






- 1、线性回归的简单介绍
- 2.安装第三方库
- 3、一元线性回归示例说明
- 4、多元线性回归示例
- 5.总结
1.线性回归的介绍
定义:线性回归是一种用于建立变量之间线性关系的统计模型,通过一个或多个自变量来预测一个因变量的值。
原理:其核心原理是最小二乘法,即通过寻找一条直线(在一元线性回归中)或一个超平面(在多元线性回归中),使得数据点到这条直线或超平面的距离的平方和最小。这条直线或超平面就是对数据的最佳拟合。
分类:
简单线性回归:只涉及一个自变量和一个因变量。
多元线性回归:涉及两个或更多自变量。
一元线性回归:只有一个自变量x和一个因变量y,其数学模型为y=β0+β1x+ϵ,其中β0是截距,β1是斜率,ϵ是误差项,代表了无法被线性关系解释的部分。
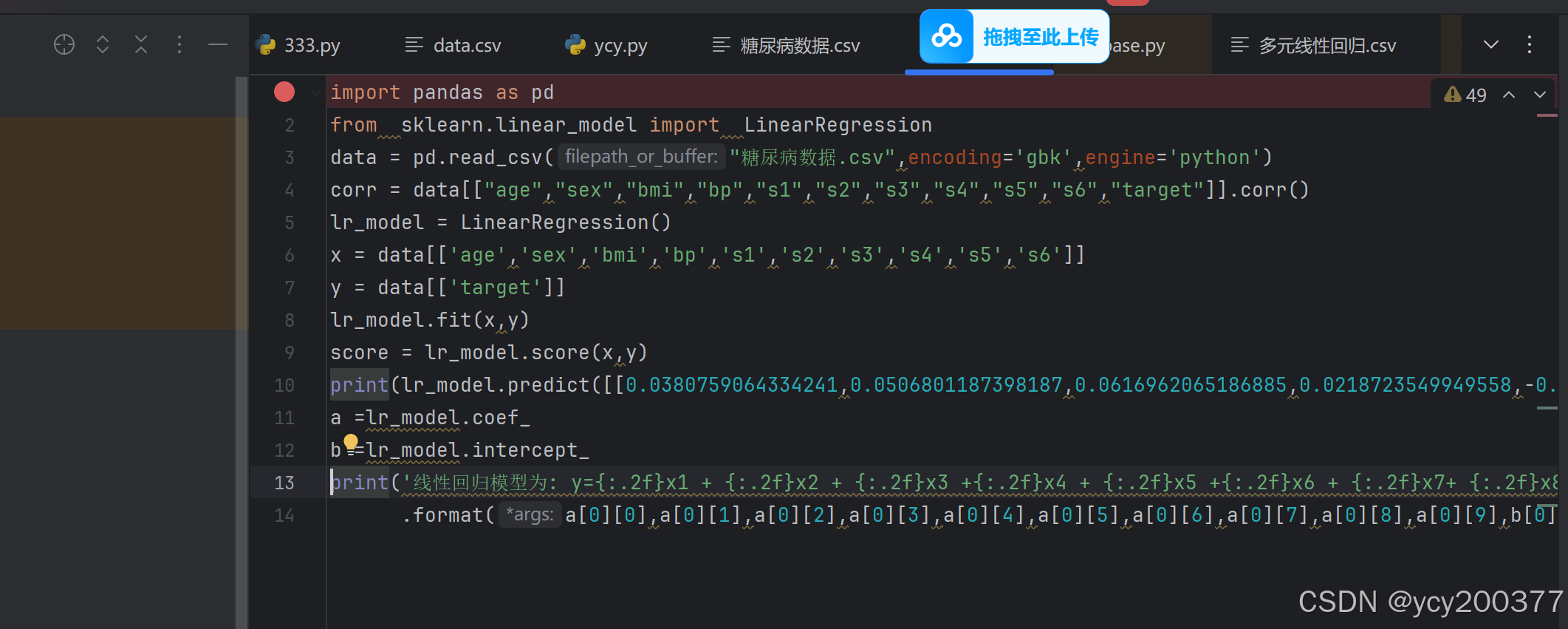
多元线性回归:有多个自变量x1,x2,⋯,xn和一个因变量y,数学模型为y=β0+β1x1+β2x2+⋯+βnxn+ϵ。其中,x 1 , x 2 , … , x n 是自变量,β 1 , β 2 , … , β n 是各自变量的系数.
