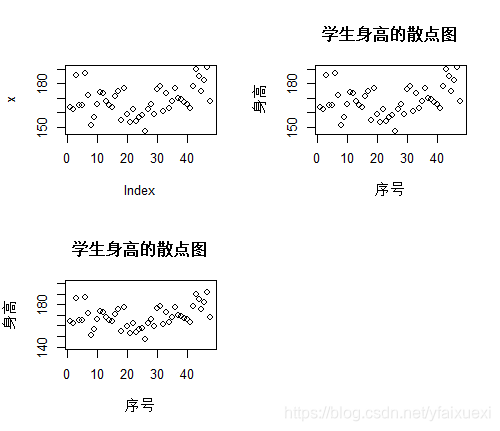
(2)图形修饰:xlab,ylab,ylim,main
> plot(x)
> plot(x,xlab='序号',ylab='身高',ylim=c(140,200),main='学生身高的散点图')
4.1.2 低级绘图函数
R里面有一套绘图函数是作用于现存的图形上的,称为低级作图命令,下面是一些常用的低级绘图函数。
| 绘图函数 | 说明 |
| points(x,y) | 添加点 |
| lines(x,y) | 添加线 |
| abline(a,b) | abline(h=y)在纵坐标y处画水平线,abline(v=x)在横坐标x处画垂直线,abline(obj)画obj确定的回归线 |
| segments(x0,y0,x1,y1) |
从(x0,y0)各点到(x1,y1)各点画线段
|
| title() | 添加标题,也可添加一个副标题 |
| legend(x,y,legend) | 在点(x,y)处添加图例,说明内容由legend给定 |
| text(x,y,labels,...) | 在(x,y)处添加用labels指定的文字 |
| polygon(x,y) | 绘制连接各x,y坐标确定的点的多边形 |
| rect(x1,y1,x2,y2) |
绘制长方形,(x1,y1)为左下角,(x2,y2)为右上角
|
| axis(side,vect) | 画坐标轴,side=1时画在下边,side=2时画在左边,side=3时画在上边,side=4时画在右边,可选参数at指定画刻度线的位置 |
| box() | 在当前的图上加上边框 |
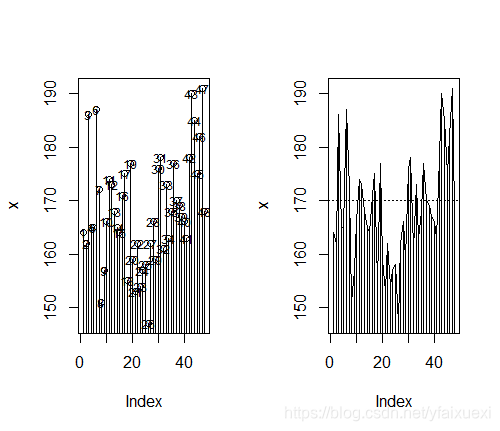
> par(mfrow=c(1,2))
> plot(x,type='h')
> text(x,cex=0.75)
> points(x)
> plot(x,type='h')
> lines(x)
> abline(h=170,lty=3)
4.1.3 绘图函数参数
除了低级作图命令之外,图形的显示也可以用绘图参数来改良。绘图参数可以作为图形函数的选项(但不是所有参数都可以这样用),也可以用函数par来永久地改变绘图参数,也就是说后来的图形都将按照par指定的参数来绘制。
例如命令par(bg=“yellow”)将使之后的图形都以黄色的背景来绘制。有73个绘图函数,其中一些有非常相似的功能。
具体见书的57页
二.参数设置的用法
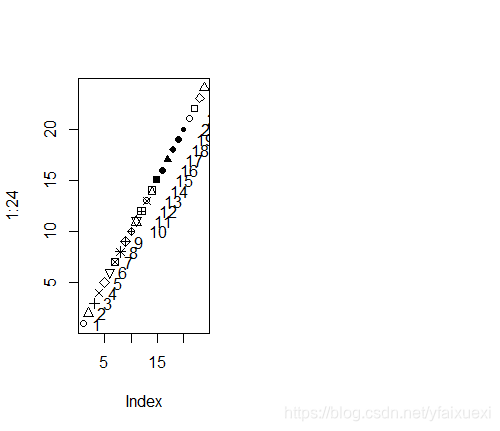
1.符号参数pch
pch是plotting character 的缩写,pch符号可以使用“0:25”来表示26个标识。当然符号也可以使用#,*,|,+,-,:,0,等来表示,值得注意的是,21:25这几个符号可以在points函数使用不同的颜色填充(bg=参数)。例如使用
> plot(1:24,pch=1:24)
> text(1:24,adj=-1)
可产生以下图标
2.在同一画面画出多张图
(1)修改绘图参数,如par(mfrow=c(2,2))或par(mfcol=c(2,2))就是将屏幕分成四块
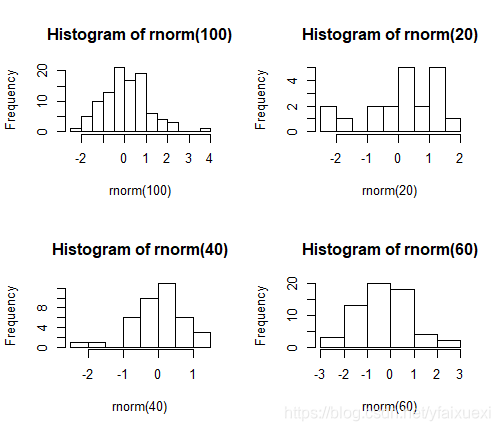
(2)功能更强大的layout函数,他可以设置图形绘制顺序和图形大小,可任意分割屏幕,layout(matrix(1:4,2,2))等价于par(mfrow=c(2,2))
> layout(matrix(c(1,1,1,2,3,4,2,3,4),nr=3,byrow=T))
