



 本文详细介绍了Transformer神经网络模型,包括其结构(编码器-解码器)、自注意力机制(处理序列依赖)、多头注意力、位置编码以及残差连接和层归一化的应用。同时提到了NodeFormer架构的发展。
本文详细介绍了Transformer神经网络模型,包括其结构(编码器-解码器)、自注意力机制(处理序列依赖)、多头注意力、位置编码以及残差连接和层归一化的应用。同时提到了NodeFormer架构的发展。
前置知识-Transformer:
Transformer 是一种使用注意力机制(attention mechanism)的神经网络模型,能够有效地处理序列数据,如句子或文本。
Transformer由编码器和解码器组成。编码器负责将输入序列转化为抽象的表示,而解码器则根据这个表示生成目标序列。
自注意力机制是什么?
自注意力机制(Self-Attention):传统的循环神经网络(RNN)在处理序列数据时需要按顺序逐个处理输入,容易造成并行计算的困难。而自注意力机制允许模型在一个序列中的不同位置之间建立直接的关联,从而可以同时处理整个序列。通过计算每个位置与其他位置之间的相关性分数,自注意力机制能够捕捉到输入序列中的长距离依赖关系。[建立不同位置的词之间的直接关联]
在编码器中,我们需要计算注意力得分。
这是通过计算查询(query)与键(key)之间的相似度,再乘以值(value)来实现的。然后,我们将这些注意力得分进行归一化处理,并将其加权求和。这个过程可以使用下面的公式表示:
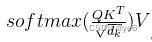
其中,Q表示查询向量,K表示键向量,V表示值向量,d_k表示维度数。
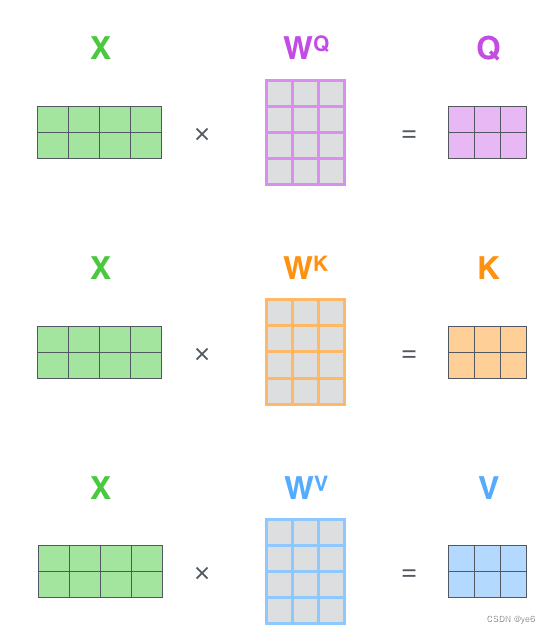
Q、K、V概念来源于检索系统,其中Q为Query、K为Key、V为Value。可以简单理解为Q与K进行相似度匹配,匹配后取得的结果就是V;
WQ、WK、WV都是可以学习的参数矩阵;
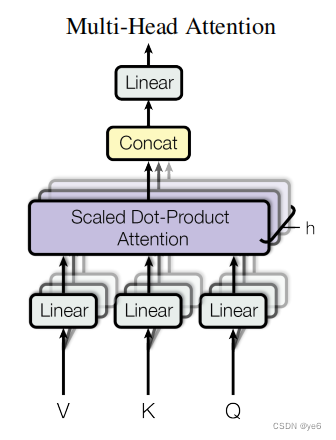
多头 是什么含义?
多头的机制能够联合来自不同head(关注不同的子空间)部分学习到的信息,这就使得模型具有更强的认识能力。
具体的数学公式:
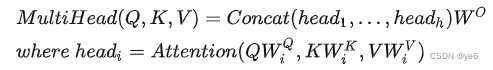
Q、K、V经过Linear然后经过h个Self-Attention,得到h个输出,其中h指的是注意力的头数。h个输出进行Concat然后过Linear得到最终结果。