2.安装第三方库
pandas库:pandas 库是 Python 中用于数据处理和分析的重要库,在进行线性回归分析中具有多方面的重要作用,主要体现在数据读取、清洗、预处理、特征工程以及结果展示等环节
matplotlib库:Matplotlib 是 Python 中一个强大的绘图库,在线性回归分析中发挥着至关重要的作用,主要体现在数据可视化展示、模型评估可视化、参数分析等方面
scikit-learn库:Scikit - learn 是 Python 中一个广泛使用的机器学习库,在线性回归任务中发挥着核心作用,涵盖了从模型构建、训练、评估到调优等多个关键环节。
以下是三个库的下载方式:
![]()


3.一元线性回归示例说明:
首先我们选取一组数据集:
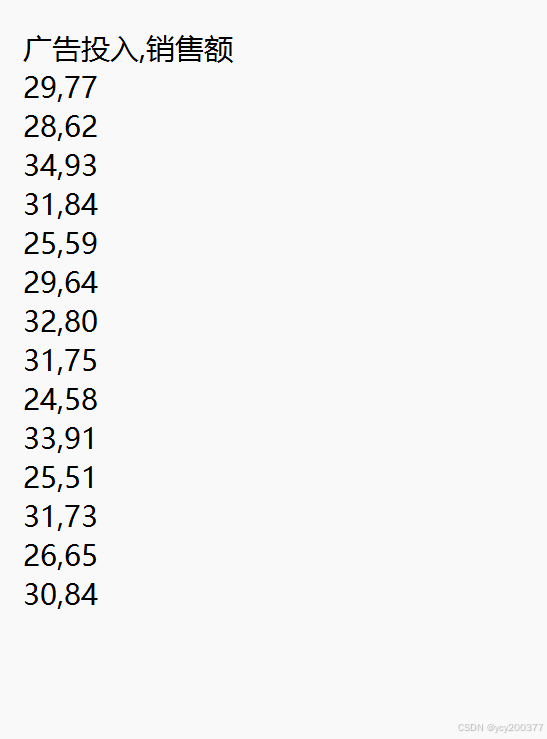
数据集的获取方式: https://pan.baidu.com/s/19ttoEaCsi462D6kLEIpQKg 提取码: bebt
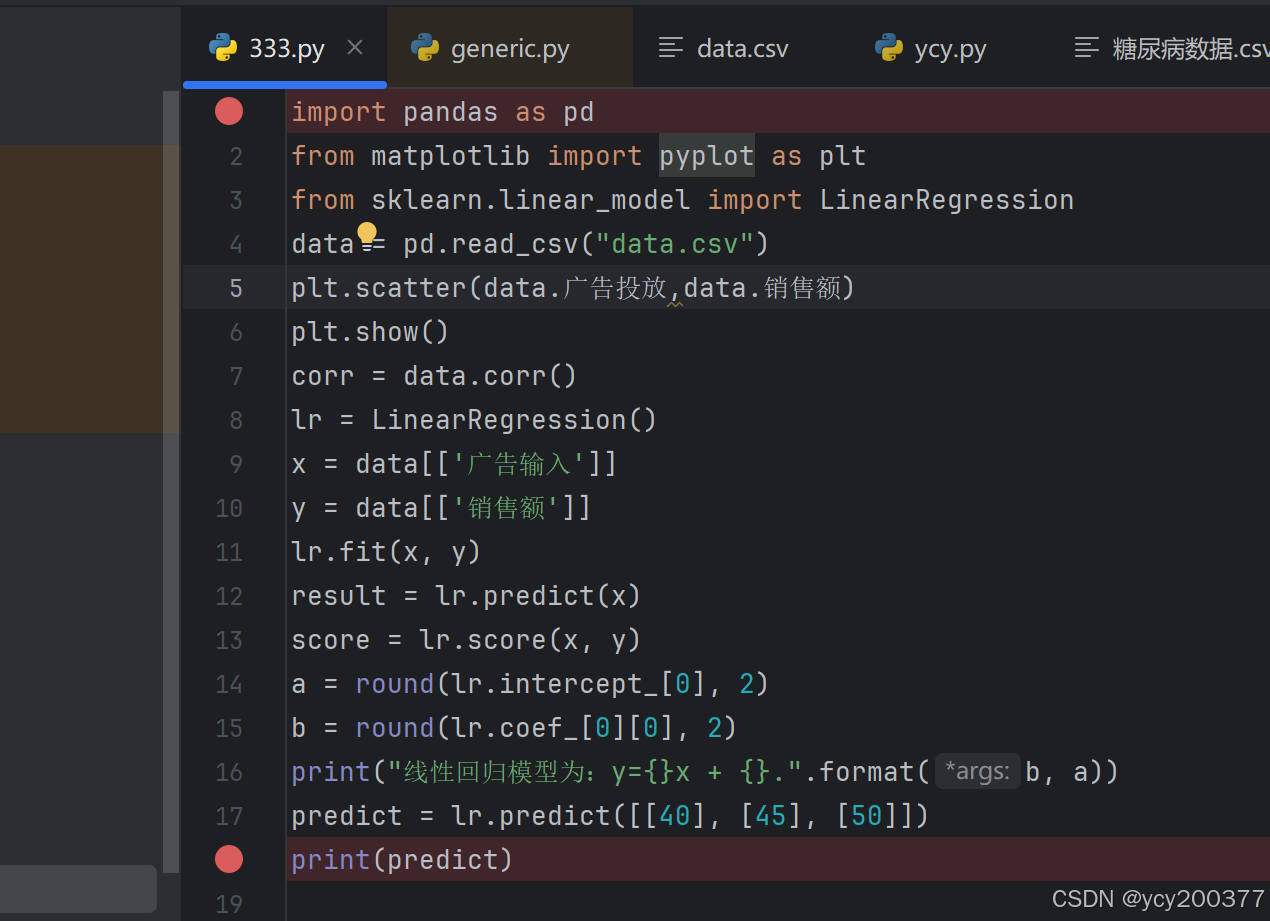
3.1 进行数据的读取:data = pandas.read_csv("data.csv")
3.2 绘制散点图:
plt.scatter(data.广告投放,data.销售额)
plt.show()
3.3 计算相关系数矩阵:
corr = data.corr()//corr方法计算数据集中各列之间的相关系数矩阵。相关系数矩阵可以帮助我们了解不同变量之间的线性相关程度,例如可以查看 广告投放 和 销售额 之间的相关性强弱。
3.4 创建线性回归模型实例并准备训练数据