> hist(rnorm(100))
> hist(rnorm(20))
> hist(rnorm(40))
> hist(rnorm(60))
> layout(1)
3.设置图形边缘大小和字体参数
修改绘图参数命名为par(mar=c(bottom,left,top,right)),bottom,left,top,right四个参数分别是距离bottom,left,top,right的长度,默认距离是c(5,4,4,2)+0.1.或者修改绘图参数par(mai=c(bottom,left,top,right))以英寸为单位来指定边际大小,cex可改变图形的字体大小。
> par(mfrow=c(1,2))
> plot(x)
> par(mar=c(4,4,2,1)+0.1,cex=0.75)
> plot(x)
> par(mfrow=c(1,1))
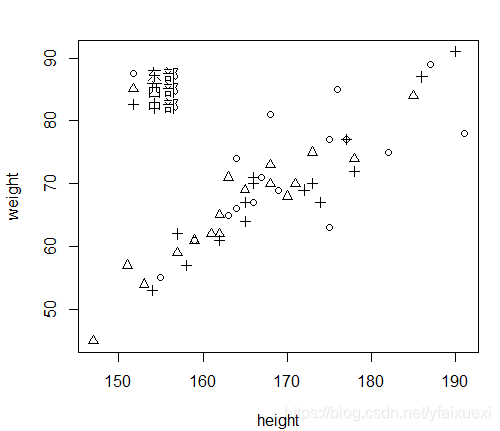
4.加图例函数
绘制图形后,使用legend函数,help(“legend”)
> with(ug,{plot(height,weight);
+ plot(height,weight,pch=as.numeric(region));
+ legend(150,90,levels(region),pch=1:3,bty='n')})
4.2 单变量(向量)数据分析
| 函数 | 用途表 |
| table() | 频数表 |
| length() | 向量长度 |
| min() | 最小值 |
| max() | 最大值 |
| sum() | 求和 |
| mean() | 求平均值 |
| median() | 中位数 |
| quantile() | 分位数 |
| var() | 方差 |
| sd() | 标准差 |
| range() | 极差 |
| IQR() | 四分位数 |
| sort() | 排序 |
| rank() | 编秩 |
| prod() | 求积 |
| summary() | 综合统计量 |
| cut() | 分组函数 |
4.2.1 计数数据分析
统计学把取值范围是有限个的变量或由一个数列构成的变量称为离散变量,其中表示分类情况的离散变量又称为分类变量。对于分类数据我们可以用频数表分析,可以用条图和饼图来描述。
一、分类频数表(table())
> t1=table(ug$region)
> t1
东部 西部 中部
16 17 15
二、分类条图(barplot())
条图(barplot)的高度可以使频数和频率,图的形状看起来是一样,但是刻度不一样。对分类数据做条图,需先对原始数据分组,否则
做出的不是分类数据的条图。

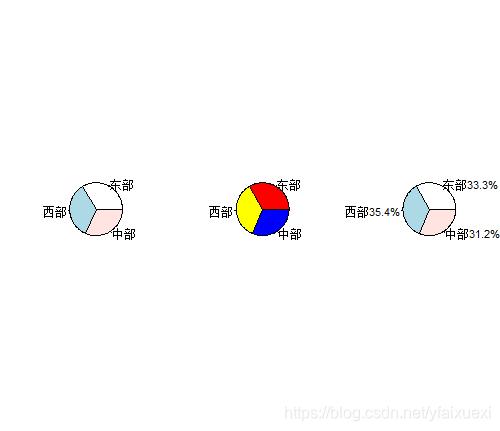
三、分类饼图(pie())
> par(mfcol=c(1,3))
> pie(t1)
> pie(t1,col=c("red","yellow","blue"))
> pct=round(t1/sum(t1)*100,1)
> lbs=paste(names(t1),pct,"%",sep="")
> pie(t1,lbs)
4.2.2计量数据分析
一:集中趋势和离散程度
对于数值型数据经常要分析其分布的集中趋势和离散程度,用来描述集中趋势的主要有均值、中位数;描述离散程度的主要有方差、标准差。
二:茎叶图
使用stem()函数
> stem(ug$height)
The decimal point is 1 digit(s) to the right of the |