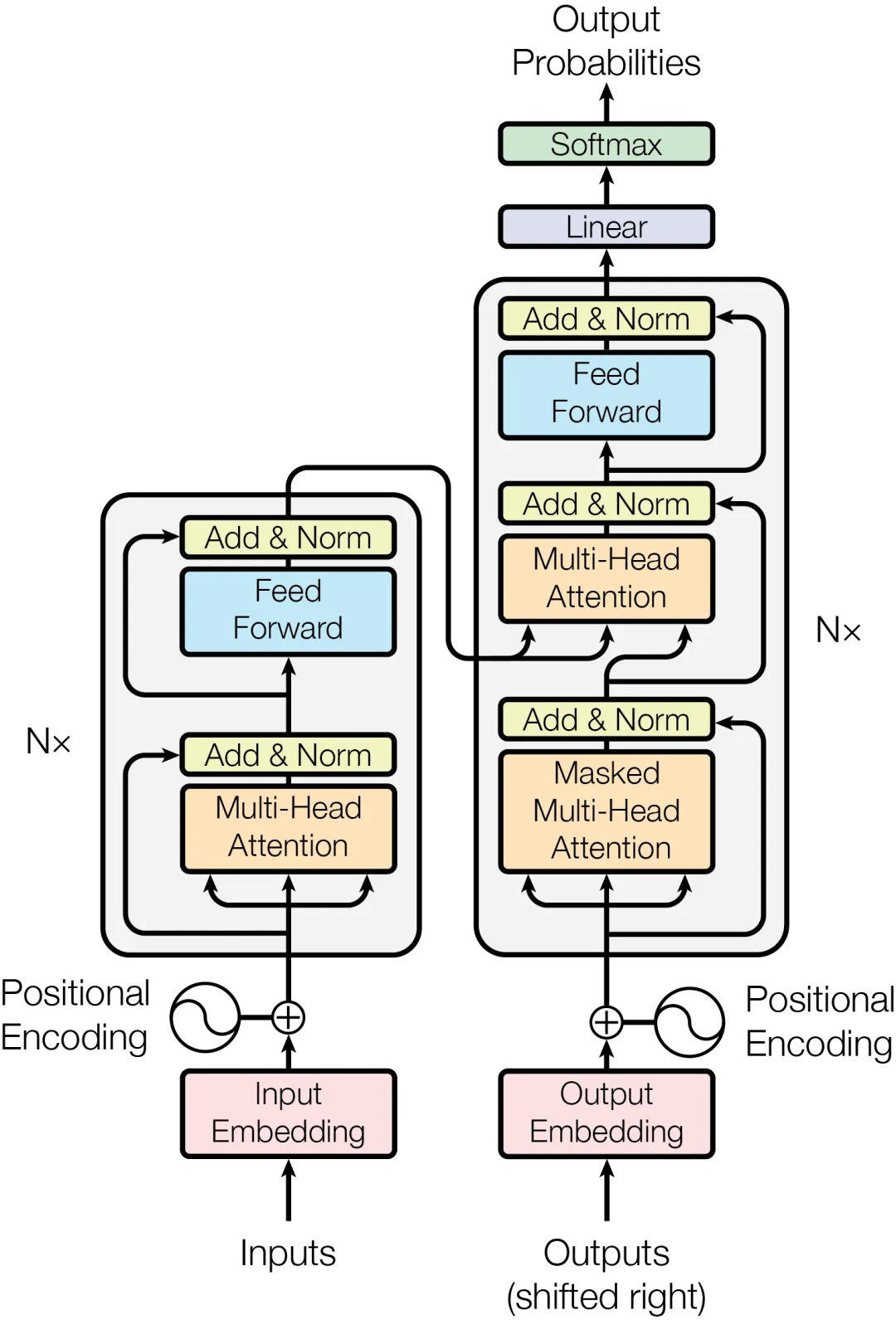
transformer论文中的结构:
Decoder中mask multi-head attention的作用是什么
在自注意力机制中屏蔽(或遮蔽)未来位置的信息,以防止模型在生成序列时能够“看到”未来的信息。
具体来说,掩码多头注意力的作用是在生成每个位置的输出时,将该位置后面的位置的注意力权重设为负无穷或0,从而屏蔽未来位置的信息。
一些关于Transform架构的解释:
编码器-解码器结构:Transformer使用编码器-解码器结构来进行序列到序列的任务,如机器翻译。编码器负责将输入序列编码成一个中间表示,解码器则根据这个中间表示生成输出序列。编码器和解码器都由多个层堆叠而成,每一层都包含多头自注意力机制和前馈神经网络。
多头注意力机制(Multi-Head Attention):为了增强模型对不同位置的关联性的建模能力,Transformer引入了多头注意力机制。在多头注意力中,模型使用多组不同的注意力权重来进行自注意力计算,然后将它们的结果进行拼接和线性变换,以获得最终的注意力表示。
位置编码(Positional Encoding):由于Transformer没有显式的循环或卷积结构,它无法捕捉到输入序列中的位置信息。为了解决这个问题,Transformer使用位置编码来为每个输入位置提供一个表示其相对位置的固定向量。这样,模型就能够感知到序列中不同位置的顺序关系。
残差连接和层归一化:为了避免深层网络中的梯度消失或爆炸问题,Transformer使用残差连接和层归一化。残差连接允许信息直接跳过每个层,并与层内的输出相加。层归一化则对每个层的输出进行归一化,有助于提高训练的稳定性。
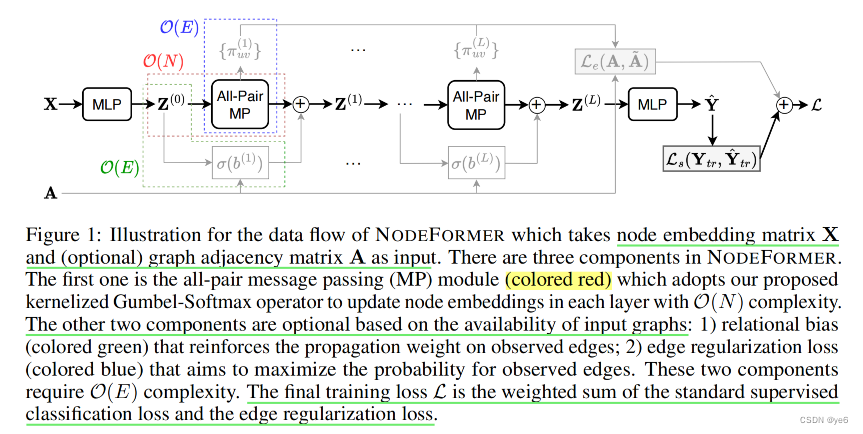
文章提出的NodeFormer架构:


















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