lr = LinearRegression() x = data[['广告输入']] y = data[['销售额']] //这里使用双重方括号 [[]] 是为了确保 x 是一个二维的 DataFrame 对象,因为 scikit-learn 要求输入的特征矩阵是二维的。
3.5训练线性回归模型并进行预测:
lr.fit(x, y)
result = lr.predict(x)
3.6 计算模型得分并提取模型的截距和系数
score = lr.score(x, y)
a = round(lr.intercept_[0], 2)
b = round(lr.coef_[0][0], 2)//lr.coef_ 是线性回归模型的系数(斜率)
3.7打印线性回归模型方程对新数据进行预测
print("线性回归模型为:y={}x + {}.".format(b, a))
predict = lr.predict([[40], [45], [50]])
print(predict)
以下是过程实现的全部代码:
4.多元线性回归示例:
我们也传输一个数据集:
数据集的获取方式:链接: https://pan.baidu.com/s/1YAQwEUtX_i6ruengaV27yQ 提取码: ft3d
以下是操作的具体代码:
5.总结
线性回归的原理简单易懂,计算复杂度低、求解方便,可解释性强,能有效进行预测和趋势分析。但对数据分布有要求,需满足误差项正态分布等假设;只能处理线性关系,对非线性关系拟合效果差;易受异常值影响,可能导致参数估计偏差;多元线性回归中存在多重共线性问题,影响模型解释力和预测能力。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