14 | 7
15 | 134
15 | 577899
16 | 12223344
16 | 55566678889
17 | 012334
17 | 5567788
18 | 2
18 | 567
19 | 01
三:数值分类函数
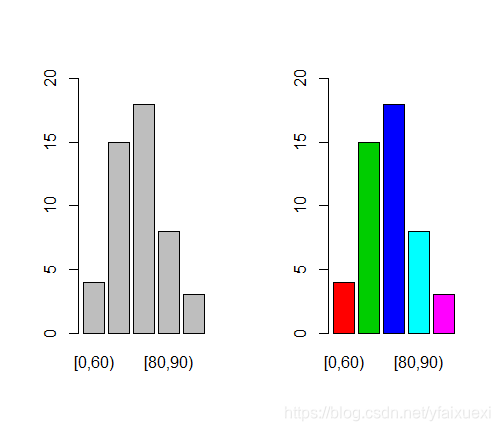
统计分析中经常碰到要对数值数据进行分组的情况,在R中可以用cut()函数对数值数据进行分组。
> score_c=cut(ug$score,breaks=c(0,60,70,80,90,100))
> table(score_c)
score_c
(0,60] (60,70] (70,80] (80,90] (90,100]
4 15 18 8 3
很显然,上面的分组不符合常规要求,需右开口,设置right=FALSE.
> score_c=cut(ug$score,breaks=c(0,60,70,80,90,100),right=FALSE)
> table(score_c)
score_c
[0,60) [60,70) [70,80) [80,90) [90,100)
4 15 18 8 3
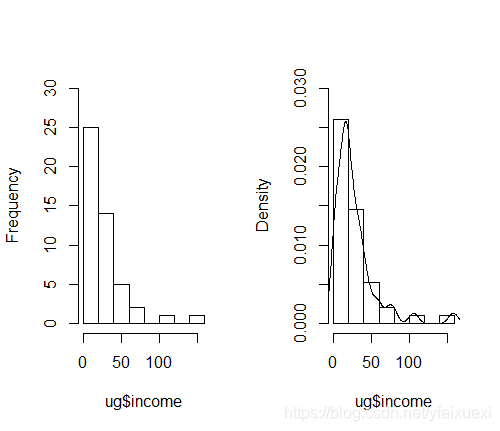
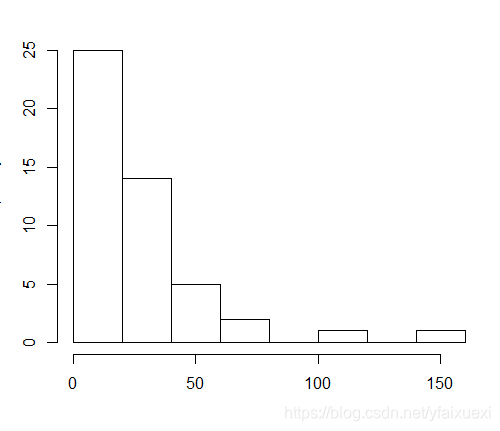
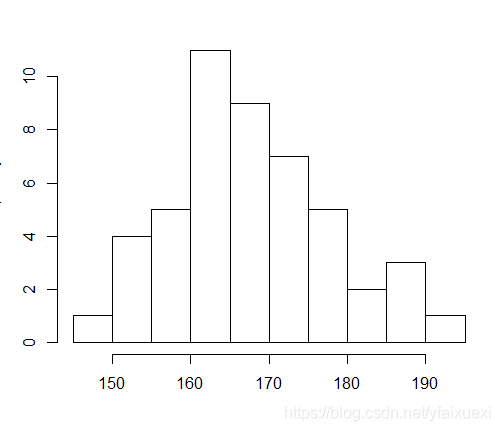
四:直方图(histgram)
直方图用于表示连续性变量的频数分布,实际应用常用于考察变量的分布是否服从某种分布类型,如正态分布,R里用来做直方图的函数是hist(),也可以用频率做直方图,在R中做频率直方图很简单,只要把probability参数设置为T(默认为F)就可以了。
例如对学生的家庭收入和身高数据做直方图。
> hist(ug$income,ylim=c(0,30),main="")
> hist(ug$income,prob=T,ylim=c(0,0.03),main="")
> lines(density(ug$income)) #增加概率密度曲线
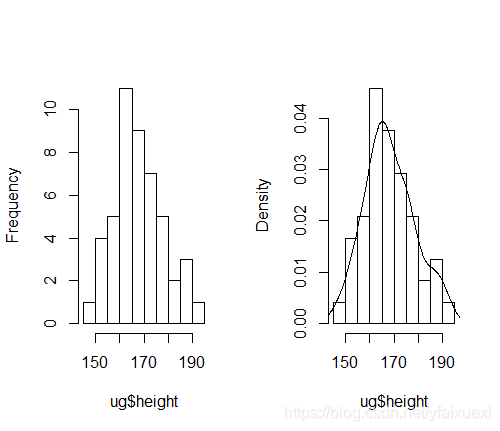
> hist(ug$height,main="")
> hist(ug$height,prob=TRUE,main="")
> lines(density(ug$height))
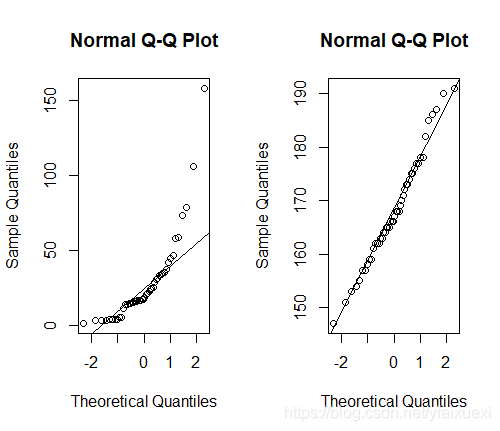
五.正态概率图(QQ图)
正态概率QQ图展示的是样本的累积频率分布与理论正态分布的累积概率分布之间的关系,它是由标准正态分布的分位数为横坐标,样本值为纵坐标的散点图。要利用QQ图鉴别样本数据是否近似于正态分布,只需看QQ图上的点是否近似地在一条直线附近,并且该直线的斜率为标准差,截距为均值。如果图中各点为直线或接近直线,则样本的正态分布假设可以接受。
> qqnorm(ug$income)
> qqline(ug$income)
> qqnorm(ug$height)
> qqline(ug$height)
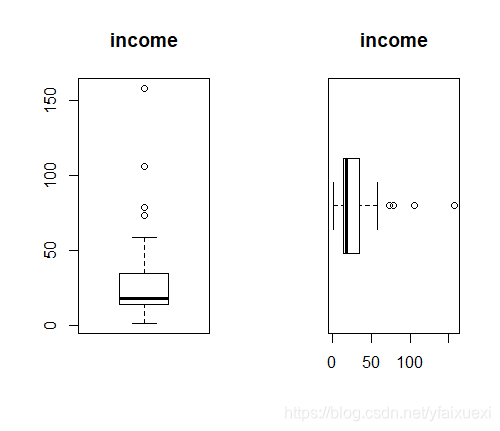
六:箱式图(Boxplot Graph)
箱式图和直方图一样是用于考察连续变量的分布情况,但它的功能和直方图并不重叠,直方图侧重于对一个连续变量的分布情况进行详细考察,而箱式图更注重于勾勒出统计的主要信息,并且便于对多个连续变量同时考察,或者对一个变量分组进行考察,在使用上要比直方图更为灵活,用途也更为广泛。在R里做箱式图的函数是boxplot(),而且可以设置垂直型和水平型,默认是垂直型,要得到水平式箱式图,只要把参数horizontal设为T就可以了。
