







 本文深入解析了深度学习中感知机的工作原理,通过图解详细展示了感知机如何通过调整权重和偏置项最小化预测误差。并通过代码实现了感知机的学习过程,演示了其在简单数据集上的应用。
本文深入解析了深度学习中感知机的工作原理,通过图解详细展示了感知机如何通过调整权重和偏置项最小化预测误差。并通过代码实现了感知机的学习过程,演示了其在简单数据集上的应用。
感知机的理解
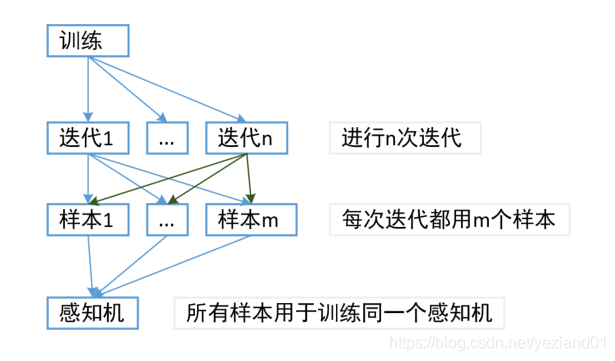
对深度学习中的感知机的理解可以用下图说明:

它的目标在于尽可能让预测值r与真实值y接近,或者完全相等,即最小化y与r的差异delta。
而激活函数是可以任意选择的,关键在于线性处理中的w和b如何确定。
通过链式求导法则,可以求出w的变化而导致delta的变化幅度,同样可以求出b的变化而导致delta的变化幅度。
也就是更改w或b,就可以改变delta。那么反过来,改变delta,也就可以改变w和b。
所以,通过确定delta来确定w和b。
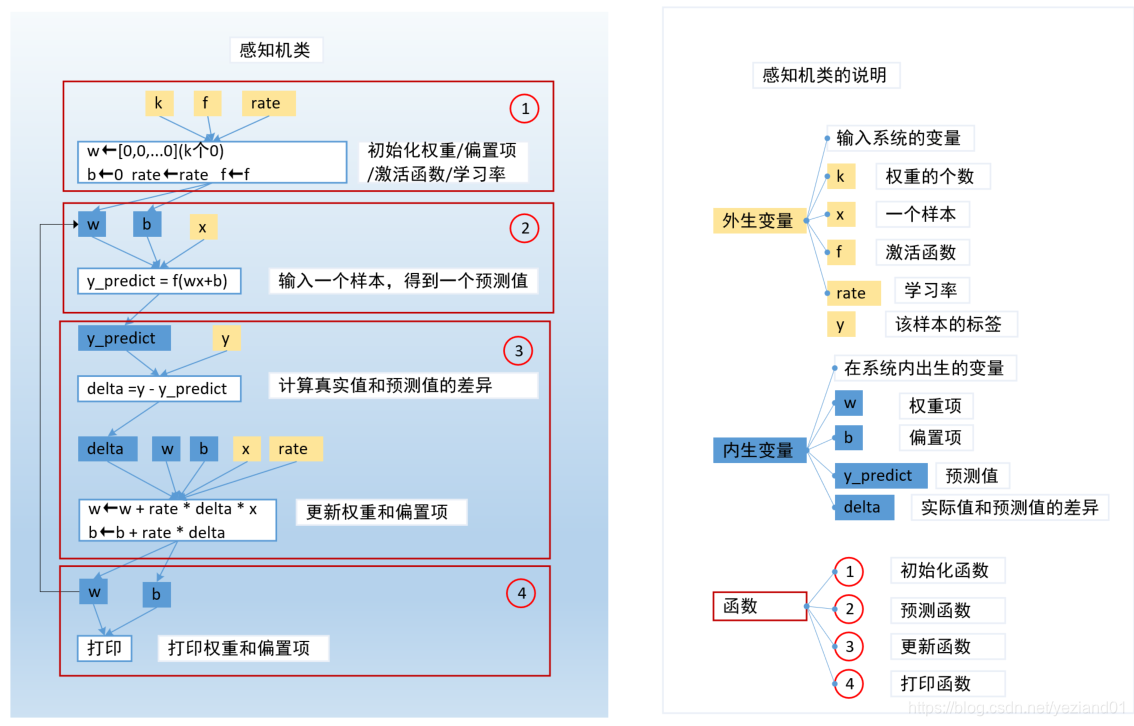
感知机的实现代码
"""
创建感知机类
属性是激活函数,学习率,权重,偏置项
方法是
1.初始化:传入激活函数,学习率,权重个数;初始化权重,偏置项为0
2.预测:传入一个样本,输出一个预测值
3.更新权重和偏置项:传入预测值,计算新的权重和偏置项
4.打印:打印权重,偏置项
"""
class perceptron(object):
def __init__(self, w_num, rate, activator):
"""
初始化感知机
:param w_num: 权重个数
:param rate: 学习率
:param activator: 激活函数
"""
self.rate = rate #传入学习率
self.activator = activator #传入激活函数
self.bias = 0.0 #偏置项初始化为0
self.weights = [0.0 for x in range(w_num)] #权重初始化为0
def predict(self, sample):
"""
预测一个样本
:param sample: 被预测的一个样本
:return: 通过激活函数后的预测值
"""
sum = 0
for feature, weight in zip(sample, self.weights): #实现wx
sum += feature * weight
sum += self.bias #实现wx+b
y_predict = self.activator(sum) #激活
return y_predict #返回预测值
def update(self, sample, label):
"""
用一个样本来更新权重和偏置项
:param sample: 一个样本
:param label: 它的标签
:return:
"""
output = self.predict(sample) #得到该样本的预测值
delta = label - output #预测值和真实值的差异
self.bias += delta * self.rate #更新偏置项
self.weights = [w + self.rate * delta * x for x, w in zip(sample, self.weights)] #更新权重
def print(self):
print("weight\t:%s\n bias\t:%f\n" % (self.weights, self.bias)) #打印偏置项和权重
"""
创建迭代训练感知机函数
输入:指定感知机,多个样本点,对应的标签,指定迭代次数
输出:训练好的感知机,主要是权重,偏置项
"""
def activator(x):
"""
创建激活函数-阶跃函数
:param x: 自变量
:return: 若x为正数,则返回值是1;若x为负数,则返回值是0
"""
return 1 if x > 0 else 0
if __name__ == '__main__':
samples = [[1, 1], [0, 0], [1, 0], [0, 1]] #多个样本
labels = [1, 0, 0, 0] #标签
p = perceptron(2, 0.1, activator) #创建一个感知机,每个样本有2个特征,学习率是0.1,激活函数是activator
for i in range(10): #迭代10次
for sample, label in zip(samples, labels): #每次迭代中,所有样本均参与
p.update(sample, label) #每次用一个样本更新权重和偏置项
p.print() #打印10次迭代后的权重和偏置项
#预测
print('1 and 1 = %d' % p.predict([1, 1]))
print('1 and 1 = %d' % p.predict([0, 0]))
print('1 and 1 = %d' % p.predict([1, 0]))
print('1 and 1 = %d' % p.predict([0, 1]))
感知机的代码图解
《图解深度学习》_张弥-完整书签
BAIDU:https://pan.baidu.com/s/1xHEsHIdDRFnX3ZErTPBsOQ
TiQu:vj0m

















 8331
8331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