> boxplot(ug$income,main='income')
> boxplot(ug$income,main='income',horizontal=T)
4.2.3 分析函数构建
实际上数据统计分析首先就是对数据的探索性数据分析。探索性数据分析是通过分析数据集以决定选择哪种方法适合统计推断的过程。
一、基本统计量
均值、中位数、极差、方差、标准差、四分位数间距
> statl<-function(x){
+ cat('n=',length(x),'\n')
+ cat('min=',min(x),'\n')
+ cat('max=',max(x),'\n')
+ cat('mean=',mean(x),'n')
+ cat('sd=',sd(x),'\n')
+ cat('median=',median(x),'\n')
+ cat('IQR',IQR(x),'\n')
+ }
> statl(ug$height)
n= 48
min= 147
max= 191
mean= 168.2083 nsd= 10.23544
median= 166.5
IQR 13
显然这个函数对结果的显示不够简练,我们可以编写一个更简化的形式。
> statl2<-function(x){
+ c(n=length(x),min=min(x),max=max(x),mean=mean(x),
+ sd=sd(x),median=median(x),IQR=IQR(x))
+ }
> statl2(ug$height)
n min max mean sd median IQR
48.00000 147.00000 191.00000 168.20833 10.23544 166.50000 13.00000
当然这个函数也存在很大问题,例如它只能计算向量或变量数据,无法计算矩阵或数据框的数据。
二、探索性统计图
探索性数据分析的工具包括数据的图形表示和解释,主要的图形表示方法有(括号中为R语言绘图函数命令):
(1)条图(barplot):用于数据分类。
(2)直方图(hist)、点图(dotchart)、茎叶图(stem):用于观察数值型分布的形状
(3)箱式图(boxplot):给出数值型分布的汇总数据,适用于不同分布的比较和拖尾、截尾分布的识别
(4)正态分布QQ图(qqnorm):用于观察数据是否近似地服从正态分布
我们编制的EDA函数就能做到这一点
三:频数表构造函数
1:构造技术频数表函数
(1)生成性别频数表:
> Ftab(ug$sex) #library(dstatR)
例数 构成比(%)
男 25 52.08
女 23 47.92
合计 48 100.00
(2)生成来源地频数表
> Ftab(ug$region)
例数 构成比(%)
东部 16 33.33
西部 17 35.42
中部 15 31.25
合计 48 100.00
2.构造计量频数表函数
(1)生成家庭收入频数表
> Freq(ug$income)
组中值 频数 频率(%) 累计频数(%)
1 10 25 52.083333 52.08
2 30 14 29.166667 81.25
3 50 5 10.416667 91.67
4 70 2 4.166667 95.83
5 90 0 0.000000 95.83
6 110 1 2.083333 97.92
7 130 0 0.000000 97.92
8 150 1 2.083333 100.00
(2)生成身高频数表
> Freq(ug$height)
组中值 频数 频率(%) 累计频数(%)
1 147.5 1 2.083333 2.08
2 152.5 4 8.333333 10.42
3 157.5 5 10.416667 20.83
4 162.5 11 22.916667 43.75
5 167.5 9 18.750000 62.50
6 172.5 7 14.583333 77.08
7 177.5 5 10.416667 87.50
8 182.5 2 4.166667 91.67
9 187.5 3 6.250000 97.92
10 192.5 1 2.083333 100.00
4.3多变量(数据框)数据分析
R提供了很多很多变量(矩阵和数据框)的分析函数,下面列出几个常用函数,见下表
| 函数 | 用途 |
| dim() | 维度 |
| nrow() | 行数 |
| ncol() | 列数 |
| table() | 列联表 |
| addmarging() | 列联表的边际和 |
| prop.table() | 列联表概率 |
| xtabs() | 列联表table的公式形式 |
| ftable() | 紧凑式列联表 |
| summary() | 综合统计 |
| scale() | 数据标准化 |
| by() | 分组统计 |
| aggaregate() | 聚集统计量 |
| apply() | 应用函数 |
4.3.1计数类数据分析
一、列联表
R的table()函数可以把双变量分类数据整理为二维表形式,table命令处理双变量数据类似于处理单变量数据,只是参数由原来的一个变成了两个。
> tsr=table(ug$sex,ug$region)
> tsr
东部 西部 中部
男 6 13 6
女 10 4 9
> prop.table(tsr) #总的构成比
东部 西部 中部
男 0.12500000 0.27083333 0.12500000
女 0.20833333 0.08333333 0.18750000
> prop.table(tsr,1) #按行构成比
东部 西部 中部
男 0.2400000 0.5200000 0.2400000
女 0.4347826 0.1739130 0.3913043
> prop.table(tsr,2) #按列构成比
东部 西部 中部
男 0.3750000 0.7647059 0.4000000
女 0.6250000 0.2352941 0.6000000
二、复式条图
> barplot(tsr,ylim=c(0,25),beside=T,legend.text=levels(ug$sex))
> barplot(tsr,ylim=c(0,25),legend.text=levels(ug$sex))
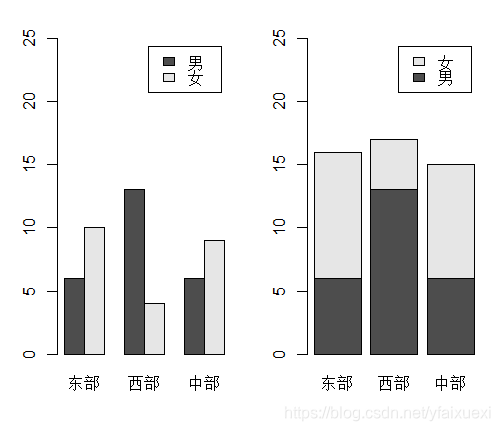
其中beside参数设置为FALSE时,作出的图是分段式条图,TRUE时作出的条图是并列式,R默认的是False。参数legend.text表示为图添加图例说明
table()函数还可以生成多维表,假如存在x,y,z三个变量,table(x,y)则生成x,y二维表,table(x,y,z)生成每个z值关于x,y的二维表。
> ug$income_c=cut(ug$income,breaks=c(0,5,50,200),
+ labels=c("低收入","中等收入","高收入"))
> table(ug$income_c)
低收入 中等收入 高收入
9 33 6
> table(ug$region,ug$income_c)
低收入 中等收入 高收入
东部 2 11 3
西部 4 13 0
中部 3 9 3
> table(ug$region,ug$income_c,ug$sex)
, , = 男
低收入 中等收入 高收入
东部 0 5 1
西部 4 9 0
中部 1 3 2
, , = 女
低收入 中等收入 高收入
东部 2 6 2
西部 0 4 0
中部 2 6 1
下面我们用命令ftable形成紧凑型列联表
> ftable(ug$sex,ug$region,ug$income_c)
低收入 中等收入 高收入
男 东部 0 5 1
西部 4 9 0
中部 1 3 2
女 东部 2 6 2
西部 0 4 0
中部 2 6 1
多变量数据统计分析中经常用到复式条图,复式条图是指两个或两个以上小直条组成的条图。与简单型条图相比,复式条图多考察了一个分组因素,常用于考察比较两组研究对象的某观察指标。做复式条图之前应先对数值数据进行分组,然后用table()函数做频数表,做复式条图的函数时barplot(),R默认的是分段式条图,要做并列式复式条图,要设置参数beside=TRUE,例如
> attach(ug)
> barplot(table(region,ug$income_c),legend.txt=levels(region))
> barplot(table(region,ug$income_c),beside=TRUE,legend.txt=levels(region))
> detach(ug)
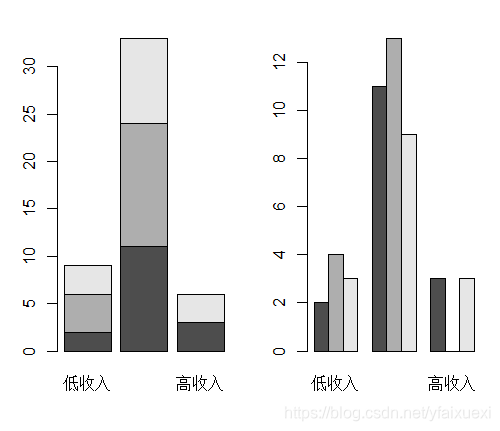
4.3.2 计量类数据分析
一:双变量散点图
> plot(ug$height,ug$weight) #等价于plot(height,weight,data=ug)
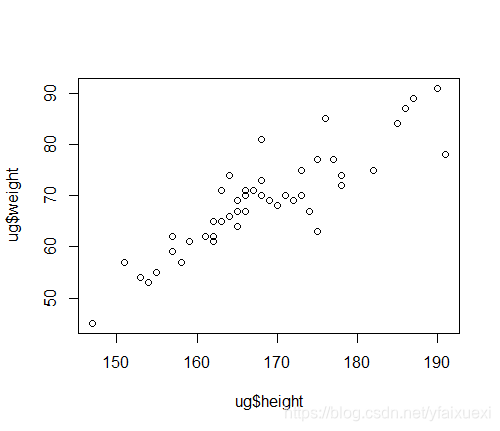
二.多变量散点图
当同时考察三个或三个以上的数值变量间的相关关系时,若一一绘制他们之间的简单散点图,十分麻烦,利用矩阵式散点图比较合适,这样可以快速发现多个变量间的主要相关性,R作矩阵式散点图的函数是plot()或pairs()。
> pairs(ug[,c("income","height","weight","score")],gap=0 )
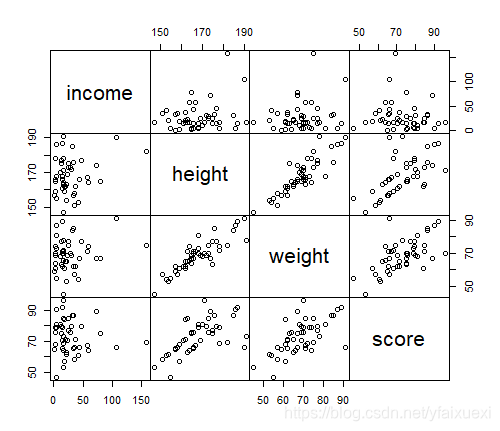
4.3.3计数计量数据分析
一:分组函数
> bism=by(ug$height,ug$sex,mean)
> bism
ug$sex: 男
[1] 170.6
---------------------------------------------------------
ug$sex: 女
[1] 165.6087
> barplot(bism,ylim=c(0,200),col=1:2)
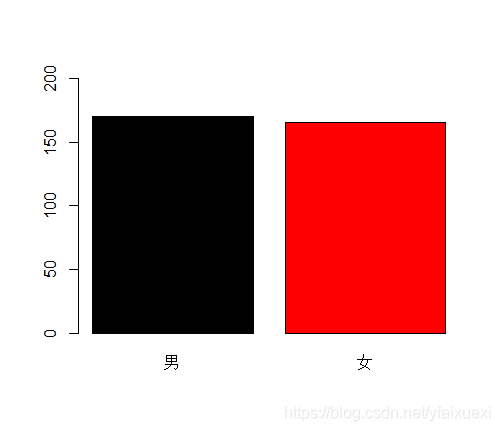
(1)按性别要求求身高的基本统计量。
> by(ug$height,ug$sex,summary)
ug$sex: 男
Min. 1st Qu. Median Mean 3rd Qu. Max.
147.0 162.0 173.0 170.6 178.0 191.0
---------------------------------------------------------
ug$sex: 女
Min. 1st Qu. Median Mean 3rd Qu. Max.
154.0 162.5 165.0 165.6 168.5 185.0
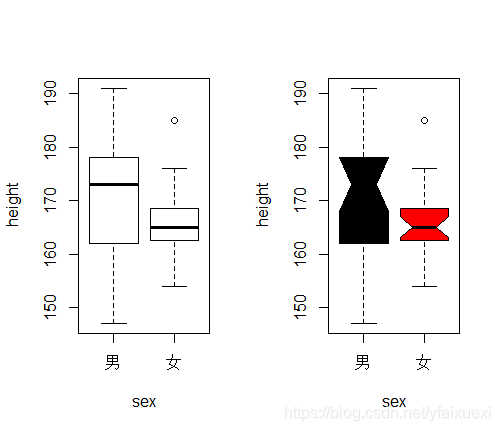
(2)按性别分类求身高的箱式图。
> par(mfrow=c(1,2))
> boxplot(height~sex,data=ug)
> boxplot(height~sex,data=ug,notch=T,col=1:2)
(3)按来源地分类求家庭收入的基本统计量
> by(ug$income,ug$region,summary)
ug$region: 东部
Min. 1st Qu. Median Mean 3rd Qu. Max.
4.10 16.15 23.25 34.99 44.83 158.00
---------------------------------------------------------
ug$region: 西部
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.10 5.50 16.10 17.54 25.30 42.10
---------------------------------------------------------
ug$region: 中部
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.90 14.65 21.40 31.96 34.00 105.90
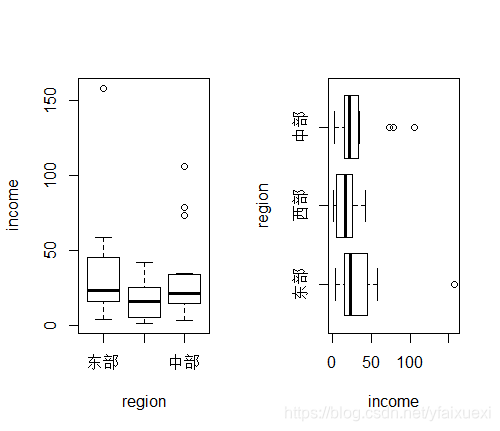
(4)按来源地分类求家庭收入的箱式图
> boxplot(income~region,data=ug)
> boxplot(income~region,data=ug,horizontal = T)
(5)按性别和来源地分类求家庭收入的基本统计量
> by(ug$income,list(ug$sex,ug$region),summary)
: 男
: 东部
Min. 1st Qu. Median Mean 3rd Qu. Max.
13.80 15.40 21.00 45.83 41.00 158.00
---------------------------------------------------------
: 女
: 东部
Min. 1st Qu. Median Mean 3rd Qu. Max.
4.10 17.00 23.25 28.48 41.73 58.30
---------------------------------------------------------
: 男
: 西部
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.10 3.80 16.10 17.32 25.30 42.10
---------------------------------------------------------
: 女
: 西部
Min. 1st Qu. Median Mean 3rd Qu. Max.
11.20 13.45 15.20 18.25 20.00 31.40
---------------------------------------------------------
: 男
: 中部
Min. 1st Qu. Median Mean 3rd Qu. Max.
4.10 14.28 15.75 38.07 58.77 105.90
---------------------------------------------------------
: 女
: 中部
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.90 17.50 28.30 27.89 33.30 78.80
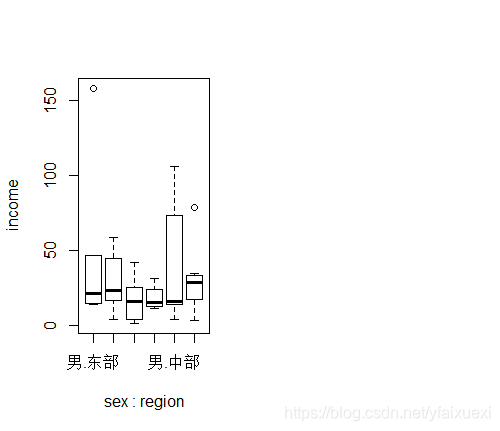
(6)按性别和来源地分类的求家庭收入的箱式图
> boxplot(income~sex+region,data=ug)
二.点带图函数
忽略
三.分组散点图
1.重叠散点图
有时出于研究需要,需将两个变量或多组两个变量的散点图按某一分组变量绘制在同一个图中,这样可以更好的比较他们之间的关系,这时就可以绘制重叠散点图。
> plot(ug$height,ug$weight)
> text(ug$height,ug$weight,col=1:2,adj=-0.5,cex=0.75)
> plot(ug$height,ug$weight)
> text(ug$height,ug$weight,ug$ex,adj=-0.5,cex=0.75)
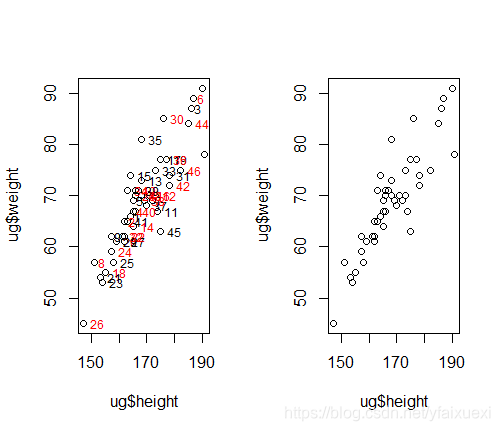
2.分层散点图
> coplot(weight~height|sex,data=ug)
> coplot(weight~height|region,data=ug,rows=1)
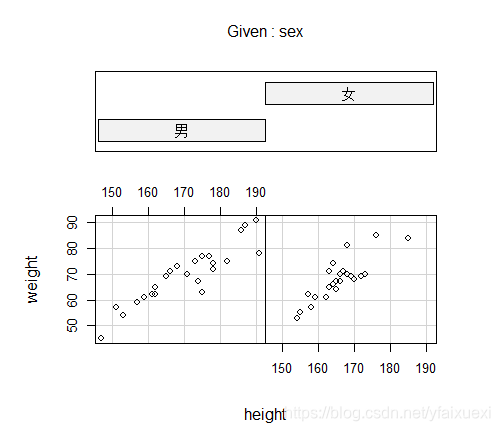
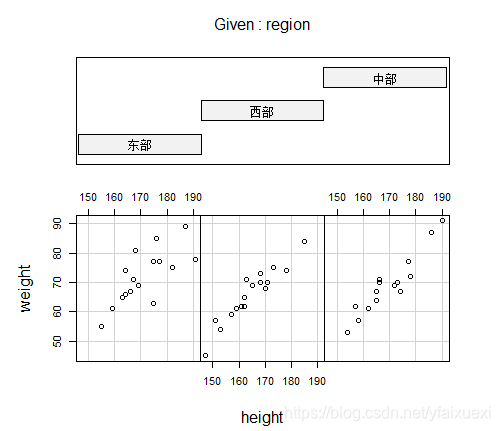
4.3.4应用类函数的应用
本文对apply函数做一个简单的归纳,以便大家理解其中各函数的区别所在
一:矩阵应用函数
apply()函数的处理对象是数据框(矩阵)或数组,它逐行或逐列的处理数据,其输出结果是一个向量或矩阵,下面的例子是对数据框ug
的每一列求均值
> ug1=ug[,6:9]
> apply(ug1,2,mean) #margin=2意味着对列求均值。
income height weight score
27.86250 168.20833 68.95833 73.21250
二:列表应用函数
lapply()的处理对象是向量、列表或其他对象,它将向量中的每个元素作为参数,输入到处理函数中,最后生成结果的格式是列表。在R中数据框是一种特殊的列表,所以数据框的列也将作为函数的处理对象,下面的例子即对一个数据框按列来计算其中位数与标准差。
> lapply(ug1,function(x) list(mean=mean(x),sd=sd(x))
+ )
$income
$income$mean
[1] 27.8625
$income$sd
[1] 28.7869
$height
$height$mean
[1] 168.2083
$height$sd
[1] 10.23544
$weight
$weight$mean
[1] 68.95833
$weight$sd
[1] 9.635834
$score
$score$mean
[1] 73.2125
$score$sd
[1] 10.46462
sapply()可能是使用最为频繁的向量化函数了,它和lapply()非常相似,但其输出格式则是较为友好的矩阵格式
> sapply(ug1,function(x) list(mean=mean(x),sd=sd(x)))
income height weight score
mean 27.8625 168.2083 68.95833 73.2125
sd 28.7869 10.23544 9.635834 10.46462
三、分组应用函数
tapply()的功能则有所不同,她是专门用来处理分组数据的,其参数要比sapply多一个。其输出结果是数组模式
> tapply(ug$height,INDEX=ug$sex,FUN=mean)
男 女
170.6000 165.6087
四:聚集应用函数
与tapply()的功能非常相似的还有aggregate(),其输出是更友好的数据框格式,by()的功能也和前面两个函数类似
> aggregate(ug1,by=list(ug$sex),FUN=mean)
Group.1 income height weight score
1 男 29.14400 170.6000 70.00000 74.35200
2 女 26.46957 165.6087 67.82609 71.97391
> aggregate(ug1,by=list(sex=ug$sex,region=ug$region),FUN=mean)
sex region income height weight score
1 男 东部 45.83333 181.1667 76.50000 77.75000
2 女 东部 28.48000 165.1000 69.40000 66.58000
3 男 西部 17.32308 162.0769 63.53846 71.80000
4 女 西部 18.25000 171.5000 73.25000 82.67500
5 男 中部 38.06667 178.5000 77.50000 76.48333
6 女 中部 27.88889 163.5556 63.66667 73.21111

















 9630
9630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









